“Yeah It’s on. ”
大厂
字节跳动
宇宙条,面试要求极高,考察算法,会一直追问知道你答不出来为止
商业化一面
第一次面大厂 算法能力不足 挂了
基础
- css的position? css3新增加的position?absolute根据什么来进行布局?absolute根据父节点fixed布局可以吗?
- z-index是谁大就排在前面吗?z-index怎么比较?层叠上下文?
- 判断区分object和array的方法?用instanceof可以吗
- script标签异步加载? async和defer? async和defer的区别?哪一个快?defer具体执行的时间点 (一直深挖我擦)
- 缓存?强缓存和协商缓存?哪些请求头和缓存有关?如果已经缓存了一个文件再次访问这个文件流程?追问etag
- 状态码?200 301 302 304(重点说这个) 400 404 500 501 504
- http相关?他的特点
- udp/tcp 相同点 不同点? udp的应用场景 (直播 游戏)
- 箭头函数和普通函数的区别?箭头函数的this?bind,call这些可以改变箭头函数的this吗(不可以)
小程序
- 对diff的理解,你的diff是怎么样的?
- 你的长列表数据优化是怎样的?(缓存桶机制) 上w条数据的长列表该怎么办(recycleviewlist card 固定高度 三个屏幕的数据)?让你设计一个recycleview?
算法
第一题 字符串处理 (5-10 分钟)
123456 -> 123,456
12345678.123 -> 12,345,678.123
第二题 区间合并
给定一堆左右闭合的区间,要求对重叠的区间进行合并,返回合并后的区间段。
例如:[9, 10], [1,4], [3,6], [8, 12]
instanceof到底能不能区分Object和Array?
答案是可以的。
let obj = {
aaa: "aaa"
}
console.log(obj instanceof Object) // true
console.log(obj instanceof Array) // false
let obj = []
console.log(obj instanceof Object) // true
console.log(obj instanceof Array) // true
用 instanceof Array 来区分
async还是会阻塞渲染的 async与defer一样 下载不阻塞html解析 但async是js谁下载完谁就立即执行,会阻塞html解析,defer是html解析完成后才按顺序执行下载的js
互娱影像一面
- webpack 深挖 => webpack5 新特性 => webpack5 联邦模块? =》 这个是怎么实现的?
-
redux 和 mobx 的区别 =》 原理上有什么不一样 =》 redux 和 mobx 怎么实现数据的响应式 =》 Object.defineProxy 和 Proxy => Object.defineProxy 的局限性 => Proxy的局限性 => Proxy 有什么不好的地方
- 跨域 => JSONP 的局限性 => CORS 配置
- csrf 攻击 token怎么解决的 =》 cookie 不能跨域 =》 保证cookie的安全性 samesite
- 层叠上下文 =》 开发中有遇见层叠上下文的问题嘛
- 组件库的全局弹出窗组件怎么实现 (挂载到根节点 z-index++) => z-index增加的时机 (挂载时还是显示时)
- flex 和 grid 布局 =》 flex basic:1 代表什么意思
- babel 原理 =》babel-plugin-transform-runtime 和 babel-runtime 分别是用来做什么的 =》 babel 除了做js语法兼容你还能想到有别的玩法嘛 (创造新的语法)
手写题
实现一个Promise.all()
tip: 考虑arr里面非Promise的情况
a[s6[sd]cd21[ere]] => 展开
算法题目最重要的思路,要考虑边界,要覆盖所有case,其次才是bug free(这个不一定要做到)
function myPromiseAll(fns = []) {
if (fns.length == 0) {
// tip: 空数组直接返回
return Promise.resolve(fns);
}
let result = [];
let count = 0;
return new Promise((resolve, reject) => {
fns.forEach((item, index) => {
if (!(item instanceof Promise)) {
// tip: 转Promise
item = Promise.resolve(item);
}
item.then(
(res) => {
result[index] = res;
count++;
if (count == fns.length) {
return resolve(result);
}
},
(rej) => {
return reject(rej);
}
);
});
});
}
script crossorigin
https://juejin.cn/post/6969825311361859598
script标签去请求资源的时候,request是没有origin头的。script标签请求跨域资源的时候,内部运行如果报错的话,window.onerror捕获的时候,内部的error.message只能看到Script error.看不到完整的错误内容。这个应该是浏览器的安全策略。
设置 crossorigin属性后,script标签去请求资源的时候,request会带上origin头,然后会要求服务器进行 cors校验,跨域的时候如果response header 没有 ‘Access-Control-Allow-Origin’ 是不会拿到资源的。cors验证通过后,拿到的script运行内部报错的话,,window.onerror 捕获的时候,内部的error.message可以看到完整的错误信息。
Proxy 缺点
https://juejin.cn/post/6844903790739456013#heading-1
虽然 Proxy 可以代理针对目标对象的访问,但它不是目标对象的透明代理,即不做任何拦截的情况下,也无法保证与目标对象的行为一致
-
兼容性问题,而且无法用polyfill实现
-
this 指向的问题。在 Proxy 代理的情况下,目标对象内部的
this关键字会指向 Proxy 代理。
cookie 跨域
cookie 可以跨越一个域名下的多个网页,但不能跨越多个域名使用
domain 属性指定浏览器发出 HTTP 请求时,哪些域名要附带这个 Cookie。
可以设置 domain 为当前服务器域名或者父域名。如果未设置,则该 Cookie 值只能在发向该域名的请求时被携带。如果设置了 domain,则发向该域以及子域的请求都会带上该 Cookie。
在发送跨域 AJAX 请求时,Cookie 默认不会被发送。如果需要允许跨域请求携带 Cookie ,需要在发起请求的时候设置 withCredentials 请求头
跨域情况下的set-cookie:
- 前端设置with-credentials:true,后端即使不设置CORS头也可set-cookie成功
- 前端不设置with-credentials或者false,set-cookie响应头会被直接忽略
为 Cookie 服务的 HTTP 首部字段:
HTTP/1.1 200 OK
...
Set-Cookie: name=LvLin;domain=github.com;path=/blog
Set-Cookie: id=test123;
JSONP 的局限性
- 仅支持get请求;
- 具有局限性,不安全,可能会受到XSS攻击
- 只支持跨域 HTTP 请求这种情况,不能解决不同域的两个页面之间如何进行 调用的问题。
全局弹窗组件
PopupManager.nextZIndex 的相关逻辑
z-index增加的时机?
答案:是在现实前
// openModal 的时候zIndex已经准备好了
// 调用外面 会进行z-index++ 的操作
openModal: function(id, zIndex, dom, modalClass, modalFade)
// 函数内部 appendChild(modalDom) 显示dom
PopupManager
Object.defineProperty(PopupManager, 'zIndex', {
configurable: true,
get() {
if (!hasInitZIndex) {
zIndex = zIndex || (Vue.prototype.$ELEMENT || {}).zIndex || 2000;
hasInitZIndex = true;
}
return zIndex;
},
set(value) {
zIndex = value;
}
});
互娱影像二面
- 主要是针对简历上的东西深入去挖
- 从工程化的角度怎么保证代码质量 => 前端规范可以做哪些事情
- m3u8播放器 (这块答得不是很好 m3u8文件为什么不能自动update ) =》 双播放器方案会不会有性能上面的问题
- commonjs可以tree-shaking吗?=> side-effect 和 tree-shaking 的关系
- webpack做过哪些东西
- sdk的分层架构设计
- mobx 和 redux 的区别
- 怎么样写一个高质量的sdk
- log 怎么上报的 => 怎么分析定位error
手写题:
// 控制并发
maxRequest(fns,max)
- 二叉树蛇形打印
commonjs可以tree-shaking吗?
CommonJS 本身并不支持树摇(tree-shaking),。
互娱影像三面
- 吹水
- 项目介绍 项目成长 个人经历 个人成长 个人规划
- 视频聊天的延时 (300ms以内)
- 推拉流 => rtmp => ios 的推拉流的坑
国际化电商加面
影像团队offer没审批下来 只能转到国际化电商团队加面一轮
- 吹水
- 你看中的三个能力 (技术之外的)
- 项目介绍 项目成长 个人经历 个人成长 个人规划。。。
手写题
// 重试机制
function retry(fn, num, interval) {
// todo
}
// ------------ test -----------------------
const request = (url) => {
return fetch(url);
};
const myRetry = retry(request, 5, 1000);
myRetry("https://api.github.com/users").then(
(res) => {
console.log("res", res);
},
(rej) => {
console.log("rej", rej);
}
);
function retry(fn, num, interval) {
// transform fn to Promise
return (...args) => {
return new Promise((resolve, reject) => {
const _retry = (info, num) => {
if (!num) {
return reject(info);
}
setTimeout(() => {
fn(...args).then(
(res) => resolve(res),
(rej) => _retry(rej, --num)
);
}, interval);
};
return fn(...args).then(
(res) => resolve(res),
(rej) => {
_retry(rej, --num);
}
);
});
};
}
抖音一面
- 狂问项目。项目架构,项目难点,项目优化
- web worker 会跨域吗? 如果要传递很大数据怎么办? (Web Worker 提供了一种转移数据的方式Transferable,允许主线程把二进制数据直接转移给子线程) (可以尝试 SharedArrayBuffer SharedWorker)
- 前端性能指标。fcp。。。 谁制定的?google
- 前端跨项目模块之间应用。pnpm 和 webpack5 联邦模块。
- webpack5 联邦模块实现原理?
- pnpm的优势?对比yarn
- pnpm的link原理? (两种link 忘了 system还是file link hard link)
- webpack怎么实现tree-shaking的。tree-shaking的过程讲一下
- es新语法。symbol用过没?Reflect用来干嘛的?
- 装饰器用过没?装饰器用来干嘛
- es新语法提案 几个阶段?stage-[1-3]
- ts编译。tsc 和 babel结合ts-loader 的区别?
- koa洋葱模型中间件机制怎么实现的? (形成一条Promise链)
- 讲一下浏览器的事件循环?node事件循环和浏览器事件循环是否一样?
- 说一下你实现的插件机制?有没有了解过依赖反转IOC方式去实现插件?
- class命名冲突怎么解决?css样式隔离怎么做?
- 暗夜模式怎么实现的?怎么实现多主题切换?
Web Worker 脚本加载与跨域:
- 默认情况下,Web Worker 加载的脚本文件 必须来自与主页面相同的源(即同一个协议、主机和端口)。如果试图加载跨域的 Worker 脚本,浏览器会阻止并抛出错误。
- 如果你想加载跨域的 Worker 脚本,你可以通过设置 CORS(跨域资源共享) 头来允许跨域访问。例如,服务器可以在响应中添加适当的
Access-Control-Allow-Origin头,从而允许特定域的请求。
Transferable object
https://developer.mozilla.org/zh-CN/docs/Web/API/Web_Workers_API/Transferable_objects
手写题:
找到数组中连续的子数组使得其值最大,输出最大值
[1,2,5,-7,8] => 9
function findMax(arr = []) {
if (!arr.length) {
return 0
}
let dp = new Array(arr.length).fill(0)
// dp[i] 表示以 arr[i] 结尾的最大子序列和
dp[0] = arr[0]
for (let i = 1;i < arr.length;i++) {
dp[i] = dp[i - 1] > 0 ? dp[i - 1] + arr[i] : arr[i]
}
let max = dp[0]
for (let i = 1;i < dp.length;i++) {
max = Math.max(max, dp[i])
}
return max
}
web worker
详情请查看js基础blog
node事件循环
详情请查看node相关blog
多主题样式
- css var变量
- 在元素
:active时,叠加了一个透明遮罩层上去 - 基于媒体查询
prefers-color-scheme的结果为dark时(即系统开启了暗夜模式时),来决定是否采用暗夜模式下的样式。
toggle 日间模式与暗夜模式
// 以下代码兼容了随系统切换和让用户主动切换日间、暗夜模式的功能
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
if (localStorage.theme === 'dark' || (!('theme' in localStorage) && window.matchMedia('(prefers-color-scheme: dark)').matches)) {
document.documentElement.classList.add('dark')
} else {
document.documentElement.classList.remove('dark')
}
// Whenever the user explicitly chooses light mode
localStorage.theme = 'light'
// Whenever the user explicitly chooses dark mode
localStorage.theme = 'dark'
// Whenever the user explicitly chooses to respect the OS preference
localStorage.removeItem('theme')
抖音二面
- react 的diff算法具体讲一讲?(单节点 和 多节点的diff) (同级的
Fiber节点是由sibling指针链接形成,无法使用双指针优化) (Diff算法的整体逻辑会经历两轮遍历:第一轮遍历:处理更新的节点。第二轮遍历:处理剩下的不属于更新的节点。) - diff时间复杂度?O(n)
- 讲一下react的fiber架构?
- 讲一下https 三次握手?什么时候对称加密什么时候非对称加密
- redux 和 mobx 的差别
- 如何实现一个低代码平台?(拖拽组件…)
- 低代码平台有哪些难点?(协议的制定)
- 你做过项目中的一些难点。
手写题:
-
之字型打印二叉树
-
异步输出题? process.nextTrick 怎么实现的
function printf(node) {
let res = []
let queue = []
queue.push(node)
while (queue.length) {
let curArr = []
let curLen = queue.length
for (let i = 0;i < curLen;i++) {
let cur = queue.shift()
curArr.push(cur.val)
if (cur.left) queue.push(cur.left)
if (cur.right) queue.push(cur.right)
}
res.push(curArr)
}
for (let i = 0;i < res.length;i++) {
if (i % 2 == 1) {
res[i] = res[i].reverse()
}
}
return res.flat()
}
测试:
// 1
// /\
// 2 3
// /\ /\
// 4 5 6 7
//
// [1,3,2,4,5,6,7]
class TreeNode {
constructor(val) {
this.val = val;
this.left = null;
this.right = null;
}
}
const node = new TreeNode(1)
node.left = new TreeNode(2)
node.right = new TreeNode(3)
node.left.left = new TreeNode(4)
node.left.right = new TreeNode(5)
node.right.left = new TreeNode(6)
node.right.right = new TreeNode(7)
const res = printf(node)
console.log(res)
剪映一面
-
xmlHttpRequest 和 fetch 的差异
- h5 和移动端通信 除了url schema 还有别的方式吗?(注入全局api) 怎么改变url => 通过 iframe
- fiber是什么? fiber tree怎么更新的?
- virtual dom 介绍一下?有哪些优势? virtual dom 在服务器的应用 => ssr
- ssr介绍一下?ssr的好处
- webpack loader 和 plugin 的差别
- xss 在服务器可以怎么预防攻击?
- 协商缓存 和 强缓存? 和他们相关的 response header
- 介绍一下前端模块化规范?es module 和 commonjs的区别?介绍一下umd?
- 判断元素是否在可见区域?
xmlHttpRequest 和 fetch
https://zh.javascript.info/fetch-progress
- XHR 基于事件机制实现请求成功与失败的回调,Fetch 通过 Promise 来实现回调
- XHR中断请求的方式 (abort api) 和 Fetch (AbortController)
- XHR 监控请求进度(progress),fetch允许去跟踪下载进度,无法跟踪上传进度
1)下载的progress事件属于XMLHttpRequest对象
2)上传的progress事件属于XMLHttpRequest.upload对象。
// 下载
var xhr = new XMLHttpRequest();
xhr.open('GET', 'https://example.com');
xhr.onprogress = function(event) {
if (event.lengthComputable) {
var percentComplete = event.loaded / event.total * 100;
console.log(percentComplete + '% downloaded');
} else {
console.log('Download in progress');
}
};
xhr.send();
缓存
强缓存 header: Cache-Control 和 Expires (都是服务器返回的)
协商缓存 header:Last-Modifed/If-Modified-Since Etag/If-None-Match
Last-Modifed 和 Etag 是服务器返回的
判断元素是否在可见区域
- offsetTop、scrollTop
- getBoundingClientRect
- Intersection Observer
el.offsetTop - document.documentElement.scrollTop <= viewPortHeight
// viewPortHeight = window.innerHeight;
// 元素距离顶部的距离 - 文档滚动的距离 <= 屏幕的高度
xss攻击在服务器上预防
-
安全的Cookie:确保Cookie只能由服务器端访问,并且不包含敏感信息。 (HTTP-only)
-
HTTPS协议:使用HTTPS协议加密数据传输,以防止中间人攻击和窃听。
-
Content Security Policy
严格的 CSP 在 XSS 的防范中可以起到以下的作用:
- 禁止加载外域代码,防止复杂的攻击逻辑。
- 禁止外域提交,网站被攻击后,用户的数据不会泄露到外域。
- 禁止内联脚本执行(规则较严格,目前发现 GitHub 使用)。
- 禁止未授权的脚本执行(新特性,Google Map 移动版在使用)。
- 合理使用上报可以及时发现 XSS,利于尽快修复问题。
输出题
var a = 3
// 自执行函数作用域是window
!(function () {
// a 会提升
console.log(a) // undefined
console.log(window.a) // 3
var a = 5
console.log(a) // 5
})()
手写题
- 版本号比较大小
function swap(arr, i, j) {
let temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
function isBigger(item1, item2) {
const arr1 = item1.split(".")
const arr2 = item2.split(".")
for (let i = 0;i < arr1.length;i++) {
// 分割字符串转number进行比较
// 注意:Number(undefined) => NaN (要避免这种情况 加上 || 0 )
const num1 = Number(arr1[i] || 0)
const num2 = Number(arr2[i] || 0)
if (num1 > num2) {
return true
} else if (num1 < num2) {
return false
}
}
return false
}
function compare(arr) {
for (i = 0;i < arr.length;i++) {
for (let j = i + 1;j < arr.length;j++) {
if (isBigger(arr[i], arr[j])) {
swap(arr, i, j)
}
}
}
}
// 测试
let arr = ["1.45", "1.5", "3.3.3.3", "6", "4.4", "6.1"]
compare(arr)
console.log(arr)
- 跳阶梯 (优化)
let map = new Map() // 用于剪枝
function dp(n) {
if (n == 1) {
return 1
}
if (n == 2) {
return 2
}
if (map.has(n)) {
return map.get(n)
}
let num = dp(n - 1) + dp(n - 2)
map.set(n, num)
return num
}
剪映二面
- 主要问项目(架构,难点,优化)
- 单元测试怎么mock函数 (a.js import b.js 对a文件做单元测试怎么模拟b中的函数)
- fps是什么?怎么监控fps?
