“Yeah It’s on. ”
Vue
什么是虚拟 DOM
虚拟 DOM本质上是 JavaScript 对象,这个对象就是更加轻量级的对 DOM 的描述。
对于 DOM 这么多属性,其实大部分属性对于做 Diff 是没有任何用处的,所以如果用更轻量级的 JS 对象来代替复杂的 DOM 节点,然后把对 DOM 的 diff 操作转移到 JS 对象,就可以避免大量对 DOM 的查询操作。这个更轻量级的 JS 对象就称为 Virtual DOM 。
- 维护一个使用 JS 对象表示的 Virtual DOM,与真实 DOM 一一对应
- 对前后两个 Virtual DOM 做 diff ,生成变更(Mutation)
- 把变更应用于真实 DOM,生成最新的真实 DOM
传统前端的编程方式是命令式的,直接操纵 DOM,告诉浏览器该怎么干。这样的问题就是,大量的代码被用于操作 DOM 元素,且代码可读性差,可维护性低。
将命令式变成了声明式,摒弃了直接操作 DOM 的细节,只关注数据的变动,DOM 操作由框架来完成,从而大幅度提升了代码的可读性和可维护性,意义在于为你掩盖底层的 DOM 操作,可以渲染到 DOM 以外的端,使得框架跨平台,比如 ReactNative,React VR 等。
在初期我们可以看到,数据的变动导致整个页面的刷新,这种效率很低,因为可能是局部的数据变化,但是要刷新整个页面,造成了不必要的开销。
所以就有了 Diff 过程,将数据变动前后的 DOM 结构先进行比较,找出两者的不同处,然后再对不同之处进行更新渲染。
但是由于整个 DOM 结构又太大,所以采用了更轻量级的对 DOM 的描述—虚拟 DOM。
不过需要注意的是,虚拟 DOM 和 Diff 算法的出现是为了解决由命令式编程转变为声明式编程、数据驱动后所带来的性能问题的。换句话说,直接操作 DOM 的性能并不会低于虚拟 DOM 和 Diff 算法,甚至还会优于。
这么说的原因是因为 Diff 算法的比较过程,比较是为了找出不同从而有的放矢的更新页面。但是比较也是要消耗性能的。而直接操作 DOM 就是有的放矢,我们知道该更新什么不该更新什么,所以不需要有比较的过程。所以直接操作 DOM 效率可能更高。
Virtual DOM的优势不在于单次的操作,而是在大量、频繁的数据更新下,能够对视图进行合理、高效的更新。这一点是原生操作远远无法替代的。
虚拟 DOM 的缺点
- 首次渲染大量 DOM 时,由于多了一层虚拟 DOM 的计算,会比 innerHTML 插入慢。
- 虚拟 DOM 需要在内存中的维护一份 DOM 的副本(更上面一条其实也差不多,上面一条是从速度上,这条是空间上)。
- 如果虚拟 DOM 大量更改,这是合适的。但是单一的,频繁的更新的话,虚拟 DOM 将会花费更多的时间处理计算的工作。所以,如果你有一个 DOM 节点相对较少页面,用虚拟 DOM,它实际上有可能会更慢。但对于大多数单页面应用,这应该都会更快。
父子组件的执行顺序是什么
在组件开始生成到结束生成的过程中,如果该组件还包含子组件,则自己开始生成后,要让所有的子组件也开始生成,然后自己就等着,直到所有的子组件生成完毕,自己再结束。“父亲”先开始自己的created,然后“儿子”开始自己的created和mounted,最后“父亲”再执行自己的mounted。
为什么会这样,到这里我们就应该发现了,new Vue的时候是先执行initData,也就是初始化数据,然后执行$mounted,也就是new Watcher。而初始化数据的时候,也要处理components里的数据。处理component里的数据的时候,每处理一个子组件就会new Vue,生成一个子组件。因此是顺序是这样的。也就对应了上面的答案。
- 初始化父组件数据
- 初始化 子组件数据
- new 子组件Wacther
- new 父组件Watcher
为什么需要虚拟dom diff
既然vue通过数据劫持可以精确探测数据在具体dom上的变化,为什么还需要虚拟dom diff?
答案:
现代前端框架有两种方式侦测变化,一种是pull,一种是push
- pull其代表为react,我们可以回忆一下react是如何侦测到变化的,我们通常会用setState Api显式更新,然后 React会进行一层层的 Virtual dom diff操作找出差异,然后 Patch到DOM上, React从一开始就不知道到是哪发生了变化,只是知道「有变化了」,然后再进行比较暴力的Diff操作查找「哪发生变化了」,另外一个代表就是 Angular的脏检查操作
- push:vue的响应式系统则是push的代表,当vue程序初始化的时候就会对数据data进行依赖的收集,一但数据发生变化,响应式系统就会立刻得知。因此vue是一开始就知道是「在哪发生变化了」,但是这又会产生一个问题,如果你熟悉ue的响应式系统就知道,通常一个绑定一个数据就需要一个 Watcher。一但我们的绑定细粒度过高就会产生大量的 Watcher,这会芾来內存以及依赖追踪的开销,而细粒度过低会无法精准侦测变化因此vue的设计是选择中等细粒度的方案在组件级别进行push侦测的方式也就是那套响应式系统通常我们会第一时间侦测到发生变化的组件然后在组件内部进行Virtual dom diff获取更加具体的差异,vue是push+pull结合的方式进行变化侦测的。
v-show 与 v-if 区别
- v-hsow和v-if的区别: v-show是css切换,v-if是完整的销毁和重新创建。
- 使用 频繁切换时用v-show,运行时较少改变时用v-if
- v-if=‘false’ v-if是条件渲染,当false的时候不会渲染
绑定 class 的数组用法
-
对象方法
v-bind:class="{'orange': isRipe, 'green': isNotRipe}" -
数组方法
v-bind:class="[class1, class2]" -
行内
v-bind:style="{color: color, fontSize: fontSize+'px' }"
组件中 data 为什么是函数
为什么组件中的 data 必须是一个函数,然后 return 一个对象,而 new Vue 实例里,data 可以直接是一个对象?
因为组件是用来复用的,JS 里对象是引用关系,这样作用域没有隔离,而 new Vue 的实例,是不会被复用的,因此不存在引用对象的问题。
vm.$set 原理
查看源码
Vue.prototype.$set = set;
/**
* Set a property on an object. Adds the new property and
* triggers change notification if the property doesn't
* already exist.
*/
function set (target, key, val) {
if (process.env.NODE_ENV !== 'production' &&
(isUndef(target) || isPrimitive(target))
) {
warn(("Cannot set reactive property on undefined, null, or primitive value: " + ((target))));
}
if (Array.isArray(target) && isValidArrayIndex(key)) {
// 是数组 有有效的index
target.length = Math.max(target.length, key);
// splice 已经是 被修改过的splice方法
target.splice(key, 1, val);
return val
}
if (key in target && !(key in Object.prototype)) {
target[key] = val;
return val
}
// 拿到observer
var ob = (target).__ob__;
// 不是响应式数据
if (!ob) {
target[key] = val;
return val
}
defineReactive$$1(ob.value, key, val);
ob.dep.notify();
return val
}
vue中在哪个阶段进行异步请求比较合适
前端页面路由的权限实现
Vue.extend 是什么
在平时的代码中该方法我们主动调用的不多,但是在我们注册组件的时候,比如,Vue.component(‘my-component’, options),这个时候会自动调用 Vue.extend
一言以蔽之, Vue.extend 接受参数并