- webassembly怎么使用?
- long task是什么?怎么捕获long task
long task
任何连续不间断的且主 UI 线程繁忙 50 毫秒及以上的时间区间
https://developer.mozilla.org/zh-CN/docs/Web/API/PerformanceLongTaskTiming
var observer = new PerformanceObserver(function (list) {
var perfEntries = list.getEntries();
for (var i = 0; i < perfEntries.length; i++) {
// Process long task notifications:
// report back for analytics and monitoring
// ...
}
});
// register observer for long task notifications
observer.observe({ entryTypes: ["longtask"] });
// Long script execution after this will result in queueing
// and receiving "longtask" entries in the observer.
webassembly使用
const importObject = {
imports: {
imported_func: (arg) => console.log("I was imported. " + arg)
}
}
fetch("http://localhost:3000/audiotest/test/simple.wasm").then(res => {
console.log("res", res)
return res.arrayBuffer()
}).then(bytes => {
console.log("bytes", bytes)
return WebAssembly.instantiate(bytes, importObject)
}).then(result => {
console.log("result", result)
result.instance.exports.exported_func(111)
})
fps 相关
参考 stats.js
JavaScript Performance Monitor
var stats = new Stats();
stats.showPanel( 1 ); // 0: fps, 1: ms, 2: mb, 3+: custom
document.body.appendChild( stats.dom );
function animate() {
stats.begin();
// monitored code goes here
// 中间就是动画执行,每次就是一个frame
stats.end();
requestAnimationFrame( animate );
}
requestAnimationFrame( animate );
内部实现原理:
begin: function () {
beginTime = (performance || Date).now();
},
end: function () {
frames++;
var time = (performance || Date).now();
if (time >= prevTime + 1000) {
// 一秒钟多少帧
const num = (frames * 1000) / (time - prevTime)
fpsPanel.update(num, 100);
prevTime = time;
frames = 0;
}
return time;
},
简化例子:
var frame = 0;
var lastTime = Date.now();
var loop = function () {
var now = Date.now();
frame++;
if (now > 1000 + lastTime) {
var fps = Math.round((frame * 1000) / (now - lastTime));
console.log(`${new Date()} 1S内 FPS:`, fps);
frame = 0;
lastTime = now;
};
requestAnimationFrame(loop);
}
loop();
memory 相关
https://developer.mozilla.org/zh-CN/docs/Web/API/Performance/memory
- jsHeapSizeLimit
上下文内可用堆的最大体积,以字节计算。
- totalJSHeapSize
已分配的堆体积,以字节计算。
- usedJSHeapSize
当前 JS 堆活跃段(segment)的体积,以字节计算。
例子:
获取已使用的Memory
// 1MB would be 1048576 bytes
const memory = performance.memory;
const used = memory.usedJSHeapSize / 1048576
const total = memory.jsHeapSizeLimit / 1048576
console.log("Memory used: " + used + "MB")
console.log("Memory total: " + total + "MB")
console.log("Memory used: " + (used / total * 100) + "%")
手写题
顺时针螺旋顺序输出组件:
输入:
[
[ 1, 2, 3 ],
[ 4, 5, 6 ],
[ 7, 8, 9 ]
]
输出: [1,2,3,6,9,8,7,4,5]
解决:
const directions = [
[0, 1], // right
[1, 0], // down
[0, -1], // left
[-1, 0] // up
]
function print(grid) {
let visited = new Array(grid.length)
for (let i = 0;i < visited.length;i++) {
visited[i] = new Array(grid[i].length).fill(false)
}
let row = grid.length // 行
let col = grid[0].length // 列
let max = row * col
let curIndex = 0
let curPos = [0, 0]
let direction = 0
const print = (curPos) => {
console.log(grid[curPos[0]][curPos[1]])
}
isLegalPos = (pos) => {
if (pos[0] >= 0 && pos[0] < row && pos[1] >= 0 && pos[1] < col) {
if (!visited[pos[0]][pos[1]]) {
return true
}
}
return false
}
while (curIndex < max) {
print(curPos)
curIndex++
visited[curPos[0]][curPos[1]] = true
let nextPos = [curPos[0] + directions[direction][0], curPos[1] + directions[direction][1]]
if (!isLegalPos(nextPos)) {
// 不合法的位置,换方向
direction = (direction + 1) % 4
nextPos = [curPos[0] + directions[direction][0], curPos[1] + directions[direction][1]]
}
curPos = nextPos
}
}
抖音中台二面
- node 读取文件的最大值
- electron 打包这么大怎么办
- 小程序渲染 (基于 WebView 和原生控件混合渲染的方式) (目前原生组件均已支持同层渲染,建议使用 image 替代cover-image ) (通过一定的技术手段把「原生组件」直接渲染到
WebView层级上,) - 爬虫遇见白屏怎么办? (使用puppeteer)
- js bridge
- long task
跳出研发的角度看事情
火山引擎一面
基础:
- 聊简历项目
-
mobx的实现原理? mobx-react 的实现原理?
- 在一个c端场景,客户反馈说页面出现卡顿怎么定位到? (通过打点上报log分析时间戳)
- 比new Date() 精度更细的获取时间的方法
算法:
写一个装饰器记录类函数的执行时间。 (注意区分同步/异步函数 cnotext)
实现:
const run = (target, name, descriptor) => {
const originalMethod = descriptor.value; // 保存原始方法
descriptor.value = function (...args) {
let startTime = Date.now();
// 调用原始方法 注意this指向
const res = originalMethod.apply(this, args);
if (res instanceof Promise) {
res.then(() => {
let endTime = Date.now();
console.log('end', endTime - startTime);
}).catch(() => {
let endTime = Date.now();
console.log('end', endTime - startTime);
})
} else {
let endTime = Date.now();
console.log('end', endTime - startTime);
}
return res
};
return descriptor
}
测试:
class Test {
@run
async task() {
await sleep()
console.log('task')
}
}
let t = new Test()
t.task()
给一个number数组,输出数组每一项的非自己乘积 (时间复杂度n(O) 且不能使用除法)
例子:
input = [1,2,3,4]
output = [24,12,8,6]
解决:
function test(arr = []) {
let total = 1
let res = []
for (let i = 0;i < arr.length;i++) {
total = total * arr[i]
}
for (let i = 0;i < arr.length;i++) {
// 题目规定不能用除法
// 非自己的所有元素乘积 => 当前元素的所有左边元素乘积 * 当前元素的所有右边元素乘积
res[i] = total / arr[i]
}
return res
}
优化:
function test(arr = []) {
let res = []
let left = [] // 元素左边乘积
let right = [] // 元素右边乘积
left[0] = 1
right[arr.length - 1] = 1
for (let i = 1;i < arr.length;i++) {
left[i] = left[i - 1] * arr[i - 1]
}
for (let i = arr.length - 2;i >= 0;i--) {
right[i] = right[i + 1] * arr[i + 1]
}
for (let i = 0;i < arr.length;i++) {
res[i] = left[i] * right[i]
}
return res
}
react 题目
function App() {
const [num, setNum] = useState(0)
useEffect(() => {
setInterval(() => {
setNum(pre => pre + 1)
}, 1000)
}, [])
const onClick = useCallback(() => {
// 这里的输出是多少 => 0
// 为什么useCallback能做到缓存这个num不改变,底层是怎么实现的?=> 闭包作用域
console.log(num)
}, [])
return <div onClick={onClick}>test</div>
}
function App() {
const [num, setNum] = useState(0)
useEffect(() => {
setInterval(() => {
setNum(pre => pre + 1)
}, 1000)
}, [])
const onClick = () => {
// 也是0
// useMemo 和 useCallback 都是用来缓存
// useMemo 缓存后TestEle就不会重新渲染了 onClick一直是最开始的那个 => 指向的num就是0
console.log(num)
}
const TestEle = useMemo(() => <div onClick={onClick}>test</div>, [])
return <div>
{TestEle}
</div>
}
阿里
面试官会对着一个问题不断深挖,促使你不断地优化你回答的方案
盒马hr最多接受三年两跳,遂只能中止盒马的面试流程,没有达到最后一面,GG (据了解不同团队的hr要求不一样 别的团队并没有这个限制)
盒马一面(笔试)
两道笔试题,一小时内完成
经典dfs搜索的题目,忘记记录已经走过的路径导致死循环
// 给定一个包含了一些 0 和 1 的非空二维数组 grid
//
// 一个 岛屿 是由一些相邻的 1(代表土地)构成的组合,这里的「相邻」要求两个 1 必须在水平或者竖直方向上相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着
//
// 给定两个位置,判断这两个位置否在同一个岛屿上
const direction = [
[0, 1],
[1, 0],
[-1, 0],
[0, -1],
]
let flag = false
function isSameIsland(grid, row1, col1, row2, col2) {
if (!grid[row1][col1] || !grid[row2][col2]) {
return false
}
let target = [row2, col2]
// 记录已经找过的路径 不然会死循环
let marked = new Array(grid.length)
for (let i = 0; i < grid.length; i++) {
marked[i] = new Array(grid[0].length).fill(false)
}
marked[row1][col1] = true
for (let i = 0; i < direction.length; i++) {
// 四个方向出发 深度搜索
let next = [row1 + direction[i][0], col1 + direction[i][1]]
if (isInGrid(grid, next)) {
dfs(grid, next, target, marked)
}
}
let result = flag
flag = false
return result
}
function dfs(grid, cur, target, marked) {
if (!grid[cur[0]][cur[1]]) {
// 不是岛屿
return false
}
if (marked[cur[0]][cur[1]]) {
// 该点已经走过
return false
}
marked[cur[0]][cur[1]] = true
let [x, y] = cur
let [targetX, targetY] = target
if (x == targetX && y == targetY) {
flag = true
return true
}
for (let i = 0; i < direction.length; i++) {
let next = [x + direction[i][0], y + direction[i][1]]
if (isInGrid(grid, next)) {
dfs(grid, next, target, marked)
}
}
}
function isInGrid(grid, cur) {
let [x, y] = cur
if (x < 0 || y < 0 || x >= grid.length || y >= grid[0].length) {
return false
}
return true
}
const grid1 = [
[0, 0, 1, 0, 0, 0, 0, 1, 0], // row=0
[0, 0, 1, 0, 0, 1, 0, 1, 1], // row=1
[1, 1, 1, 1, 1, 1, 1, 0, 1], // row=2
]
let res1 = isSameIsland(grid1, 0, 2, 1, 5) // 返回 true
let res2 = isSameIsland(grid1, 0, 7, 2, 5) // 返回 false (注意 grid1 中 (1,7) 和 (2,6) 不算相邻)
console.log(res1)
console.log(res2)
tip: 也可以不用flag dfs返回true 就是最终的true
这道题可以变形为查找地图中一共有多少个岛屿
// 给定一个包含了一些 0 和 1 的非空二维数组 grid
// 一个 岛屿 是由一些相邻的 1(代表土地)构成的组合,这里的「相邻」要求两个 1 必须在水平或者竖直方向上相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着
// 判断有多少个岛屿
const direction = [
[0, 1],
[1, 0],
[-1, 0],
[0, -1],
]
function getIsland(grid) {
if (!grid || !grid.length || !grid[0].length) {
return 0
}
let total = 0
let marked = new Array(grid.length)
for (let i = 0; i < marked.length; i++) {
marked[i] = new Array(grid[0].length).fill(false)
}
for (let x = 0; x < grid.length; x++) {
for (let y = 0; y < grid[0].length; y++) {
if (isInIsland(grid, x, y)) {
dfs(grid, x, y, marked)
total++
}
}
}
return total
}
function dfs(grid, x, y,marked) {
if (!isInGrid(grid, x, y)) {
// 不在地图中
return
}
if (marked[x][y]) {
// 已经来过了
return
}
if (!grid[x][y]) {
// 不是岛屿
return
}
// 标记来过
marked[x][y] = true // marked 其实不是必须的
// 标记为水
grid[x][y] = 0
for (let i = 0; i < direction.length; i++) {
dfs(grid, x + direction[i][0], y + direction[i][1],marked)
}
}
// 在岛屿中
function isInIsland(grid, x, y) {
return !!grid[x][y]
}
// 在地图中
function isInGrid(grid, x, y) {
if (x < 0 || y < 0 || x >= grid.length || y >= grid[0].length) {
return false
}
return true
}
const grid1 = [
[1, 0, 1, 0, 0, 0, 0, 1, 0], // row=0
[0, 0, 1, 0, 0, 1, 0, 1, 1], // row=1
[1, 1, 1, 1, 1, 1, 1, 0, 1], // row=2
]
let res1 = getIsland(grid1) // 3
console.log(res1)
实现对函数执行的流程控制
// 请实现以下的 LazyArray ,使下列的代码调用正确
function promiseFy(fn, num = 500) {
return new Promise((resolve, reject) => {
setTimeout(() => {
let res = fn()
resolve(resizeBy)
}, num)
})
}
class LazyArray {
// YOUR CODE HERE
// 你需要实现以下方法: map / filter / delay / forEach
constructor(arr) {
this.arr = arr
this.taskList = []
this.num = null
}
filter(fn) {
let finalFn = () => {
this.arr = this.arr.filter(fn)
return null
}
this.taskList.push(finalFn)
return this
}
map(fn) {
for (let i = 0; i < this.arr.length; i++) {
let finalFn = () => {
let item = this.arr[i]
if (item !== null && item !== undefined && !isNaN(item)) {
this.arr[i] = fn(item)
return this.arr[i]
}
}
this.taskList.push(finalFn)
}
return this
}
async forEach(fn) {
while (this.taskList.length) {
let task = this.taskList.shift()
let res = task()
if (res !== null && res !== undefined && !isNaN(res)) {
if (this.num) {
// 存在延时
await promiseFy(() => fn(res), this.num)
} else {
fn(res)
}
}
}
return this
}
delay(num) {
this.num = num
return this
}
}
const lazy1 = new LazyArray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
const lazy2 = lazy1
.filter((v) => v % 2 === 0)
.map((v) => {
console.log(`map ${v} to ${v * 5}`)
return v * 5
})
// 上一条语句执行时,不进行任何输出
// lazy2.forEach((v) => {
// console.log('consume lazy2', v)
// })
// 上一条语句执行时,输出以下内容:
// map 0 to 0
// consume lazy2 0
// map 2 to 10
// consume lazy2 10
// ......
// 进阶题目:
const lazy3 = lazy2.delay(500)
lazy3.forEach((v) => {
console.log('consume lazy3', v)
})
// 上一条语句执行时,不会立刻产生「consume lazy3 ...」这样的输出
// 所有「consume lazy3 ...」这样的输出将在 500 毫秒之后产生
这里可以关注一下this的指向
举个例子:
await promiseFy.call(this,()=>{
// 我们使用某种手段使得
// 此处的this是指向LazyArray实例
fn.call(this,res)
}, this.num)
结果:
const lazy3 = lazy2.delay(500)
lazy3.forEach((v) => {
// 这里的this仍然是指向window 因为箭头函数本身并没有this
// 不可以用bind call apply改变this
console.log('consume lazy3', v)
})
盒马二面 (电话 同事面)
40分钟左右
介绍 项目 和 做过最难的东西等
- git rebase 和 git merge
- npm包每个数字代表什么意思 (xx.xxx.xx) (如何发包)
- 你项目的依赖库是写死的还是动态版本?(写死的版本号真的是固定的吗?) 如何保证依赖库不出错? (npm的知识 package-lock.json)
- 实现一个深拷贝 (对date Regex的处理 set解决循环引用)
- JSON.parse(JSON.stringify(obj))实现深拷贝的问题?如让 JSON.parse(JSON.stringify(obj))深拷贝循环引用不报错?
- 判断一个函数是不是async函数
- 判断一个对象是不是数组
- 判断一个对象是不是函数
- node stream的特点 最大的优势
- node 是单线程 如何利用多核cpu的优势?(cluster fork 主进程 和 工作进程)
- 主进程和子进程会共享一个端口,这是怎么做到的?(追问?IPC?父子通信?)
- 工程化做过哪些东西?对webpack的理解。
- promise.then(res=>{},rej=>{}).catch(err=>{}) 这里catch方式捕获错误和 rej捕获错误的区别是?
考察的问题都比较有代表性,下面探究一些没有答出来的问题。
深拷贝循环引用不报错
让 JSON.parse(JSON.stringify(obj))深拷贝循环引用不报错
const obj = {
foo: {
name: 'foo',
bar: {
name: 'bar',
baz: {
name: 'baz',
aChild: null, //待会让它指向obj.foo
},
},
},
}
obj.foo.bar.baz.aChild = obj.foo
// foo->bar->baz->aChild->foo 形成环
// TypeError: cyclic object value
// let res = JSON.parse(JSON.stringify(obj))
// https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/JSON/stringify
// https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/JSON/parse
// 解决:
const seen = []
let res = JSON.parse(
JSON.stringify(obj, (key, value) => {
if (typeof value === 'object' && value !== null) {
if (seen.indexOf(value) !== -1) {
// 已存在 变为空指针
return null
}
seen.push(value);
}
return value
})
)
console.log(res)
利用JSON.stringify函数的第二个参数replacer
replacer 可选
如果该参数是一个函数,则在序列化过程中,被序列化的值的每个属性都会经过该函数的转换和处理;如果该参数是一个数组,则只有包含在这个数组中的属性名才会被序列化到最终的 JSON 字符串中;如果该参数为 null 或者未提供,则对象所有的属性都会被序列化。
Promise.catch的优势
https://www.css3.io/promise-catch-vs-reject.html
.catch()的作用是捕获Promise的错误,与then()的rejected回调作用几乎一致。
但是由于Promise的抛错具有冒泡性质,能够不断传递,这样就能够在下一个catch()中统一处理这些错误。同时catch()也能够捕获then()中抛出的错误,所以建议不要使用then()的rejected回调,而是统一使用catch()来处理错误
还有一个区别:throw不能用于异步调用中
如下代码所示,catch回调是不执行的
var p1 = new Promise(function(resolve, reject) {
setTimeout(function() {
throw 'Uncaught Exception!';
}, 1000);
});
p1.catch(function(e) {
console.log(e); // This is never called
});
而reject回调是执行的
var p2 = new Promise(function(resolve, reject) {
setTimeout(function() {
reject('oh, no!');
}, 1000);
});
p2.catch(function(e) {
console.log(e); // "oh, no!"
})
举个例子: Promise.catch then中的错误
var p2 = new Promise(function (resolve, reject) {
resolve(111)
});
p2.then(res => {
console.log("res", res)
throw '111'
}, rej => {
console.log("rej", rej)
throw '222'
}).catch(function (e) {
console.log(e); // "111" // 成功捕获
})
如果catch不跟在then后面,无法捕获then中抛出的错误
var p2 = new Promise(function (resolve, reject) {
resolve(111)
});
p2.then(res => {
console.log("res", res)
throw 'oh, no!'
}, rej => {
console.log("rej", rej)
throw 'oh, no!'
})
p2.catch(function (e) {
console.log('11111',e); // 无法捕获
})
.catch 不必是立即的。它可能在一个或多个 .then 之后出现。
pacakge写死的版本号真的是固定的吗
假如我们依赖roadhog,roadhog又依赖模块A、B等,我们安装roadhog时,npm会自动帮我们安装好roadhog依赖的模块A、B等。我们把roadhog锁死了,但是其引用的A模块仍用的是^括号写法(即没有锁死版本),所以假如A模块更新了,仍可能会出现问题
所以我们要对整个依赖树做锁定,那前后编译出来的应用版本就不会存在两次安装版本不一的问题了。
这就引出了我们的 package-lock.json 文件。它的产生就是来对整个依赖树进行版本固定的(锁死)
判断async函数
async function test() {
// ...
}
let name = test.constructor.name
console.log(test.constructor.name) // AsyncFunction
async function test() {
// ...
}
const name = Object.prototype.toString.call(test)
console.log(name) // [object AsyncFunction]
node stream
流(stream)是 Node.js 中处理流式数据的抽象接口。 stream 模块用于构建实现了流接口的对象。
流可以是可读的、可写的、或者可读可写的。 所有的流都是 EventEmitter 的实例。
与其他数据处理方法相比,流有两个主要优势:
- 内存效率: 不需要加载大量的数据到内存就可以处理
- 时间效率: 一旦有了数据就开始处理,而不必等待传输完所有数据
流是一种处理读写文件、网络通信或任何端到端信息交换的有效方式。
stream API 的主要目标,特别是 stream.pipe(),是为了限制数据的缓冲到可接受的程度,也就是读写速度不一致的源头与目的地不会压垮内存。
举个例子:
const server = http.createServer(function (req, res) {
const fileName = path.resolve(__dirname, 'data.txt');
fs.readFile(fileName, function (err, data) {
res.end(data);
});
});
server.listen(8000);
使用文件读取这段代码语法上并没有什么问题,但是如果data.txt文件非常大的话,到了几百M,在响应大量用户并发请求的时候,程序可能会消耗大量的内存,这样可能造成用户连接缓慢的问题。而且并发请求过大的话,服务器内存开销也会很大。这时候我们来看一下用stream实现。
const server = http.createServer(function (req, res) {
const fileName = path.resolve(__dirname, 'data.txt');
let stream = fs.createReadStream(fileName); // 这一行有改动
stream.pipe(res); // 这一行有改动
});
server.listen(8000);
使用stream就可以不需要把文件全部读取了再返回,而是一边读取一边返回,数据通过管道流动给客户端,真的减轻了服务器的压力。
node如何做到主进程和子进程共享一个端口
https://zhuanlan.zhihu.com/p/112597848
Master 通过 cluster.fork() 这个方法创建的,本质上还是使用的 child_process.fork() 这个方法
cluster其实就是对child_process的一层封装
cluster其实就是对child_process的一层封装
cluster其实就是对child_process的一层封装
Nodejs 的 Cluster 模块采用了哪种集群模式?
- 方案一:1 个 Node 实例开启多个端口,通过反向代理服务器向各端口服务进行转发
- 方案二:1 个 Node 实例开启多个进程监听同一个端口,通过负载均衡技术分配请求(Master->Worker)
首先第一种方案存在的一个问题是占用多个端口,造成资源浪费,由于多个实例是独立运行的,进程间通信不太好做,好处是稳定性高,各实例之间无影响。
第二个方案多个 Node 进程去监听同一个端口,好处是进程间通信相对简单、减少了端口的资源浪费,但是这个时候就要保证服务进程的稳定性了,特别是对 Master 进程稳定性要求会更高,编码也会复杂。
在 Nodejs 中自带的 Cluster 模块正是采用的第二种方案。
如何多个进程监听同一个端口
fork()
其实我们只要在绑定端口号(bind函数)之后,监听端口号之前(listen函数),用fork()函数生成子进程,这样子进程就可以克隆父进程,达到监听同一个端口的目的。
https://programtip.com/zh/art-28719
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`工作进程 ${worker.process.pid} 已退出`);
});
} else {
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
}
上面的代码就简单的将cluster模块加入到了node.js项目中。但是仔细分析一下这段代码你可能会产生这些疑问:主进程仅仅fork出了子进程,并没有创建httpserver,说好的主进程接收请求分发给子进程呢?每一个子进程都创建了一个httpserver,并侦听同一个端口
对于cluster的分析,得出以下结论:
-
cluster在创建子进程时,会在环境变量中增加标识,以此来区分主进程和子进程
-
listen函数在实现时对主进程和子进程进行了区分,在不同的进程中会执行不同操作
-
nodeJS封装了进程间通信的方法,支持在进程间发送句柄的功能,句柄可以是一个socket对象,一个管道等等
-
一个端口只能被一个进程监听,但是该端口可以建立多个连接(accpet是产生的套接字),不同进程间可以共享这些套接字
-
子进程的listen函数并没有监听端口,它在listen时将端口和地址等信息发送给主进程,由主进程进行监听。主进程在收到accept事件时,产生连接socket,并把它发送给子进程。子进程直接通过该socket跟client端进行通信
Socket是什么
https://www.jianshu.com/p/01b9a454de5a
socket原意是“插座”或“插孔”,在网络中每台服务器相当于一间房子,房子中有着不同的插口,每个插口都有一个编号,且负责某个功能。插口就是socket服务,插口的编号就是端口号,而插头也是一个socket服务。
socket的含义就是两个应用程序通过一个双向的通信连接实现数据的交换,连接的一段就是一个socket
socket套接字是对TCP/IP协议的封装,自身并非协议而是一套调用的接口规范(API)。通过套接字Socket,才能使用TCP/IP协议。
应用层通过传输层进行TCP通信时,有时TCP需要为多个应用程序进程提供并发服务。多个TCP连接或多个应用程序进程可能需要通过同一个TCP协议端口传输数据。为了区别不同的应用程序进程和连接,许多计算机操作系统为应用程序与TCP协议交互提供了称为套接字 (Socket)的接口,区分不同应用程序进程间的网络通信和连接。
盒马三面 (电话 同事面)
50分钟左右,已过
- 一个页面,两个模块同时发出请求,如何复用? (宏观是同时,微观上其实还是有先后)
- 一个tab页面渲染大量数据。 (虚拟列表)
- 虚拟列表滚动时,item还没加载出来时白屏如何处理? (骨架屏幕)
- 虚拟列表滚动条不准确如何处理? (隐藏原生滚动条,实现自定义滚动条)
- 长度为100w的数组,数组每一项是长度64位的字符串,找到其中的最大的那一个 (top K 算法)
- 微信小程序双线程架构的优势和特点?
找到大数组中的最大的数
长度为100w的数组,数组每一项是长度64位的字符串,找到其中的最大的那一个
当数组非常大的时候,我们对整个数组进行排序是一项非常非常耗时的操作。
解决:
- 局部排序,不再全局排序,只对最大的k个排序。
冒泡是一个很常见的排序方法,每冒一个泡,找出最大值,冒k个泡,就得到TopK。
时间复杂度:O(n*k)
- 局部堆排序 (只找到TopK,不排序TopK)
先用前k个元素生成一个小顶堆,这个小顶堆用于存储,当前最大的k个元素。
接着,从第k+1个元素开始扫描,和堆顶(堆中最小的元素)比较,如果被扫描的元素大于堆顶,则替换堆顶的元素,并调整堆,以保证堆内的k个元素,总是当前最大的k个元素。
时间复杂度:O(n*lg(k)) k为堆里面的元素个数
(堆排序还有一个好处就是我们的长度为100w的数组可以切开放到不同的机器上,分布式思想,维护一个k大小的堆就行了)
微信小程序双线程架构的优势和特点
与传统的浏览器Web页面最大区别在于,小程序的是基于 双线程 模型的,在这种架构中,小程序的渲染层使用 WebView 作为渲染载体,而逻辑层则由独立的 JsCore 线程运行 JS 脚本,双方并不具备数据直接共享的通道,因此渲染层和逻辑层的通信要由 Native 的 JSBrigde 做中转。
lazada一面
- 错误异常监控。资源加载失败怎么监控 => 跨域js的 error 怎么监控。
- jsbridge 原理 => jsbridge安全性问题 => js 通过jsbridge发送多个消息传到app(url scheme),app只收到了一个,怎么解决?
- react hooks => useMeno是什么 => 怎么实现的 => 写过哪些自定义hooks
- 多个库依赖不同版本base库 比如1.0 2.0 , 该怎么办?
- css tree 怎么附着在 dom tree 上面生成render tree => css附着过程的查找方式 dfs 还是 bfs ?
- let const 转es5 最终代码是怎么样的?
- 小程序 setData 优化。 observer怎么实现?
- m3u8 前端播放器你做了哪些工作?? 断网续播怎么实现 => seek到正确位置?video.js播放器在移动端会有哪些坑?
- 工作流优化做了哪些工具?有指标吗?
- babel-preset-env 的坑
- babel-runtime 是要放在 dependencies 还是 devDependencies
监控资源加载失败
使用 window.addEventListener 捕获阶段
onerror 的事件并不会向上冒泡
需要useCapture设置成true 在捕获阶段获得
那么如果区分脚本错误还是资源错误呢?我们可以通过 instanceof 区分,脚本错误参数对象 instanceof ErrorEvent,而资源错误的参数对象 instanceof Event。
ErrorEvent 继承于 Event ,所以不管是脚本错误还是资源错误的参数对象,它们都 instanceof Event,所以,需要先判断脚本错误。
/**
* @param event 事件名
* @param function 回调函数
* @param useCapture 回调函数是否在捕获阶段执行,默认是false,在冒泡阶段执行
*/
window.addEventListener('error', (event) => {
if (event instanceof ErrorEvent) {
console.log('脚本错误')
} else if (event instanceof Event) {
console.log('资源错误')
}
}, true);
监控跨域js的 error
对于不同源的脚本报错,无法捕获到详细错误信息,只会显示 Script Error
解决:
- 同源化 (将js文件与html文件放到同一域名下)
- 跨源资源共享机制( CORS ) (为页面上script标签添加crossorigin属性)
区分浏览器关闭和刷新
这个其实在绝大部分情况下都是没必要区分开的。
页面加载时只执行onload
页面关闭时先执行onbeforeunload,最后onunload
页面刷新时先执行onbeforeunload,然后onunload,最后onload。
我们可以在离开页面是判断 or 进入页面时判断
举个例子:
这里用进入页面时判断 (判断是刷新 还是 重新进入页面)
const now = new Date().getTime();
const leaveTime = parseInt(localStorage.getItem('leaveTime'), 10);
const refresh = (now - leaveTime) <= 5000;
alert(refresh ? '刷新' : '重新登陆');
window.onunload = () => {
window.localStorage.setItem('leaveTime', new Date().getTime());
};
扩展知识:
visibilitychange事件是浏览器新添加的一个事件,当浏览器的某个标签页切换到后台,或从后台切换到前台时就会触发该消息
document.addEventListener("visibilitychange", function (event) {
if (document.visibilityState === "visible") {
console.log('visible',event);
} else {
console.log('hidden',event);
}
});
ES6 的 let 实现原理
var funcs = [];
for (let i = 0; i < 10; i++) {
funcs[i] = function () {
console.log(i);
};
}
funcs[0](); // 0
babel 编译之后的 es5 代码(polyfill)
var funcs = [];
var _loop = function _loop(i) {
funcs[i] = function () {
console.log(i);
};
};
for (var i = 0; i < 10; i++) {
_loop(i);
}
funcs[0](); // 0
其实我们根据 babel 编译之后的结果可以看得出来 let 是借助闭包和函数作用域来实现块级作用域的效果的
在不同的情况下 let 的编译结果是不一样的
babel-runtime
https://babeljs.io/docs/en/babel-runtime/
babel-runtime 在sdk 或者第三库中只需要放devDependencies,但在最终的一些项目,比如页面打包,要放dependencies中
css查找流程
浏览器CSS匹配从右到左进行查找 (查找时采用bfs算法 => 可以拿到所有匹配的子节点)
手写题:
deepClone() 深拷贝对象
写一个定时器
tip:pause 之后能够再次start
class Timer{
start(){}
pause(){}
cancel(){}
}
解决
class Timer {
constructor(num) {
this.num = num;
this.timer = null;
this.hasStarted = false;
}
start() {
if (this.hasStarted) {
return;
}
this.hasStarted = true;
if (this.timer) {
// 处理pause之后再start
clearInterval(this.timer);
}
this.timer = setInterval(() => {
if (this.num < 0 || !this.hasStarted) {
return;
}
console.log(this.num);
this.num--;
}, 1000);
}
pause() {
if (!this.hasStarted) {
return;
}
this.hasStarted = false;
}
cancel() {
if (!this.hasStarted) {
return;
}
this.hasStarted = false;
this.num = 0
if (this.timer) {
clearInterval(this.timer);
this.timer = null;
}
}
}
测试
let t = new Timer(100);
t.start();
setTimeout(() => {
t.pause();
}, 5000);
setTimeout(() => {
t.start();
}, 9000);
setTimeout(() => {
t.cancel();
}, 20000);
lazada二面
对项目的描述 难点 重点 梳理不清楚 表达不清晰 导致了最终gg
- 主要简历
- m3u8 和 mp4 的区别
- 刷新页面随机颜色不能重复 “#123434” => hash冲突
- webpack4 => webpack5 有什么变化
- webpack5 tree-shaking 需要配置什么
- immutable 做了什么
- rxjs 做了什么
- apaas 分层架构
- npm 发的包 线上出了问题 怎么办? 除了降级
immutable
https://juejin.cn/post/6863832173703593997
immutable数据一种利用结构共享形成的持久化数据结构,一旦有部分被修改,那么将会返回一个全新的对象,并且原来相同的节点会直接共享。
每次修改一个 immutable 对象时都会创建一个新的不可变的对象,在新对象上操作并 不会影响到原对象的数据。
m3u8 和 mp4 的区别
m3u8是苹果公司推出的视频播放标准,编码格式采用UTF-8;mp4是有动态图像专家组MPEG制定的一种用于音频、视频信息的压缩编码标准。m3u8只是个文本文件,存储媒体文件路径,mp4是封装好的h264或h265媒体文件。
智能信息一面
- 项目架构?项目工作流?
- 播放器相关?
- web ktv 相关?
- lerna 和 pnpm 的区别?
- react组件间传值的方法?
- react 中类组件和函数组件的区别? 类组件的缺陷? (类组件抽取公共逻辑比较麻烦没有hooks好用 => 比如需要跨越多个生命周期的公共逻辑)
-
提取hooks的原则? (公共逻辑且带有状态的,不适合写util函数的)
- useEffect 里面多个依赖,导致里面函数频繁更新怎么办? (尽量减少依赖,更新函数内部用if判断是否要执行后续逻辑)
- 受控组件和非受控组件? (用useEffect去处理副作用 还是 通过事件去处理副作用)
- store中 redo/undo怎么实现? (redux ? mobx怎么进行状态回溯?)
- 怎么去设计store? (分层 domain store 和 ui store)
- mobx的实现原理? (Proxy 代理 set 和 get)
自定义 Hooks 场景
1.抽离业务逻辑层 (逻辑复用,关注分离)
2.封装通用逻辑 (实现代码的模块化和解耦)
3.监听浏览器状态
4.拆分复杂组件。
lerna 和 pnpm区别
lerna已经不再持续维护了
yarn安装依赖太慢了
yarn workspace 缺陷:
在 yarn + lerna 中的方案是配置自动抬升,这种方案会存在依赖滥用的问题,因为抬升到顶层后是没有任何限制的,一个依赖可能加载到任何存在于顶层 node_modules 存在的依赖,而不受他是否真正依赖了这个包,这个包的版本是多少的影响。
就是说,比如packages/项目 的package.json中没有依赖包,但是因为所有包都提升到顶层了,所以所有项目都可以使用没有依赖的包,这样单独安装项目后,就会报错。
子项目源码可以访问本不属于当前项目所设定的依赖包。
pnpm 则是通过使用符号链接的方式仅将项目的直接依赖项添加到 node_modules 的根目录下。
智能信息一面
- 根据简历去问
- mobx 和 redux 怎么技术选型
- react 和 vue 的差异
- canvas渲染的性能优化
- react 16/17/18 的区别
算法:
实现深度遍历查找
const tree = {
name: "a",
children: [
{
name: "b",
children: [
{ name: 'g' },
{ name: 'h' },
]
},
{
name: "c",
},
{
name: "d",
children: [
{ name: 'j' },
]
},
{
name: "e",
},
{
name: "f",
}
]
}
deepFind(tree, 'j')
解决:
const deepFind = (tree, name) => {
if (tree.name === name) {
return true
}
if (!tree.children || !tree.children.length) {
return false
}
for (let i = 0;i < tree.children.length;i++) {
const child = tree.children[i]
const result = deepFind(child, name)
if (result) {
return true
}
}
return false
}
实现自定义filter
const arr = [1, 2, 3, 4]
Array.prototype.myFilter = function (fn, context) {
// 实现自定义 filter
// fn 参数 为 item当前值 index索引 list整个数组
// context 为 fn 的 this 指向上下文
}
const res = arr.myFilter(function (item, index, list) {
console.log(item, index, list)
return item > 2
})
console.log(res)
实现:
Array.prototype.myFilter = function (fn, context) {
if (typeof fn !== 'function') {
throw new Error("fn is not a function")
}
const res = []
const ctx = context || window
for (let i = 0;i < this.length;i++) {
if (fn.call(ctx, this[i], i, this)) {
res.push(this[i])
}
}
return res
}
智能信息二面
- 主要还是问简历上的一些项目 (大厂非常重视指标,如果做了优化之类的工作,一定要有优化前和优化后的指标数据)
- CDN 查找原理 => 查看网络相关blog
- electron 和 小程序 的渲染的异同点
- js动画和css动画的区别?为什么js动画更消耗性能?
- canvas绘制原理? (在canvas标签里面绘制比在dom树中绘制性能跟高)
- 浏览器绘制ui的底层原理
- 对http协议的认识? http 1.1 和 2.0 的区别
- 有没有遇见过流量挟持问题?
腾讯
pcg一面
基础面
- 常见状态码 100 200 301 302 304 (临时重定向,永久重定向的表现有什么不一样)400 401 403 404 (401 403 的区别)500 503
- flex布局 grid布局
- 给你设计稿 怎么拆分页面 组件 布局
- 对单元测试了解
- 对ts的了解
- 对vue3的了解
http状态码301和302的区别
https://blog.csdn.net/ai2000ai/article/details/80242193
详细来说,301和302状态码都表示重定向,就是说浏览器在拿到服务器返回的这个状态码后会自动跳转到一个新的URL地址,这个地址可以从响应的Location首部中获取(用户看到的效果就是他输入的地址A瞬间变成了另一个地址B)——这是它们的共同点。
他们的不同在于301表示旧地址A的资源已经被永久地移除了(这个资源不可访问了),搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址;302表示旧地址A的资源还在(仍然可以访问),这个重定向只是临时地从旧地址A跳转到地址B,搜索引擎会抓取新的内容而保存旧的网址。
什么时候需要重定向呢?
- 网站调整(如改变网页目录结构);
- 网页被移到一个新地址;
- 网页扩展名改变(如应用需要把.php改成.Html或.shtml)。
这种情况下,如果不做重定向,则用户收藏夹或搜索引擎数据库中旧地址只能让访问客户得到一个404页面错误信息,访问流量白白丧失;再者某些注册了多个域名的网站,也需要通过重定向让访问这些域名的用户自动跳转到主站点等。
vue 的 computed 的原理
https://juejin.cn/post/6844904200539734023
// 注意这里 lazy watcher
const computedWatcherOptions = {lazy: true}
function initComputed(vm: Component, computed: Object) {
// $flow-disable-line
const watchers = (vm._computedWatchers = Object.create(null))
// computed properties are just getters during SSR
const isSSR = isServerRendering()
for (const key in computed) {
const userDef = computed[key]
const getter = typeof userDef === 'function' ? userDef : userDef.get
if (!isSSR) {
// create internal watcher for the computed property.
watchers[key] = new Watcher(
vm,
getter || noop,
noop,
computedWatcherOptions
)
}
// component-defined computed properties are already defined on the
// component prototype. We only need to define computed properties defined
// at instantiation here.
if (!(key in vm)) {
defineComputed(vm, key, userDef)
}
}
}
这里遍历了 computed 里面的每一个属性,并且为每一个属性初始化了一个 Watcher 对象。这样,当我们在 computed 里面访问 data 里面的属性时,就可以收集到依赖了。注意到这里传入了 { lazy: true },我们看看会有什么效果:
this.dirty = this.lazy // for lazy watchers
...
this.value = this.lazy
? undefined
: this.get()
该属性仅仅是标记了当前数据是 “脏的”,并且不会立即求值。
然后我们看看 defineComputed 做了啥:
export function defineComputed(
target: any,
key: string,
userDef: Object | Function
) {
// 不考虑服务端渲染,这里为 true
const shouldCache = !isServerRendering()
// 只看 computed 值为函数的情况
if (typeof userDef === 'function') {
sharedPropertyDefinition.get = shouldCache
? createComputedGetter(key)
: createGetterInvoker(userDef)
sharedPropertyDefinition.set = noop
}
Object.defineProperty(target, key, sharedPropertyDefinition)
}
这里执行了 createComputedGetter 这个方法:
function createComputedGetter(key) {
return function computedGetter() {
const watcher = this._computedWatchers && this._computedWatchers[key]
if (watcher) {
if (watcher.dirty) {
watcher.evaluate()
}
if (Dep.target) {
watcher.depend()
}
return watcher.value
}
}
}
当我们第一次访问计算属性的时候会触发 get,由于 dirty 为 true,所以这里会走 watcher.evaluate 进行求值,并将 this.dirty 置为 false,这样下次再对 computed 进行求值的时候就不会执行 watcher.evaluate() 了,这样就实现了缓存功能。
evaluate () {
this.value = this.get()
this.dirty = false
}
而当 computed 依赖的数据变化的时候,会触发 Watcher 的 update:
update () {
/* istanbul ignore else */
// computed
if (this.lazy) {
this.dirty = true
} else if (this.sync) {
this.run()
} else {
// 入队
queueWatcher(this)
}
}
这里仅仅是把 dirty 又重置为了 true 以使得下次对 computed 进行求值的时候重新执行 watcher.evaluate()。
页面A 引用了 computed B,computed B 依赖了 data C
https://juejin.cn/post/6844903877699960846
data C 开始变化后
通知 computed B 更新,然后 computed B 开始重新计算
接着 computed B 通知 页面A更新,然后重新读取 computed
一条链式的操作? C -》 B -》 A 这样的执行顺序吗?
答案:不是
其实真正的流程是,data C 开始变化后
1通知 computed B watcher 更新,其实只会重置 脏数据标志位 dirty =true,不会计算值
2通知 页面 A watcher 进行更新渲染,进而重新读取 computed B ,然后 computed B 开始重新计算
为什么 data C 能通知 页面 A?
data C 的依赖收集器会同时收集到 computed B 和 页面 A 的 watcher
为什么 data C 能收集到 页面A 的watcher?
在 页面 A 在读取 computed B 的时候,趁机把 页面A 介绍给 data C ,于是 页面A watcher 和 data C 间接牵在了一起,于是 data C 就会收集到 页面A watcher
所以computed 如何更新
被依赖通知更新后,重置 脏数据标志位 ,页面读取 computed 时再更新值
判断一个东西是不是对象
- Object.prototype.toString()
- instanceof 原理
- typeof 弊端
深挖简历
-
loc 依赖反转为什么用 有什么用 还是会打包进sdk吗 (sdk相关)
-
b端项目的文件结构
-
爬虫
-
框架
pcg二面
总结:描述具体项目的时候组织语言欠缺一点清晰,不能把一件事讲的非常清楚,没有很好地突出自己所做的东西的难点,和岗位的匹配度不够
主要是对简历的一些深入了解,对项目的考察
- 你做过最难的事情是什么
- 技术成长
- 技术思考
- …
PCG 商业广告一面
- 数组常用方法 => reduce? => sort api 会改变原数组吗? 会。就地对数组的元素进行排序,并返回对相同数组的引用
- 数组 中 push api 的返回值 => 返回新的数组长度
- vue2/vue3 对数组的处理? Object.defineProperty 和 Proxy 的区别
- react ServerComponent => 有什么用
- webpack 和 vite 的区别
- vite 中为什么生产环境不用 esbuild?
- http 和 https
- https 对称加密和非对称加密 => 为什么不直接用非对称加密
- react 和 vue 的区别
- react 16/17/18 的区别
- hooks 的好处
react ServerComponent
https://blog.logrocket.com/what-you-need-to-know-about-react-server-components/
https://www.freecodecamp.org/news/how-to-use-react-server-components/
reactServerComponent 是 React 的一个新功能,用于改善服务器渲染(Server-side Rendering)时的性能和交互性。
使用 reactServerComponent,可以将 React 组件的渲染过程放在服务器端完成,然后将渲染的结果发送到客户端。这样可以减轻客户端的负担,提高初始加载速度,并且可以在首次渲染后继续从服务器端接收更新的组件。
reactServerComponent 具有以下特点和用处:
- 减轻客户端负担:React 组件的渲染过程在服务器端完成,客户端只需接收已渲染好的结果,无需再进行大量的计算和渲染。
- 提高初始加载速度:由于渲染工作在服务器端完成,可以将渲染结果直接发送到客户端,从而加快页面的初始加载速度。
- 支持组件的增量渲染:reactServerComponent 提供了服务端和客户端之间的通信接口,可以在首次渲染后继续从服务器端接收更新的组件,实现组件的增量渲染。
- 提供一致的交互性:reactServerComponent 可以在服务器端处理用户的交互操作,并将更新的结果发送到客户端,从而实现与客户端渲染一样的交互性。
总的来说,reactServerComponent 通过在服务器端完成组件的渲染和更新,并与客户端进行交互,提供了更高效和更一致的服务器渲染体验。
RSC 和 SSR 的区别
RSC => React Server Component
With Server Side Rendering, we send the raw HTML from the server to the client, then all the client side JavaScript gets downloaded. React starts the Hydration process to transform the HTML to an interactive React component. In SSR the component doesn’t stay on the server.
with React server components, the components stay on the server and have access to the server infrastructure without making any network roundtrips.
SSR is useful for faster loading of the initial page of your application. You can use SSR and RSCs together in your application without any problems.
算法:
快速排序
不能原地排序
onst quickSort = (arr = []) => {
if (arr.length <= 1) {
// 注意这个结束条件
return arr
}
// 注意:这里一定要int => 不然出现 arr[1.5] => 导致死循环
let index = parseInt(arr.length / 2)
let left = []
let right = []
for (let i = 0;i < arr.length;i++) {
if (i !== index) {
if (arr[i] <= arr[index]) {
left.push(arr[i])
} else {
right.push(arr[i])
}
}
}
return [...quickSort(left), arr[index], ...quickSort(right)]
}
template 解析器
const data = {
aaa: "11111111",
bbb: "222"
}
let template = "abc abc"
// 将template中中的值替换成data中的值
const res = test(template, data)
console.log("res", res)
解决:
// 正则(最快的方式)
function test(template = "", data = {}){
let reg = /\{\{(\S+)\}\}/g
return template.replace(reg, (...args) => {
const [match, p1] = args
return data[p1]
})
}
const test = (template = "", data = {}) => {
let res = ""
let leftFirstIndex = []
let flag = false
for (let i = 0;i < template.length - 1;i++) {
let char = template[i]
let nextChar = template[i + 1]
if (char == "{" && nextChar == "{") {
leftFirstIndex.push(i)
flag = true
} else if (char == "}" && nextChar == "}") {
let rightFirstIndex = i
let lastLeftFirstIndex = leftFirstIndex.pop()
// 截取
let key = template.slice(lastLeftFirstIndex + 2, rightFirstIndex)
let value = data[key]
// 拼接
template = template.slice(0, lastLeftFirstIndex) + value + template.slice(rightFirstIndex + 2)
// 计算i坐标 => 光标是否要移动
// 考虑 => 字符串可能别之前少 可能比之前多
let reduce = 1 // 减少的部分
let add = value.length
let num = add - reduce // 变化值
if (num > 0) {
while (num >= 0) {
num--
i++
}
} else {
while (num <= 0) {
num++
i--
}
}
flag = false
} else {
if (!flag) {
res += char
}
}
}
return res
}
商业直播一面
主要还是一些常规的基础面试
时间:1h30min
- 什么是闭包?你在哪里会使用到闭包?
- 浏览器的事件循环
- 常见的状态码
- 网络安全
- pwa
- virtual dom 和 virtual dom diff
- https相关
- 4点15分 分针和时针的夹角 => 3点和4点之间的夹角 30° => 4点15分 时针会偏移数字4 30° * 1/4 = 7.5° => 一共 37.5 °
微任务宏任务输出
setTimeout(() => {
console.log(1);
Promise.resolve().then(() => {
console.log(2);
});
})
setTimeout(() => {
console.log(3);
Promise.resolve().then(() => {
console.log(4);
});
})
// 1 2 3 4
控制并发
// fns 为请求函数
function multiRequest(fns, max) {
const len = fns.length;
const result = new Array(len).fill(false)
let count = 0
return new Promise((resolve, reject) => {
while (count < max) {
next()
}
function next() {
let current = count++
if (current >= len) {
if (!result.includes(false)) {
return resolve(result)
} else {
return reject(result)
}
}
let fn = fns[current]
Promise.resolve(fn()).then(res => {
result[current] = res
next()
})
}
})
}
大数相乘
输入2个数字组成的字符串,模拟乘法的方式输出他们的乘积。
function bigCalc(a = '', b = '') {
let long = ''
let short = ''
if (a.length > b.length) {
long = a
short = b
} else {
long = b
short = a
}
let shortIndex = short.length - 1
let longIndex = long.length - 1
let jinwei = 0 // 进位
let ten = 0
let arr = []
while (shortIndex >= 0) {
let str = getOneStr(short[shortIndex], long, ten)
arr.push(str)
ten++
shortIndex--
}
// 将arr全部加起来
return getTotalStr(arr)
}
function getOneStr(one, str, ten) {
let res = []
let index = str.length - 1
let jinwei = 0
while (index >= 0) {
let cur = one * str[index] + jinwei
// console.log(cur)
jinwei = parseInt(cur / 10) || 0
let temp = (cur % 10) + ''
res.unshift(temp)
index--
}
if (jinwei) {
res.unshift(jinwei + '')
}
while (ten) {
res.push('0')
ten--
}
return res.join('')
}
function getTotalStr(arr) {
let res = []
let jinwei = 0
let maxLen = arr[arr.length - 1].length
let maxIndex = arr[arr.length - 1].length - 1
arr = arr.map((item) => {
while (item.length < maxLen) {
item = '0' + item
}
return item
})
while (maxIndex >= 0) {
let cur = jinwei
for (let i = 0; i < arr.length; i++) {
cur += parseInt(arr[i][maxIndex])
}
jinwei = parseInt(cur / 10) || 0
let temp = (cur % 10) + ''
res.unshift(temp)
maxIndex--
}
if (jinwei) {
res.unshift(jinwei)
}
return res.join('')
}
测试
let a = '123'
let b = '12'
const res = bigCalc(a, b)
console.log('res', res)
// 0246
// 1230
// ------------
// 1476
商业直播二面
时间:40min+
如何使首屏加载更快? (vendor移除非首屏的chunk js使用async 和 defer)
你做过那些性能优化?
给你一个网站如何具体设计缓存策略?强缓存 协商缓存?哪些资源需要强缓存?
hybrid app 内嵌h5 如何双向通信? app => h5 和 h5 => app
Pwa离线加载的原理 ?怎么做到缓存的?
canvas动画的优势? canvas 和animation相比较它的优势在哪里?
cdn的原理?当资源一上传的cdn它就一定能在最近的节点获取到吗?了解过cdn回源吗?
你搭建的工作流 在开发时和编译时分别做了哪些处理?
对pwa的了解
如何使首屏加载更快
-
组件懒加载
-
减少http请求
-
图片压缩 图片懒加载
-
CSS Sprites 精灵图
-
使用CDN
-
合理利用缓存
-
pwa
-
代码压缩
-
将样式表放在头部 将脚本放在底部
-
gizp压缩
-
Tree-shaking、Scope hoisting、Code-splitting
-
SSR
-
提早解析 DNS
<link rel="dns-prefetch" href="//oss-dev.ishowyu.com"> -
使用HTTP2
CDN
https://juejin.cn/post/6844903873518239752
CDN(Content Delivery Network,内容分发网络)将源站的内容发布到接近用户的网络“边缘”,用户可以就近获取所需数据,不仅降低了网络的拥塞状况、提高请求的响应速度,也能够减少源站的负载压力。
为了更加清楚地展示CDN的原理,我们首先回顾一下不使用缓存直接到源站请求数据的过程:
如上图所示,如果要访问的网站名为:”join.qq.com”,客户端首先会在本机的hosts文件和hosts缓存中查找该域名对应的IP地址;如果本机中没有此信息,则会到我们的本地DNS进行询问该域名对应的IP地址;如果本地DNS中仍然没有该域名的IP信息时,则会由本地DNS依次向根DNS、顶级域DNS、权威DNS进行询问,最终本地DNS将IP地址发送给客户端。客户端通过IP地址向远程的源站服务器发出HTTP请求并获取相应的数据内容。
通过CDN获取缓存内容的过程
CDN将我们对源站的请求导向了距离用户较近的缓存节点,而非源站。
如图所示是通过CDN进行请求响应的过程图。通过图中可以看出,在DNS解析域名时新增了一个全局负载均衡系统(GSLB),GSLB的主要功能是根据用户的本地DNS的IP地址判断用户的位置,筛选出距离用户较近的本地负载均衡系统(SLB),并将该SLB的IP地址作为结果返回给本地DNS。SLB主要负责判断缓存服务器集群中是否包含用户请求的资源数据,如果缓存服务器中存在请求的资源,则根据缓存服务器集群中节点的健康程度、负载量、连接数等因素筛选出最优的缓存节点,并将HTTP请求重定向到最优的缓存节点上。
通过这一系列的操作,将解析源站的目标域名的权力交给了GSLB,以致于GSLB可以根据地理位置等信息将用户的请求引导至距离其最近的”缓存节点”,减缓了源站的负载压力和网络拥塞。
这种工作方式利用CNAME将域名和目标IP之间进行解耦,将目标IP的解析权下放到GSLB中,方便实现更多自定义的功能,是一种更加灵活的方式。
补充:
CNAME记录则可以将一个域名(别名)转换为另一个域名,如果多条CNAME记录指向同一个域名,则可以将多个不同的域名的请求指向同一台服务器主机。并且,CNAME记录通常还对应了一条A记录,用于提供被转换的域名的IP地址。
CDN 回源?
当 cdn 缓存服务器中没有符合客户端要求的资源的时候,缓存服务器会请求上一级缓存服务器,以此类推,直到获取到。最后如果还是没有,就会回到我们自己的服务器去获取资源。
回源的请求或流量太多的话,有可能会让源站点的服务器承载着过大的访问压力,进而影响服务的正常访问。
那都有哪些时候会回源呢?
没有资源,资源过期,访问的资源是不缓存资源等都会导致回源。
当资源一上传的cdn它就一定能在最近的节点获取到吗?
不一定。要等资源推到所有的节点后,才那个获取
canvas
Canvas提供的功能更原始,适合像素处理,动态渲染和大数据量绘制
- 依赖分辨率
- 不支持事件处理器
- 弱的文本渲染能力
- 能够以 .png 或 .jpg 格式保存结果图像
- 最适合图像密集型的游戏,其中的许多对象会被频繁重绘
canvas优点:
定制型更强,可以绘制绘制自己想要的东西。
非dom结构形式,用JavaScript进行绘制,涉及到动画性能较高。
canvas缺点:
事件分发由canvas处理,绘制的内容的事件需要自己做处理。
依赖于像素,无法高效保真,画布较大时候性能较低。
缓存
https://zhuanlan.zhihu.com/p/28113197
给你一个网站如何具体设计缓存策略?
不要对变化的资源添加较短的max-age
如果对缓存使用恰当,能够为你的网站提升不少性能。但如果使用错误,也同样会给你的网站带来灾难。
index.html 不设置缓存 no-store
Service Worker
https://developers.google.com/web/fundamentals/primers/service-workers
Service Worker 是浏览器在后台独立于网页运行的脚本,它打开了通向不需要网页或用户交互的功能的大门。 现在,它们已包括如推送通知和后台同步等功能。
https://zhuanlan.zhihu.com/p/28113197
商业直播三面
- pc端网站扫码登录的整个流程。(pc端网站显示二维码后轮询登录结果,手机扫码登录…认证服务器返回token)
- 除了轮询还有别的什么方式吗? (webstock 和 http2)
- webstock 比 轮询的优势在哪? (webstock初始启动会慢)
-
Http2 服务器推送消息的原理
- 首屏加载优化 如何减少白屏时间 (可以采用ssr)
- 资源压缩
- webpack的压缩比例?
- 图片压缩 png和jpg的区别 png压缩成jpg体积减少多少
- 懒加载 和 预渲染 的区别
-
ssr的优点 和 缺点 (优点:seo 缺点:要注意原来生命周期的写法 全局data)
- 从技术的角度分析 一个产品什么时候选择native app 什么时候选择web app 什么时候选择小程序? (复杂交互动画效果 基于音视频 采用native app 基于微信生态系统 微信用户认证体系 采用微信小程序)
- 还有别的混合app的实现方式吗? (react native 和 fluter)
- 你对fluter的了解 (没了解)
- 你对react native 的了解 (基于react render渲染器采用native 渲染成native组件)
- preload 和 prefetch
全民K歌一面
- react 合成事件是什么?为什么需要合成事件?
- react hook 原理?和utils函数相比优势在哪里 (hook可以封装生命周期)
- webpack 4 升 webpack 5 注意的点 (node polyfill)
- vite 存在的问题? (dev 和 prod 产物会有不一致,浏览器最低兼容性不太够)
- 微信原生小程序的一些问题? 用过哪些小程序框架 (taro 和 wepy) => 答案见小程序blog
- taro跨端的原理? => 答案见小程序blog
- video.js 如何去做编解码?m3u8? (编解码由浏览器完成)
- Error 错误机制的封装
- webstock 和 http 协议的区别?
-
wasm 相关? 怎么编译wasm (c++)
- ktv中歌词渲染 (逐字渐变效果 background: linear-gradient)
- js bridge 的原理? native 如何通知回 h5 js (Native 端通过 evaluateJavascript/stringByEvaluatingJavaScript 方法,执行 JavaScript 逻辑,找到 callBackId 对应的js中callback执行)
- 码率是什么? (单位时间传送的数据,一般我们用的单位是kb/s或者Mb/s)
webpack4 => webpack5
- Webpack 5 默认不包括 Node.js 中的一些内置模块 (fs/path/stream/buffer/process)
- Webpack 5 引入了更智能的
splitChunks配置 - Webpack 4 中常用的
CommonsChunkPlugin插件已在 Webpack 5 中移除。取而代之的是,Webpack 5 使用splitChunks - Webpack 5 引入了
asset modules,这是一个新的内置功能,能够代替file-loader和url-loader - Webpack 5 中开发模式(development mode)性能得到了显著提升,尤其是在构建速度和缓存机制方面,但也可能需要更新一些开发环境配置。
微信原生小程序存在的问题:
- setData 效率很低
- 一个页面需要4个文件
- 文档写的烂 (一些相关的error code都查不到)
WebSocket 协议:
WebSocket 是通过 HTTP 协议进行“升级”的。在建立连接时,客户端会发送一个 Upgrade 请求头,表示请求升级到 WebSocket 协议。如果服务器支持 WebSocket,会接受这个升级请求,连接切换到 WebSocket 协议。
怎么编译wasm?
- rust => wasm-pack
-
C/C++ => emscripten => emcc hello.c -o hello.js
- go(语言本身支持编译成 WebAssembly) => GOARCH=wasm GOOS=js go build -o main.wasm main.go
TME 腾讯音乐三面
基础:
- http每一代的特点 (http3的特性)
- 缓存机制 (协商缓存/强缓存)
- 网页从url输入到渲染
- 网站安全问题 (csrf/xss)
- token 生成 (jwt)
项目:
- 如何评价一个网站性能 (performance/memory内存)
- 做过哪些性能优化 (业务代码/开发性能/工作流/用户 视角)
- 首帧出图 (300ms)
算法
在一个复杂数组中去重另外一个复杂数组:
// 思路:
// 遍历数组1 如果是简单数据直接查找是否存在数组2中,如果是复杂数据逐一和数组2中的复杂数据进行深比较
function deepEqual(item1, item2) {
if (item1 instanceof Array && item2 instanceof Array) {
// 数组
if (item1.length != item2.length) {
return false;
}
return item1.every((item, index) => {
return deepEqual(item, item2[index]);
});
} else if (item1 instanceof Object && item2 instanceof Object) {
// 对象
if (Object.keys(item1).length != Object.keys(item2).length) {
return false;
}
return Object.keys(item1).every((key) => {
return deepEqual(item1[key], item2[key]);
});
} else {
// 简单数据
return item1 == item2;
}
}
function removeDuplicate(arr1, arr2) {
let res = [];
for (let item1 of arr1) {
if (typeof item1 == 'object' && item1 != null) {
// 复杂数据
for (let item2 of arr2) {
if (typeof item2 == 'object' && item2 != null) {
if (deepEqual(item1, item2)) {
res.push(item1);
break;
}
}
}
} else {
// 简单数据
if (!arr2.includes(item1)) {
res.push(item1);
}
}
}
return res;
}
测试:
const arr1 = [
1,
2,
{
aa: 'aaa',
bb: [2, 4, 5],
cc: {
dd: 'dd',
},
},
[4, 5, [6, 7]],
8,
];
const arr2 = [
3,
2,
{
aa: 'aaa',
bb: [2, 4, 5],
cc: {
dd: 'dd',
},
},
[4, 5, [8, 7]],
7,
];
const res = removeDuplicate(arr1, arr2);
中小厂
斗游
一面
斗游是斗鱼投资的,专门做海外直播的
- vue相关的基础知识
- vue的双向绑定
- 移动端和pc分别如何做屏幕适配
- ……
一道笔试题目 (写完微信发过去,视频面试现场写)
function lottery(whiteList, participant){}
-
whiteList:类型字符串数组,意义是表示从其他系统中计算出来的活跃用户,如果这批用户参与抽奖,则必定让他中奖。长度不超过1万
-
participant:类型字符串数组,意义是表示此次活动中真正参与抽奖的用户,长度约是10万。
函数希望从participant返回两个2万个用户,表示中奖用户,优先选取whiteList上的用户,若不在whiteList上,对participant 剩余的随机 选取即可。
一开始版本
function lottery(whiteList, participant){
let set1 = new Set(whiteList)
let set2 = new Set(participant)
let num = 0
let res = []
for(let item of set2.values()){
if(set1.has(item.value)){
res.push(item.value)
set2.delete(item.value)
num++
}
}
let lest = 20000 - num
// 随机取剩下
getLes(lest)
return res
}
优化后
//如果这批用户参与抽奖,则必定让他中奖。 (也就whiteList不一定在participant)
function lottery(whiteList, participant) {
let set2 = new Set(participant)
let num = 0
let res = []
for (let item of whiteList) {
if (set2.has(item)) {
res.push(item)
num++
// 为了不影响后面的抽奖运算 还是要delete
set2.delete(item)
}
}
let lest = 20000 - num
// 随机取剩下
let otherArr = getLes(lest, set2)
return res.concat(otherArr)
}
二面
- 并行和并发的区别 ?node进程接受多个请求是并行还是并发?node开启多个进程(fork)?
- 图片相关?png jpg webp 特点? 哪个压缩率更好一点?为什么?
- 前端请求的一些异常?你的500错误是谁返回给你的(Nginx)(xml)?如果没有Nginx直接在服务器部署你获取的错误是谁返回给你的(浏览器底层)?
- node I/o 相关? 其源码(c++那部分)?
- 一个新闻页有 图片 列表 文字 评论 如何更快的渲染?
- 浏览器原理(渲染引擎 和 js引擎)?哪些东西会阻塞页面的正常渲染?
- 进程和线程的区别?
一道算法题目:
数字1-n的n张牌,打乱,写一个算法让他回归有序状态 (洗牌算法)
-
快速排序 (nlogn)(比较排序)
-
桶排序 (n)(非比较排序) (数字n的那张牌肯定在n位置)
考察:非比较排序
深信服
已拿到offer没去
一面
基础
- cookie和localStorage的区别
- 一个post请求如何跨域?不涉及后端,纯前端实现可以吗? (form表单)
- 一个串行的promise如何实现
- Js如何区分数组和对象
微信小程序
- 小程序如何调试
- 你的小程序工作流
- 你的小程序怎么兼容
- 你做的小程序框架的一些细节
vue
- vue通信机制 (
$emit,$on,eventbus,vuex) - 何时用vuex? 何时父子组件通信?
调试技巧
- 问很多日常开发中的调试技巧
- 有一个弹窗,时而出现,时而消失,如何定位bug? (调式的一些技巧,动态改写标签,指定标签状态actived,focus,source面板)
- 如何设置断点条件,查看调用栈
一些css基础问题
接触过3d吗
接触过地图相关开发吗
最近的一些学习
form表单跨域
form提交是不会携带cookie
没办法设置一个hidden的表单项,然后通过js拿到其他domain的cookie,因为cookie是基于域的,无法访问其他域的cookie,所以浏览器认为form提交到某个域,是无法利用浏览器和这个域之间建立的cookie和cookie中的session的,故而,浏览器没有限制表单提交的跨域问题。
form表单提交的结果js是无法拿到,所以没有去限制.
追一科技
一家c轮做人工智能的公司,前端对node要求高,问框架原理问的很细很深
一面
- 链表和数组区别?真实应用场景 (偏后端)(卧槽)
- diff细节?dom树更新怎么比较的?比较顺序?(是否component是否普通标签是否相同标签)同层对比?如果只是属性变了怎么更新?patchChildren?key的作用?
- vue diff具体的实现?双端比较?
- vue数据的响应式?
- vue-router 两种模式?hash模式后端可以拿到#吗?
- 垃圾回收机制?引用计数和标记清除的区别?在最顶级作用域 a引用b b引用a 怎么进行垃圾回收?v8最新的垃圾回收机制?
- vue的nextTrick是怎么实现的(降级,根据当前环境选择)?为什么要要优先使用微任务来实现nextTrick?
-
session和cookie的关系?
- Https 的加密模式 (混合加密)?怎么获取密匙?
hash模式后端可以拿到#吗
hash 虽然出现URL中,但不会被包含在HTTP请求中,对后端完全没有影响
链表的应用
https://juejin.cn/post/6844903946222321671
链表与数组最大的不同就在于删除、插入的性能优势,插入、删除的时间复杂度只有O(1)
对于不需要搜索但变动频繁且无法预知数量上限的数据,比如内存池、操作系统的进程管理、网络通信协议栈的trunk管理等等等等,都需要用到链表
链表和数组是两种基本的数据结构,它们在内存管理、访问效率和使用场景上有一些显著的区别:
- 内存结构
- 数组:数组是一块连续的内存区域,所有元素的存储地址连续。可以通过索引直接访问任何元素。
- 链表:链表由一系列节点组成,每个节点包含数据和指向下一个节点的指针。节点在内存中并不一定是连续的。
- 存储和大小
- 数组:在创建时需要定义大小,一旦定义后,大小不能动态调整。然而,它的每个元素都可以快速、随机访问。
- 链表:链表的大小可以动态变化,可以轻松增加或删除节点,而不需要提前指定大小,但不能像数组那样快速随机访问。
- 访问效率
- 数组:访问速度快(O(1)),对每个元素的读写都很高效。
- 链表:访问速度慢(O(n)),必须从头节点开始遍历,直到找到目标节点。
- 插入和删除效率
- 数组:在数组的中间插入或删除元素可能需要移动大量数据,时间复杂度为O(n)。
- 链表:在链表中插入或删除节点很高效,只需调整指针,时间复杂度为O(1),前提是已经定位到插入或删除位置。
- 内存使用
- 数组:由于存储空间是连续的,如果数组的大小太小,可能会浪费空间;如果太大,可能会导致内存不足。
- 链表:链表每个节点都需要额外的内存来存储指针,因此在某些情况下可能占用更多的内存。
使用场景
- 数组:适合用于需要快速访问和固定大小的场合,如图像处理等。
- 链表:适合需要频繁插入和删除操作的场合,如实现队列、栈等数据结构。
单向链表
- 撤销功能,这种操作最多见于各种文本、图形编辑器中,撤销重做在编辑器场景下属于家常便饭,单向链表由于良好的删除特性在这个场景很适用。实现图、hashMap等一些高级数据结构
双向链表
- 编辑器的「undo/redo」操作
晓教育 (星火)
一面
基础:
- 垂直居中一个元素
- position元素怎么确定定位
- 盒模型
- 缓存(请求返回200 的时候的缓存)
- copy一个对象?深拷贝?怎么深拷贝一个函数?
- 常用状态码
vue
(问很多vue的问题,偏应用,问原理比较少)
- vue实现一个类似react的hoc高阶组件
- element的表单验证怎么做的?(form)(源码)
- inject和provide
$attr和$listen(子组件怎么拿到一个父组件的xxx 不通过props传递)- 组件间通信
- watch的原理?怎么更新的?(user watcher)
node
- node微任务 宏任务执行顺序
- koa的中间件机制?洋葱模型?
- 怎么写一个转发请求的中间件?
- 链接数据库
- 用过哪些中间件
- 定时任务
- 爬虫怎么爬数据 (流程)
- node里面怎么发起网络请求
gulp
- gulp.watch和node原生watch对比
二面
前端知识
- 如何进行图表的错误监控?
- 长列表优化 (recycle view 适用于card固定高度)?如果card高度不固定,聊天场景,1w条聊天信息怎么搞?(首屏渲染 分页 减少dom操作 fragment)
- 问了一些具体业务场景的设计方案
后端知识
- 10亿条url 8g内存 无限大磁盘 如何去重url (url对应的资源不同就是不同url 可能不同url对应同一个资源,不能借助数据库)(找到url对应资源进行算法签名。。。来区分不同url)
- 说一下可以提取文件特征的加密算法 (MD5 。。。。sha。。。)
算法
- 说一下快速排序的实现?怎么优化快速排序?
优化快速排序:
- 选择数组中间的元素作为基准
- 当数组长度较小的时候才用插入排序之类
如何进行图表的错误监控? (尝试回答)
通常图表使用echarts库,错误大概率是两种情况,渲染的dom错误,图表对应的数据源不对
- 针对渲染的dom错误,我们可以监听dom,使用MutationObserver,观察图表是否正常渲染
- 针对图表对应的数据源错误,我们直接监听数据,看是否为空,是否满足图表所需的数据格式
富途
大型证券公司,腾讯投资,美国上市
富途一面
时长:一个半小时 对基础的考察非常的深
-
闭包是什么?闭包的作用?哪些场景会用到闭包 => 回调函数,compose,缓存
- event loop?浏览器的事件循环?node的事件循环?node事件循环和浏览器事件循环的区别?node后来版本的事件循环 相比 之前版本的事件循环做了哪些变动?
- 输入一个url到最终页面展示的详细过程?在这个过程中我们可以做的优化手段?
- 网络安全相关 (xss csrf ddos http中间人攻击)? 怎么样做可以避免这些安全问题?
- 你对promise的理解
- webpack是什么 => 模块打包器? webpack打包原理 => entry => 构建依赖图谱 => loader处理对应文件
- webpack 的loader和plugin是什么?有什么区别
- 怎么样写一个webpack-loader
- treeshaking是什么? treeshaking在什么时候执行的 => 编译时
- 对webpack5的了解 => hard-source-webpack-plugin 。。。 更好的缓存 环境区分 更好的hash算法 静态资源处理
- http和https的区别?对http2的了解?
-
vue 的diff过程 => patch => patchChildren => diff 双指针对比 ? isSameNode 怎么判断的 => key是否相等 && type是否相等 …
-
computed 和 watcher 的区别 ? computed 为什么初始化的时候不会去计算值 => dirty => 不会去调用
- jwt是什么 => 这是一套无状态的验证机制
手写题
请使用两种方式实现纯css“左栏定宽200px,右栏自适应”布局
- 这两种方式的优点和缺点
- flex布局的优点和缺点
用递归的方式实现斐波那契数列,输入数字n, 输出第n项, 并加上缓存功能
- 缓存功能能不能不使用全局变量 => 使用局部变量 fibo(n,obj)
- 更好的方式 => 闭包实现
给定一个字符串str, 只会出现{}这6种字符, 请实现一个函数isMatch(str)判断这个字符串中的括号是否是匹配的 例如以下字符串均为括号匹配的: (){()[{}]} ()({}) {()}[]{()}
解决思路: 栈
实现一个批量请求函数 multiRequest(urls, maxNum),要求如下:
-
要求最大并发数 maxNum
- 每当有一个请求返回,就留下一个空位,可以增加新的请求
- 所有请求完成后,结果按照 urls 里面的顺序依次打出
使用 JWT 的劣势
- JWT 的最大缺点是无法作废已颁布的令牌:由于服务器不保存 session 状态,因此无法在使用过程中废止某个 token,或者更改 token 的权限。也就是说,一旦 JWT 签发了,在到期之前就会始终有效,除非服务器部署额外的逻辑。
- 严重依赖于秘钥:
JWT的生成与解析过程都需要依赖于秘钥(Secret),且都以硬编码的方式存在于系统中(也有放在外部配置文件中的)。如果秘钥不小心泄露,系统的安全性将受到威胁。 - 冗余的数据开销:一个
JWT签名的大小要远比一个SessionID 长很多,如果对有效载荷(payload)中的数据不做有效控制,其长度会成几何倍数增长,且在每一次请求时都需要负担额外的网络开销。如果放在 Local Storage,则可能受到XSS攻击。
富途二面
5道手写题
时间:80min左右
油漆题目
没答出来
有两桶相同量的红蓝油漆,问从红桶舀一勺油漆到蓝桶,再从蓝桶舀一勺油漆到红桶,问红桶的“红蓝比”高,还是蓝桶的“蓝红比”高。
- 假设法:
假设第一次舀了一整桶红油漆到蓝桶(假设是500ml),第二次从蓝桶舀了500ml到红桶,所以红桶的红蓝比和蓝桶的蓝红比一样。
- 计算法:
假设:
每桶:10L 桶舀一勺:1L 红桶纯度:红占所有的比例 蓝桶纯度:蓝占所有的比例
| 红桶 | 红桶纯度 | 蓝桶 | 蓝桶纯度 |
|---|---|---|---|
| 10 | 10/10 = 100% | 10 | 10/10 = 100% |
| 9 | 9/9 = 100% | 11 | 10/11 = 90.9% |
| 10 | (9+ 1/11*1)/10 = 90.9% | 10 | 90.9% |
从红桶舀一勺油漆到蓝桶 红桶纯度还是100% 蓝桶纯度变成 90.9%
接着
再从蓝桶舀一勺油漆到红桶 蓝桶纯度还是90.9% 红桶纯度变为为90.9% (舀过来的1L中1/11是红的 => 对红桶浓度有帮助)
最终 红桶纯度 == 蓝桶纯度
所以 红桶的“红蓝比” == 蓝桶的“蓝红比”
移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
示例:
输入: [0,1,0,3,12]
输出: [1,3,12,0,0]
说明:
必须在原数组上操作,不能拷贝额外的数组。 尽量减少操作次数。
写了三种解法
这种移除掉中间的0 会影响数组后面的元素 (在大数组的情况下 这样是非常不好的)
/**
* @param {number[]} nums
* @return {void} Do not return anything, modify nums in-place instead.
*/
var moveZeroes = function (nums) {
let zeroNum = 0
for (let i = 0; i < nums.length; i++) {
if (nums[i] === 0) {
nums.splice(i, 1)
i--
zeroNum++
}
}
// console.log("zeroNum", zeroNum)
while (zeroNum) {
nums.push(0)
zeroNum--
}
// console.log(nums)
};
更好的解法:
双指针…
扑克牌
52张牌(不要大王小王),抽两张牌是同颜色的概率?
26/52 * 25/51 *2
猴子吃桃
一堆桃子,一群猴子,猴子吃桃,每只猴子吃3个桃子还剩下59个桃子。每只猴子吃5个桃子,最后一个猴子分不到5个桃子。问有多少个桃子?有多少只猴子
设
桃子 x
猴子 y
x - 3y = 59
x - 5(y-1) < 5 (0,1,2,3,4)
解得:。。。。 三个解
类似税率的阶梯计算
/*用户在平台上进行交易,需要交平台使用费。
平台使用费的梯度收费方案如下:
每月累计订单数每笔订单(港元)
梯度1:1-5笔30.00
梯度2:6-20笔15.00
梯度3:21-50笔10.00
梯度4:51-100笔9.00
梯度5:101-500笔8.00
梯度6:501-1000笔7.00
梯度7:1001-2000笔6.00
梯度8:2001-3000笔5.00
梯度9:3001-4000笔4.00
梯度10:4001-5000笔3.00
梯度11:5001-6000笔2.00
梯度12:6001笔及以上1.00
实现一个函数,用于计算用户一个月共计交费多少港元
假设一个用户,一个月交易了6笔订单,
则在梯度1交费共计: 30港元*5=150港元,
在梯度二交费:15港元,一共交
费165港元。*/
注意:要方便以后对梯度相关数据的修改
注意:要方便以后对梯度相关数据的修改
注意:要方便以后对梯度相关数据的修改
富途三面
- 节流防抖
- http缓存
- 图片懒加载
挑水卖钱
有一人有240公斤水,他想运往干旱地区赚钱。他每次最多携带80公斤,并且每前进一公里须耗水1公斤(均匀耗水)。假设水的价格在出发地为0,以后,与运输路程成正比,(即在10公里处为10元/公斤,在20公里处为20元/公斤……),又假设他必须安全返回,请问,他最多可赚多少钱?
写一个循环计算即可
答案:2400
两岸打电话
河两岸各有60w人和40w人,一天内会产生100w通电话,每通电话都是随机打的,问跨河打的有多少
分析:
等于左岸打右岸电话事件的概率 + 右岸打左岸电话事件的概率
60/100 * 40/100 + 40/100 * 60/100
答案:
40%
移动零
给定一个整数数组,请设计一个算法,将所有的0移到末尾,同时保持非0元素的相对位置。比如给定数组[0,6,9,0,22],输出应该为[6,9,22,0,0]
function swap(arr, i, j) {
let temp = arr[i]
arr[i] = arr[j]
arr[j] = temp
}
function moveZero(arr) {
let left = 0
let right = arr.length - 1
while (left < arr.length) {
if (left == 0) {
swap(arr, left, right)
right--
}
left++
}
return arr
}
测试
let arr = [0, 6, 9, 0, 22]
const res = moveZero(arr)
console.log('res', res)
声网
提供音视频服务,to D
声网一面
-
vue组件里面的data实际是放在组件内部还是全局?组件内部。
-
vue为什么data不放到全局?全局的话 diff会从root组件开始,非常消耗性能
-
对ts的了解?获取函数的返回类型 => returnType
- vue 和 react 的区别
- 对redux的了解
-
有自己写过hook吗
- webpack相关。我打包一个ui库,给vue框架使用,这个ui框会用vue上的一些api,但最终打包的时候我不希望vue打包进这个ui框架里面,该怎么做?使用externals。
- webpack的打包流程 => entry入口 建立依赖图谱 => loader => 打包生命周期中触发plugin
https://webpack.docschina.org/configuration/externals/#root
externals配置选项提供了「从输出的 bundle 中排除依赖」的方法。相反,所创建的 bundle 依赖于那些存在于用户环境(consumer’s environment)中的依赖。此功能通常对 library 开发人员来说是最有用的,然而也会有各种各样的应用程序用到它
module.exports = {
//...
externals: {
jquery: 'jQuery'
}
};
这样就剥离了那些不需要改动的依赖模块
import $ from 'jquery';
$('.my-element').animate(/* ... */);
- 场景设计相关。 历史记录 聊天框 同级组件 修改聊天框的子组件input => 按发送按钮 => 聊天框出现新的消息。vue会怎么进行更新?
声网二面
- 对 monorepo 多包单仓库开发模式的了解
- 有了解过lerna吗?
- ui库 storybook
- 看过哪些源码 (vue axios koa2)
- 你们通用组件的开发流程?
场景设计
要对所有的console.log上报,不能改变原console.log的写法,你会怎么做?
// 装饰器模式
const f = console.log
console.log = function(...args){
// 将信息放到一个全局队列,等到路由跳转前,发送请求
f(...args)
// 其他操作
}
这样做,刷新的时候,可能还是在request流程中,部分log无法上报,该怎么做?
将log存到localstorage中
这样做有什么不好吗?
用户换浏览器,换电脑的话,localstorage这部分log还是无法上报?
除了localstorage还有别的更好的解决方案没?
手写题:
获取1000个不重复的6位数
function test() {
let set = new Set()
while (set.size < 1000) {
const rand = getRandom() // 6位
set.add(rand)
}
return set
}
function getRandom() {
return Math.floor(1000000 * Math.random)
}
这里这个循环会超过1000次,有没有什么办法让循环尽可能的少?
哈希冲突的问题 => 再次hash法 => 不能完全解决这个问题,还有没有别的?
有没有了解过hash一致性?
没。。。
如果要你对这个函数做单元测试,你会怎么做?
- 是否生成1000个
- 是否每一个都是6位数
- 是否每一个都不重复
用过哪些单元测试的库?
- jest
- react-test-library
前端日志上报
- 0像素打点上传,通过构建img的src输出,在get请求拼接日志
- xhr、fetch等网络请求,主动发起网络请求,主要用于提交内容较大的日志
- script、link标签等可以发起网络请求的其他标签,与像素打点类似
- sendBeacon
当页面刷新的时候,页面卸载的时候,可能还在请求中,异步的XMLHttpRequest不能保证日志一定上报成功。该怎么做?
这种方式虽然有效,但是用户需要等待请求结束才可以关闭页面。对用户的体验不好。
Internet Explorer => No support 不兼容ie浏览器
可用于通过HTTP将少量数据异步传输到Web服务器。
这个方法还是异步发出请求,但是请求与当前页面脱钩,作为浏览器的任务,因此可以保证会把数据发出去,不拖延卸载流程。
这个方法主要用于满足统计和诊断代码的需要,这些代码通常尝试在卸载(unload)文档之前向web服务器发送数据。过早的发送数据可能导致错过收集数据的机会。然而,对于开发者来说保证在文档卸载期间发送数据一直是一个困难。因为用户代理通常会忽略在 unload 事件处理器中产生的异步 XMLHttpRequest。
为了解决这个问题, 统计和诊断代码通常要在 unload 或者 beforeunload 事件处理器中发起一个同步 XMLHttpRequest 来发送数据。同步的 XMLHttpRequest 迫使用户代理延迟卸载文档,并使得下一个导航出现的更晚。下一个页面对于这种较差的载入表现无能为力。
有一些技术被用来保证数据的发送。其中一种是通过在卸载事件处理器中创建一个图片元素并设置它的 src 属性的方法来延迟卸载以保证数据的发送。因为绝大多数用户代理会延迟卸载以保证图片的载入,所以数据可以在卸载事件中发送。另一种技术是通过创建一个几秒钟的 no-op 循环来延迟卸载并向服务器发送数据。
这些技术不仅编码模式不好,其中的一些甚至并不可靠而且会导致非常差的页面载入性能。
使用 sendBeacon() 方法会使用户代理在有机会时异步地向服务器发送数据,同时不会延迟页面的卸载或影响下一导航的载入性能。这就解决了提交分析数据时的所有的问题:数据可靠,传输异步并且不会影响下一页面的加载。此外,代码实际上还要比其他技术简单许多!
window.addEventListener('unload', logData, false);
function logData() {
navigator.sendBeacon("/log", analyticsData);
}
第一个问题:如果进行了日志上报,则每个访客都可能上报大量相同的日志,pv过大会导致日志存量极速增长,因此建议不要频繁地上传错误日志,这个问题可以通过增加日志采样率解决
function log(msg, sampling = 1){
if(Math.random() < sampling){
_log(msg)
}
}
Vue globalHandleError
非面试题,纯学习用
function globalHandleError (err, vm, info) {
if (config.errorHandler) {
try {
return config.errorHandler.call(null, err, vm, info)
} catch (e) {
logError(e, null, 'config.errorHandler')
}
}
// 没有设置config.errorHandler 会走到这里
logError(err, vm, info)
}
function logError (err, vm, info) {
if (process.env.NODE_ENV !== 'production') {
warn(`Error in ${info}: "${err.toString()}"`, vm)
}
/* istanbul ignore else */
if ((inBrowser || inWeex) && typeof console !== 'undefined') {
console.error(err)
} else {
throw err
}
}
hash 算法
什么是hash算法
哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。
链地址法(拉链法)
链接地址法的思路是将哈希值相同的元素构成一个同义词的单链表,并将单链表的头指针存放在哈希表的第i个单元中,查找、插入和删除主要在同义词链表中进行。链表法适用于经常进行插入和删除的情况。
如下一组数字,(32、40、36、53、16、46、71、27、42、24、49、64)哈希表长度为13,哈希函数为H(key)=key%13,则链表法结果如下:
0
1 -> 40 -> 27 -> 53
2
3 -> 16 -> 42
4
5
6 -> 32 -> 71
7 -> 46
8
9
10 -> 36 -> 49
11 -> 24
12 -> 64
查找、插入和删除主要在同义词链中进行,大大节省时间
- 再哈希法
就是同时构造多个不同的哈希函数: Hi = RHi(key) i= 1,2,3 … k; 当H1 = RH1(key) 发生冲突时,再用H2 = RH2(key) 进行计算,直到冲突不再产生,这种方法不易产生聚集,但是增加了计算时间。
一致性Hash算法
https://juejin.cn/post/6844903750860013576
普通的hash算法在分布式应用中的不足:
比如,在分布式的存储系统中,要将数据存储到具体的节点上,如果我们采用普通的hash算法进行路由,将数据映射到具体的节点上,如key%N,key是数据的key,N是机器节点数,如果有一个机器加入或退出这个集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了。
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n 个关键字重新映射,其中K是关键字的数量, n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
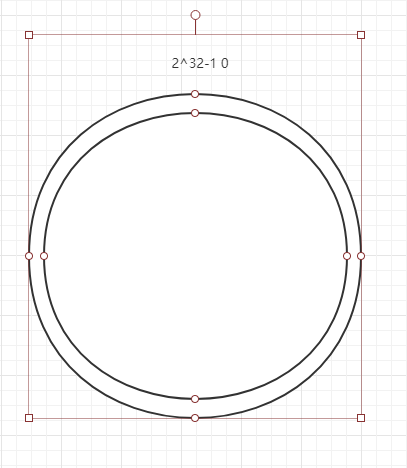
简单的说,一致性哈希是将整个哈希值空间组织成一个虚拟的圆环,如假设哈希函数H的值空间为0-2^32-1(哈希值是32位无符号整形),整个哈希空间环如下:
一致性Hash算法
均衡性(Balance)
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
单调性(Monotonicity)
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。(这段翻译信息有负面价值的,当缓冲区大小变化时一致性哈希(Consistent hashing)尽量保护已分配的内容不会被重新映射到新缓冲区。)
分散性(Spread)
在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
负载(Load)
负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
迅雷
迅雷一面
- 主要是针对简历上的项目问
手写题:
- getNumber(min,max)
- 对getNumber做单元测试
getNumber要求左闭右闭区间
function getNumber(min, max) {
return min + Math.floor(Math.random() * (max - min + 1));
}
单元测试test
例子:getNumber(1,3) => 1,2,3
- getNumber返回值x min <= x <= max
- 在大量getNumber运行中 保证每一值获取到的概率差不多
- 在大量getNumber运行中 保证每一值都能获取到
ones
复临科技
一面
- 算法 dp 找出两个字符串的最长公共子串的动态转移方程 (用途: git diff 文件diff)
- 设计模式 (常见的设计模式有哪些)
- 数据结构 (map 底层是怎么实现的)(hash表)
- https 手机要抓https的包该怎么办?(手机要安装证书)=> 证书有什么用?
- data更新时 vue 和 react 怎么去更新view的? 两者有什么差异
- html怎么最终渲染到浏览器屏幕上的
- 项目。。。
两个字符串的最长公共子串的动态转移方程
dp[i][j]表示 str1[0…i] 与 str2[0…j] 的最长公共子串的长度。
矩阵 dp 的第一列 dp[0…m-1][0].对于 某个位置(i,0)如果str1[i]==str2[0],则dp[i][0]=1,否则dp[i][0]=0
矩阵 dp 的第一行 dp[0][0…n-1].对于 某个位置(0,j)如果str1[0]==str2[j],则dp[0][j]=1,否则dp[0][j]=0
其他位置:
str1[i]==str2[j],dp[i][j]=dp[i-1][j-1]+1;
str1[i]!=str2[j]则dp[i][j]=0
灵雀云
前端用vue 和 angular 技术栈
一面
-
为什么需要Promise => Promise 和 async/await 的区别 => 怎么实现async/await (利用generator yield)=> 能具体说一下嘛? (说不出来 gg)
- 数组循环的方法 (基础for,for…of,forEach) => for…of可以遍历对象吗? (不可以 内含iterator的才可以 这里答错了) =》 哪一个循环的方式性能最好 (基础for循序) => 为什么呢?
- forEach 为什么性能差? => forEach 算函数式编程吗 => 说一下对函数式编程的理解
- css 动画 和 js动画的区别 => js动画采用setInterval实现,同时去改变data,动画会卡吗?为什么?(会 先执行同步任务在进行异步任务)=> css 动画中同时去改变data,动画会卡吗?(不会)
-
重排和重绘的区别 => transform 会导致重排和重绘吗 => (不会) transform 形成合成层,直接在非主线程中执行合成动画操作,交由 GPU 合成,比 CPU 处理要快。 => 提升合成层的最好方式是使用 CSS 的 will-change 属性
- 同时setState两次会怎么样 => 为什么setTimeout中的 setState 没办法合并
- 如何实现connect (react-redux)
- react 的 useRef,ref 有什么作用 (拿到dom节点, 回调 Refs更精细地控制何时 refs 被设置和解除 ,拿到子组件的dom节点)
实现connect (react-redux)
https://juejin.cn/post/6844903505191239694
connect是一个高阶函数,首先传入mapStateToProps、mapDispatchToProps,然后返回一个生产Component的函数(wrapWithConnect),然后再将真正的Component作为参数传入wrapWithConnect,这样就生产出一个经过包裹的Connect组件
setTimeout 结合 setState
https://segmentfault.com/q/1010000015805834
为什么setTimeout中的 setState 没办法合并? (在新版本的react已经可以合并了)
setState的“异步”并不是说内部由异步代码实现,其实本身执行的过程和代码都是同步的,只是合成事件和钩子函数的调用顺序在更新之前,导致在合成事件和钩子函数中没法立马拿到更新后的值,形式了所谓的“异步”,当然可以通过第二个参数 setState(partialState, callback) 中的callback拿到更新后的结果。
手写题两道:
// 用性能尽可能好的方法展开高阶数组并去重、按升序排序
function flatAndSort(arr) {
// your code here 老题目就不做了
// 升级:可以不用循环去实现数组扁平化吗 => arr.toString()
}
const array3 = [0, [1, 2], 10, [3, 7, 10], [[4, 5, 0], 6]]
console.log(flatAndSort(array3))
/**
* 灵雀云前端面试题:版本号排序
* 实现 sortVersions 函数,使测试用例能够返回正确的结果
*/
const versions = ['2.01', '1.10', '1.9.10', '1.10.2', '2.0', '1'];
function sortVersions(versions) {
versions.sort((a, b) => {
let arr1 = a.split('.')
let arr2 = b.split('.')
while (arr1.length < 3) {
arr1.push('0')
}
while (arr2.length < 3) {
arr2.push('0')
}
let main = parseInt(arr1[0]) - parseInt(arr2[0])
let middle = parseInt(arr1[1]) - parseInt(arr2[1])
let last = parseInt(arr1[2]) - parseInt(arr2[2])
return main || middle || last
})
return versions
}
console.log(sortVersions(versions));
// ["1","1.9.10","1.10","1.10.2","2.0","2.01"]
实现async/await
我们可以利用yield 实现 async/await
function generatorToAsync(generatorFunc) {
return (...args) => {
const gen = generatorFunc.apply(this, ...args);
return new Promise((resolve, reject) => {
const step = (key, arg) => {
let generatorResult;
try {
generatorResult = gen[key](arg);
} catch (error) {
return reject(error);
}
const { value, done } = generatorResult;
if (done) {
return resolve(value);
} else {
return Promise.resolve(value).then(
(val) => {
step("next", val);
},
(err) => {
return reject(err);
}
);
}
};
step("next");
});
};
}
测试:
const getData = () => new Promise((resolve) => setTimeout(() => resolve("data"), 1000));
function* testG() {
// await被编译成了yield
const data = yield getData();
console.log("data: ", data);
const data2 = yield getData();
console.log("data2: ", data2);
return "success";
}
const testGAsync = generatorToAsync(testG)
testGAsync().then(res=>console.log(111,res))
generatorToAsync这个函数,这是babel编译async函数的核心,当然在babel中,generator函数也被编译成了一个很原始的形式,本文我们直接以generator替代
yield 知识点
https://es6.ruanyifeng.com/#docs/generator
yield表达式本身没有返回值,或者说总是返回undefined。next方法可以带一个参数,该参数就会被当作上一个yield表达式的返回值。
async/await 和 generator 的关系
async/await 就是 generator + promise 的语法糖,还自带auto run的buff
generator函数,返回它返回一个generator 对象,需要不断的手动调用next,而async/await就不用手动调用next了,会
循环性能对比
性能: 普通 for 循环 > forEach > for of > map > for in
Iterator 相关
https://es6.ruanyifeng.com/#docs/iterator
ES6 创造了一种新的遍历命令for...of循环,Iterator 接口主要供for...of消费。
ES6 规定,默认的 Iterator 接口部署在数据结构的Symbol.iterator属性,或者说,一个数据结构只要具有Symbol.iterator属性,就可以认为是“可遍历的”(iterable)。
Symbol.iterator属性本身是一个函数,就是当前数据结构默认的遍历器生成函数。执行这个函数,就会返回一个遍历器。至于属性名Symbol.iterator,它是一个表达式,返回Symbol对象的iterator属性,这是一个预定义好的、类型为 Symbol 的特殊值,所以要放在方括号内
const obj = {
[Symbol.iterator] : function () {
return {
next: function () {
return {
value: 1,
done: true
};
}
};
}
};
上面代码中,对象obj是可遍历的(iterable),因为具有Symbol.iterator属性。
原生具备 Iterator 接口的数据结构如下。
- Array
- Map
- Set
- String
- TypedArray
- 函数的 arguments 对象
- NodeList 对象
tip:Object 不能被 for..of 遍历
css动画和js动画区别
- JS动画(逐帧动画)
在js动画是逐帧动画,是在时间帧上逐帧绘制帧内容,由于是一帧一帧的话,所以他的可操作性很高,几乎可以完成任何你想要的动画形式。但是由于逐帧动画的帧序列内容不一样,会增加制作负担,且资源占有比较大。
缺点:js是单线程的脚本语言,当js在浏览器主线程运行时,主线程还有其他需要运行的js脚本、样式、计算、布局、交互等一系列任务,对其干扰线程可能出现阻塞,造成丢帧的情况。
- css3(补间动画)
制作方法简单方便。只需确定第一帧和最后一帧的关键位置即可,两个关键帧之间帧的内容由Composite线程自动生成,不需要人为处理。当然也可以多次添加关键帧的位置。css动画更为流畅。
因为只设置几个关键帧的位置,所以在进行动画控制的时候时比较弱的。不能够在半路暂停动画,或者在动画过程中不能对其进行一些操作等。
cvte
一面
(教育 会议 音视频场景)
- 基本上都是根据项目经历来问。
- electorn用的有多深?有没有遇见什么坑?electorn多窗口使用过没?
- pnpm 对比 lerna 的优势在哪?(节约磁盘空间并提升安装速度)
- cdn直播首帧太慢怎么解决? 融合 CDN方案。 (节点快切换-节点慢恢复-节点评分一体化的调度体系)
二面
- 根据项目经历来问
- 说一下你设计的插件机制
- electorn视频渲染
- 小程序采集音视频推流
- 做过哪些有挑战性的事情
- 做过哪些性能优化的东西
手写题
/**
实现洗牌算法函数shuffle,给定一个数组[0,1,2,3,4,5,6],每次随机抽选数组的n个值,连续抽选不重复已经抽选的值,直到数组抽完,再进行下一轮循环。
示例1:
var random = shuffle([0,1,2,3,4,5,6]);
random(1); // [1]
random(1); // [0]
random(1); // [2]
random(1); // [3]
random(1); // [5]
random(1); // [4]
random(1); // [6]
random(1); // [3]
示例2:
var random = shuffle([0,1,2,3,4,5,6]);
random(1); // [1]
random(2); // [0,6]
random(1); // [2]
random(4); // [3,4,5,2]
**/
解决:
const shuffle = (arr = []) => {
// 避免修改原数组
let copyArr = arr.slice(0)
return (num = 1) => {
let result = []
for (let i = 0;i < num;i++) {
// 随机数
let random = Math.floor(Math.random() * copyArr.length)
// 从数组中取出随机数对应的值
let value = copyArr.splice(random, 1)[0]
// 如果数组为空,就重置数组
if (copyArr.length === 0) {
copyArr = arr.slice(0)
}
result.push(value)
}
return result
}
}
var data = [
{
parentId: 0,
id: 1,
value: '1'
},
{
parentId: 3,
id: 2,
value: '2'
},
{
parentId: 0,
id: 3,
value: '3'
},
{
parentId: 1,
id: 4,
value: '4'
},
{
parentId: 1,
id: 5,
value: '5'
},
{
parentId: null,
id: 0,
value: 'root'
},
];
// 请完成toTree函数将该数据整理为树状结构, 该树每个节点的结构如下,
// node: Node = {
// children: Node[],
// parentId,
// id,
// value,
// }
解决:
const toTree = (data = []) => {
// 先建立一个map 这样查找效率就是O(1)
let map = new Map();
for (let i = 0;i < data.length;i++) {
map.set(data[i].id, data[i])
}
// 建立 children 关系
for (let i = 0;i < data.length;i++) {
const curNode = data[i];
if (curNode.parentId != null) {
const node = map.get(curNode.parentId)
if (node.children) {
node.children.push(curNode)
} else {
node.children = [curNode]
}
}
}
// 返回根节点
return map.get(0)
}
金山 wps
一面
- 什么是闭包?闭包的应用场景?滥用闭包的后果?(内存泄漏)
- 哪些情况会造成内存泄漏?怎么去具体分析定位内存泄漏?
- react 类组件 和 函数组件的区别
- hook是什么?hook的优势?为什么hooks一定要顺序编写,不能放到if中?
- 网络安全?
- canvas优化手段?(分层 和 离屏渲染)
- 如何用canvas做一个文本编辑器?监听canvas元素事件?监听键盘事件?如何监听中文输入?
- 一个浏览器开两个tab 同样的网站地址如何不借助服务器通信? 通过localstorage的话,A改了B无法监听到。 (messageChannel webworker shareworker 之类)
- 做的比较有挑战性的东西?
- 首屏优化? (懒加载 骨架屏 ssr 资源压缩 减少请求 CDN)
- 什么是monorepo?为什么你的项目需要上monorepo?
- lerna 和 pnpm的比较?lerna有哪些问题?pnpm有哪些优势?
- 怎么样才能让组件渲染性能更好? (mount 和 update) (view 和 data) (组件尽可能拆的更新 这样更新的组件区域更小) (store中数据定义更合理,模块划分,component只需要监听最小需要的store数据)
- 很大的一棵redux树,更改一个很深的状态让后很深的组件渲染,这个流程中哪些地方可以优化?
虎牙
一面
- 对web rtc
- 简历项目问问
- babel插件相关?
- dfs 和 bfs 的区别?
- 两个不同内网的ip怎么进行P2P连接?TURN协议相关
- 其他
算法:
一个字符串,将里面的小写字母转为大写字母,将里面大写字母转为小写字母
欢聚时代
一面
- node.js 事件循环
- node.js 中 setImmediate vs setTimeout
- 怎么理解 node 中 nextTick
- rollup 打包为什么比 webpack 要小
- webpack 和 rollup 的tree shaking 的区别
- 怎么做一个高可用的服务 => 多路复用 => 微服务架构
- 怎么理解hooks
node相关请查看 node 面试 blog
高可用的服务
- 部署多个实例:通过在多台服务器上部署多个相同的服务实例,可以实现服务的冗余和负载均衡。当其中一台服务器发生故障时,其他实例可以接替其工作,保持服务的可用性。
- 使用负载均衡器:负载均衡器可以在多个服务实例之间分发请求,使得每个实例负载均衡。常见的负载均衡器技术包括Nginx、HAProxy等。负载均衡器还可以进行健康检查,及时排除不可用的实例。
- 数据复制和备份:将服务的数据进行实时复制和备份,以防止因为数据丢失或损坏而导致的服务中断。可以使用数据库主从复制、分布式文件系统等技术来实现数据的高可用性
- 故障监测和自动恢复:通过监测服务的各个关键组件和指标,及时发现故障并采取相应的自动恢复措施。可以使用监控工具来收集和分析服务的运行状态和性能指标,以及实施自动化的故障恢复策略。
多路复用
多路复用(Multiplexing,又称“多任务”)是一个通信和计算机网络领域的专业术语,在没有歧义的情况下,“多路复用”也可被称为“复用”。 多路复用通常表示在一个信道上传输多路信号或数据流的过程和技术。 因为多路复用能够将多个低速信道集成到一个高速信道进行传输,从而有效地利用了高速信道。
TCP的多路复用(Multiplexing)是指在一条TCP连接上同时发送和接收多个数据流(或者说多个应用层的消息)。通过多路复用,可以在一个TCP连接上同时处理多个应用层的数据,并且保证数据的顺序性和可靠性。
webpack 和 rollup 的tree shaking
https://juejin.cn/post/7169004126469914654
webpack更适合于应用,而rollup更适用于类库
Wepack5.x:
(仅仅针对模块)
Wepack 自身在编译过程中,会根据模块的 import 与 export 依赖分析对代码块进行打标。
Webpack 中截取的打标代码,可以看到主要会有两类标记,harmony export 和 unused harmony export 分别代表了有用与无用。标记完成后打包时 Teser 会将无用的模块去除。
rollup:
内部用到了 acorn => A tiny, fast JavaScript parser, written completely in JavaScript
与 Webpack 不同的是,Rollup 不仅仅针对模块进行依赖分析,它的分析流程如下:
- 从入口文件开始,组织依赖关系,并按文件生成 Module
- 生成抽象语法树(Acorn),建立语句间的关联关系
- 为每个节点打标,标记是否被使用
- 生成代码(MagicString+ position)去除无用代码
能更加正确的判断项目本身的代码是否有副作用
稿定科技
一面
css:
- 实现一行三列 => grid/flex => flex相关属性
- transform相关 => transform 先rotate在translate 和 先translate在rotate 的区别? (有区别) => transform:matrix 有了解过吗?
- canvas 如何绘制gif => 逐帧绘制(requestanimationframe)形成gif动图效果
js:
- 给一个一个promise数组如何按顺序串行执行? async/await 或者 Generator 函数控制
- 控制请求并发?
- 如何监听promise error => try/catch await 或者 window.addEventListener(‘unhandledrejection)
- 监听资源图片加载error => window.addEventListener(‘error’)
- requestanimationframe 和 setTimeout/setInterval 的区别?
- indexDB 和 localstorage 的区别? 版本升级要升级indexDB怎么办?如何查看indexDB剩余的容量
- localstorage 最大存储体积 => 5-10MB
- indexDB 最大存储体积 => 几十MB到几百MB之间
网络:
- options 请求出现时机? 跨域
- 所有跨域请求都会出现options嘛? (只有复杂请求会,简单请求不会)
- 什么是简单请求?
算法
- 给定一个正整数数组找出其中的质数。 时间复杂度是? 小于O(n2)
正整数数组先排序 => 找出最大的正整数 => 生成一个正质数set(小于前面的最大的正整数) => 比对查找
Tip: set 查找效率更高
indexDB 如何回退
IndexedDB是一个浏览器本地数据库,它不像传统的关系型数据库,支持事务回滚和撤销操作。因此,在IndexedDB中,没有直接的方式来回滚或撤销更改。
- 备份和恢复:在进行更改之前,可以先创建数据库的备份,当需要回退时,可以将备份恢复回原始状态。这需要你手动编写备份和恢复的代码。
- 保存历史记录:在每次更改之前,可以将更改前的数据或状态保存到另一个表中,这样在需要回退时,可以从历史记录中找到并恢复特定的状态。
- 使用版本控制:可以在IndexedDB的数据库结构中添加一个版本号或时间戳字段,每次进行更改时,更新版本号或时间戳。当需要回退时,可以根据版本号或时间戳查询并恢复特定的数据。
需要注意的是,以上方法都需要你手动编写代码来实现,而且在实际使用中可能会有一些限制和复杂性。因此,在设计IndexedDB应用程序时,建议提前考虑可能的回退或撤销需求,并选择合适的方法来实现。
Generator 控制 promise 执行顺序
利用for...of循环会自动依次执行yield命令的特性,提供一种更一般的控制流管理的方法。
let steps = [step1Func, step2Func, step3Func];
function* iterateSteps(steps){
for (var i=0; i< steps.length; i++){
var step = steps[i];
yield step();
}
}
unction* generatorFunction() {
yield promiseFunction1();
yield promiseFunction2();
yield promiseFunction3();
}
//promiseFunction1 promiseFunction2 promiseFunction3
function promiseFunction1() {
return new Promise((resolve, reject) => {
// promise 1 的异步操作
setTimeout(() => {
console.log("Promise 1 resolved");
resolve();
}, 1000);
});
}
// 执行 generator 函数
const iterator = generatorFunction();
let result = iterator.next();
function handlePromise(result) {
if (result.done) {
console.log("All promises resolved");
return;
}
result.value.then(() => {
const nextPromise = iterator.next();
handlePromise(nextPromise);
});
}
handlePromise(result);
rotate结合translate
先rotate再translate表示在物体旋转后再沿某个方向移动。这意味着,在旋转过程中,物体的中心点保持不变,只是方向改变,然后再以新的方向进行平移。这种顺序下,平移的向量会受到旋转的影响,因为旋转改变了坐标系的方向。
先translate再rotate表示在物体平移后再进行旋转。这意味着,在平移过程中,物体的中心点也会随着平移而改变,此时进行旋转操作,会绕着新的中心点进行旋转。这种顺序下,旋转的角度和中心点不会受到平移的影响,因为平移并不改变坐标系的方向,只会改变物体的位置。
具体来说,先rotate再translate会先进行旋转变换,再进行平移变换,而先translate再rotate会先进行平移变换,再进行旋转变换。这两种变换的顺序不同,会产生不同的视觉效果。
安克 Anker
暂无面试
柚乐科技
一面
- 项目相关?
- 做过哪些性能优化? (代码优化和工作流优化)
- 用过哪些设计模式?
- tree-shaking 的过程?
- vite和webpack的区别? 为什么vite的热更新更快?
react相关:
- fiber架构?
- 如何实现的中断可恢复机制?
- 父组件中有A/B 两个组件,A组件props是name,B组件props是id,当父组件name改变时B组件会更新吗?
- 为什么需要合成事件? (兼容性和性能)
- 写自定义hooks需要注意哪些
- 有没有遇见组件异常更新的情况 (useEffect中dependencies太多且错误的情况)
默认情况下,当一个组件重新渲染时,React 会递归地重新渲染它的所有子组件。
React.memo 是一个高阶组件,用于优化函数组件的性能。它通过对组件的 props 变化进行浅比较,来决定是否重新渲染组件。
- 减少不必要的渲染:在父组件渲染时,如果子组件的 props 没有变化,
React.memo可以阻止子组件的重新渲染。这在组件树较大或者渲染开销较高的情况下特别有用,可以提升性能。 - 提高性能:对于一些频繁更新的父组件,如果子组件的 props 很少变化,使用
React.memo可以大幅度降低渲染频率,从而提高应用的响应速度。 - 优化函数组件:
React.memo只适用于函数组件,而对于类组件,React 本身已经包含了生命周期方法来管理渲染,因此不需要使用React.memo。
外企
福里斯
一家做区块链的外企
一面
- es6新语法 (map 和 weakmap 区别) (箭头函数有没有arguements对象)=》 weakmap的实际应用
- 浏览器事件循环 => node事件循环和浏览器事件循环有区别吗 => 微任务和宏任务
- js 垃圾回收机制 (新生代 老生代)
- 浏览器渲染原理 => 生成css tree 和 dom tree的过程是并行的吗 (是并行的)
- v8原理 =》 怎么执行js的 (解析器 解释器 热代码 优化和反优化 JIT)
- babel 原理 =》 transform,ast处理 ,generate
- 缓存相关 => 哪些request header 和缓存有关 => 什么时候会触发 304
- http2的特点 =》 什么是队头阻塞 =》 为什么http1.1这种会有队头阻塞 =》 有没有使用node支持过http2
- 层叠上下文相关 =》 合成层 渲染层 =》 如果一个元素z-index设置很大 还是被其他元素盖住怎么排查
- 浏览器内存泄漏 => node 内存泄漏
- node 利用多核cpu性能
- 父元素高度塌陷怎么恢复 => 清除浮动 => 除了清除浮动还能有别的方式吗
- 盒模型的理解
- 常见的布局 =》 flex,grid 布局
- 适配 h5 和 pc (@media)
- vue的响应式原理 =》 对viewModel的理解 =》 v-model 的实现
- Object.defineProprty => proxy
- vue的diff算法 =》 双数组对比 (前前 后后 交叉)=》 diff的时间复杂度 O(n)
- 对virtual dom的理解
- weback4 => webpack5 => webpack5 新特性
- vite 和 webpack 的区别 => vite的原理
- 那个项目成长最多介绍一下 =》 做了哪些东西让你成长
- 平时有没有去关注请求的数量 时序 大小之类
- 对区块链的理解
- 对比特币的理解
二面
(跪了 分析大概率是技术之外的因素 比如英语 比如有更合适的人)
- https 的安全性体现在哪? => 非对称加密为什么会比对称加密更慢?
- 最近在看什么书
- 英语能力
- 项目中的挑战
- 项目中的成长
为什么非对称加密比对称加密慢
这是因为对称加密主要的运算是位运算,比如AES,速度非常快,如果使用硬件计算,速度会更快。
非对称加密计算一般都比较复杂,比如 RSA,它里面涉及到大数运算(大数乘法、大数模)等等运算。(公钥加密后只能用私钥解密,反过来,私钥加密后也只能用公钥解密,公钥可以任意分发而私钥保密。)
密码的大小:对称加密不会增加密码的大小(渐近),但非对称加密会。
Binance
币安(币圈头部最大公司)(已拿offer要去迪拜 犹豫再三拒绝了)
一面
- 组件库 全局引入 和 局部引入的问题 => 按需引入组件(babel-import 和 node-import)
- tree shaking 相关
- 浏览器缓存 (强缓存 和 协商缓存)
- html缓存 => html需要缓存吗? => 如何干掉html的缓存 (nginx 配置)
- lerna相关 => 如果包体过多怎么办 ? => lerna 第一次install速度过慢
- 小程序 和 jsbridge的区别
- 栅格布局 => flex 和 grid 布局 => 如何实现 2 * 2 布局
- webpack 中 loader和plugin 的区别 => webpack排除依赖 (externals)
- webpack_require 实现原理
- 什么是 ast => 介绍一下做的ast工具
- react相关 => 常见的hooks => useEffect相关 => useMemo 和 useCallback
- react 的diff过程
- 如何实现改变一个对象的属性同时去修改dom元素上的值 (Object.defineProprty)
- 如何实现一个简单的reducx => connect 怎么实现的
手写题:
- 节流防抖
二面
- 非技术 (给自己三个tag便签 最近在看什么书 在看什么文章 分享一下最近印象深刻的学习内容)
- react 的 setState 运行机制 => 为什么在setTimeouot里面的setState是同步执行的?
- react 的 hooks 为什么要保证一定的顺序 不可以写到if里面
- webpack打包过程 => webpack 动态 import 原理 => 动态import的module 怎么插到webpack 的 modules中
- webpack的路径查找过程 (npm 相对路径 绝对路径)
- webpack 的 hmr 热更新原理 (WebSockets) => 说一下具体细节
- 。。。
手写题三道:
- useCountdown(num) 实现倒计时
实现:利用setInterval
function useCountdown(num) {
const [total, setTotal] = useState(num);
useEffect(() => {
let timer = setInterval(() => {
setTotal((cur) => {
// 利用setState函数形式拿到最新值
if (cur <= 0) {
clearInterval(timer);
return 0;
}
return cur - 1;
});
}, 1000);
return () => {
clearInterval(timer);
};
}, []);
return total;
}
setInterval 并不是严格间隔一秒钟的,有什么优化方案吗?
实现:在requestAnimationFrame中用两次Date差异对比
function useCountdown(num) {
const [total, setTotal] = useState(num);
const [date, setDate] = useState(+new Date());
useEffect(() => {
const calc = () => {
let nowDate = +new Date();
let temp = 60 * 1000 - (nowDate - date);
if (temp < 0) {
return;
}
setTotal(parseInt(temp / 1000));
requestAnimationFrame(calc);
};
requestAnimationFrame(calc);
}, []);
return total;
}
-
add 和 remove class
element.classList.remove('run-animation')
setTimeout(()=>{
element.classList.add('run-animation')
},0)
为什么需要setTimeout? Promise.then为什么不行?如果不延时能实现嘛?
- consumeTasks(tasks, limit) 控制并发
/**
* create a async function that would be completed after certain seconds
*/
function createTask(n, second) {
return () => {
return new Promise((resolve) => {
setTimeout(() => {
console.log(`finish task ${n}`);
resolve();
}, second * 1000);
});
};
}
/**
* Run the tasks collection of functions in parallel, but runs a maximum of limit async operations at a time.
*
* @param {*} coll A collection of async functions to run. Each async function can complete with any number of optional result values.
* @param {*} limit The maximum number of async operations at a time.
*/
async function consumeTasks(tasks, limit) {
return new Promise((resolve, reject) => {
let result = new Array(tasks.length);
let finished = new Array(tasks.length).fill(false);
let cur = 0;
const next = () => {
let task = tasks.shift();
task().then(
(res) => {
result[cur] = res;
finished[cur] = true;
cur++;
if (!finished.includes(false)) {
return resolve(result);
}
if (tasks.length) {
next();
}
},
(rej) => {
cur++;
reject(rej);
}
);
};
for (let i = 0; i < limit; i++) {
next();
}
});
}
const input = [3, 1, 3, 10, 2, 2, 1, 4].map((t, i) => createTask(i + 1, t));
const res = consumeTasks(input, 2);
console.log(res);
// with the given input, output should be: 2 1 3 5 6 7 4 8
三面
- 有遇见过内存泄漏的情况吗 => 怎么样定位有没有存在内存泄漏 => 哪些情况会导致内存泄漏
- 如何定位有性能问题的组件?
-
长列表优化 => 虚拟列表 => 虚拟列表的key可以复用吗,当元素移出屏幕外(不可以)=> 虚拟列表滚动的时候保证底下的item平滑移动 (transform)=> 列表如何在一定的区域滚动 (外部一个wrapper 内部overflow:scrollY) => 。。。
- 首屏有一个k线图组件还有一些别的组件,怎么让k线图最快显示 (类似FMP了) (别的组件动态加载,k线图组件直接加载,请求的优先级最高,同时用一些策略减少白屏时间)
- k线图组件通过WebStock不断接受数据js计算让后去渲染,怎么样让渲染更流畅? (web worker 处理复杂计算 requestAnimationFrame css硬件加速 canvas)
-
canvas为什么快? => canvas的优化手段 (离屏渲染 局部渲染)
- 有一个上层sdk依赖另外一个底层sdk,怎么保证上层sdk执行时底层sdk已经加载好了呢,底层sdk不能打包进上层sdk (webpack externals + peerDependencies) => 如果底层sdk是CDN的方式,怎么办? (相当于自己实现类
webpack__require__的东进西 require的同时 把module export等传入 同时内部有控制逻辑 实现一套类webpack runtime) - 有一个sdk(适配web 和 pc)希望打包只有web api的版本和pc api的版本 (设置两个entry:web entry 和 pc entry)=》 你这么说的是代码拆的比较干净的情况,如果有胶水层,或者同构代码的形式拆不干净怎么办 (类似umi的解决方案 搞一个parser解析器 拆不干净的代码可以用注释包裹 用parser分析解析处理)
- 写过webpack plugin没 (没有了解原理,写过babel的plugin) => 介绍一下怎么写一个babel的plugin
- 小程序性能优化手段 => wss 为什么执行效率高?
-
什么是动态规划? => 0-1 背包问题 的 动态转移方程
- 英语水平怎么样 (哭了 以后得练)
- 你想要在团队内推广一个新技术怎么去做? (ab test 灰度 小范围给到用户,收集指标数据,用数据说话)
- 你在团队里的角色 (核心 技术攻坚)
- 除了web 还有什么技术擅长
- 怎么去学习一项新技术? 有没有做过技术分享?
Brix 电鸭平台
平台对个人进行了解 在推给相应的企业
-
深挖项目
- 前端性能优化 (运行时 编译时)
- vue响应式 和 mobx响应式的区别
- 写过哪些自定义hooks
- react diff 过程 => 很深的组件 setState 怎么跳过对比
- vue 和 react的区别
- h5 和 app 通信 => url schme => 如果url的长度过长怎么办?
- 前端安全问题 => csrf 和 xss => 怎么触发csrf => cookies 同源策略
- 英语能力怎么样
EPAM 亿磐
一面
基础:
- this指向有几种 (new/显式/隐式)
- Promise any vs race 区别 => forEach可以串行执行Promise数组吗?(不行,使用for-of) => Promise 实现原理 (@babel/polyfill里面实现了 core-js里面实现了)
- error 捕获和处理
- https 建立连接的过程 (对称加密和非对称加密)
- 输入url到页面最终渲染的过程
- 如何使元素垂直居中 => 如果是flex实现的需要设置哪些值
- 网站安全问题有哪些 => 如何防范
- 什么是闭包 => 闭包的危害
- Even Loop => js长任务如何打断
- 什么是virtual dom => 它的优势是?
- ts中interface和type的区别
- ts中any和unknow的区别
- ts中什么时候回用到never
- html5 新增了什么 (新语义元素header/footer/article,表单控件的改进,多媒体支持audio/video)
- context 和 全局状态管理库的区别 => 什么时候用context 什么时候用全局状态管理库 => context的缺点
其他:
- 瀑布式开发(Waterfall) 和敏捷开发的区别
- 函数式编程(FP)和面向对象编程(OOP)区别 => 什么是纯函数
- git rebase 和 merge 的区别
- 当提交了5个记录中间三个记录是错误的怎么处理 (git cherry-pick)
- 日常工作 (版本迭代/需求评审/工作安排)
- 测试工作 项目中除了单元测试还有做了哪些测试(QA功能测试/实验室音视频质量测试/npm sdk集成测试)=> 单元测试的覆盖率 (80-85) 谁定的指标 什么依据
算法:
- 去重字符串中的重复子字符串
- 写一个可以获取url中具体query值的函数
// 去重字符串中的重复子字符串
function removeDuplicate(str) {
let result = '';
for (let i = 0; i < str.length; i++) {
if (str[i] !== str[i + 1]) {
result += str[i];
}
}
return result;
}
// "asdddvevfffxxxo" => "asdvevfxo"
let str = 'asdddvevfffxxxo';
const res = removeDuplicate(str);
console.log('res', res);
// 写一个可以获取url中具体query值的函数
function getQuery(url, name) {
const search = url.split('?')[1];
if (search) {
const arr = search.split('&');
for (let i = 0; i < arr.length; i++) {
const item = arr[i].split('=');
if (item[0] === name) {
return item[1];
}
}
}
}
const url = 'http://www.baidu.com?name=123&age=456';
const res = getQuery(url, 'name');
console.log('res', res);
补充
在面试过程中的手写题,只需要写出核心算法,也就是题目考点,其他无关紧要的东西(如:边界判断)可以暂时先不写,这样做可以节省很多时间,之后等面试官提示后在去完善答案。
后端能力 和 英语能力 格外的重要
基本上所有好的公司都需要前端有一定的后端能力 也就是 大前端方向。(今后一定得补上这个)
总结
第一轮偏重前端基础,第二轮偏重项目设计还有简历细节,第三轮主要是针对某一方向深入挖掘和有点压力面得感觉。
- 一面面试官一般为前端leader,考察前端知识 (大厂的话会是你的同事)
- 二面面试官一般为技术负责人,很大概率他是cto,技术总监,并不是前端的leader,所以他的考察点主要在于你对一个问题的思考过程,你的解决方案,你的计算机基础等
- 大厂面试会对算法进行考察,前端对标LeetCode的medium难度,想要进大厂算法一定要花时间去学习
- 基础知识一定要稳,基础知识问题在面试中答不出来会扣分很多
经过几家面试下来,也大概清楚自己在市场的位置
hr会根据你的毕业年限来压你的薪资,这也是没有办法的事情,毕竟工作经验不够(按理来说工作时间越长工资越高)
2020
2020是非常艰难的一年,受疫情影响,很多中小型公司倒闭,很多人二月份只有几天的工资。
对于我来说,疫情期间可以远程面试,是一个跳槽的绝好机会。
就我感觉疫情对整个大环境是有冲击的,但是对互联网it行业来说影响并没有想象中的大。
我持续面试了一个半月,总共面了7 8家公司,拿到了4个offer左右,最终选择的是晓教育的offer做线上教育。
当时想法: 拘泥于广州,不想搬家,后来回头来看确实这个决定有点草率
2021
2021.2.22
2021年手上有三家比较好的offer
富途: 工资最低 性价比不高 (拒绝后 加薪2k)
腾讯:pcg 看点部门 此部门风评不好 感觉做的东西不是自己喜欢 可能也就是螺丝工 (狠下心来拒绝)
声网:ad视频会议相关吧 to D 以及 low code 低代码平台 (接受)
分析一下心理的想法,深圳腾讯并不比声网base高多少,腾讯感觉应该会很辛苦,深圳南山那块房租3k左右生活成本高,声网base可以广州,感觉声网的舞台也足够当前的自己成长,感觉没必要只是为了腾讯的title镀金
另外一个原因的话是我在晓教育的base偏低,银行流水拉胯,遵循内心的想法还是想在广州稳定下来。
遂最终选择声网的offer
2022
疫情的影响,上海封城两个多月,国内经济大环境太差,大厂纷纷裁员。
面试情况:字节面试通过但hr面试后offer审批没有下来,外企基本都需要英语口语交流能力(挂在了英语方面,以后得加强英语学习),币圈拿了币安的offer但最终拒绝了(需要出国迪拜家里人不同意,怕安全问题)
遂最终选择继续苟在声网
2023
苟在声网的一年,业务平淡,公司动荡,未来迷茫,公司失去长期目标,转为拉客户打价格战。技术上居安思危,保持成长,不断研究一些东西。
2024
苟在声网,声网常年亏损,业务收缩,还是逃不过年底的裁员一刀,拿了大礼包休息一个月,12月开始面试,12月底拿到腾讯TME和一些小厂offer,整体大环境还是差,依旧寒冬。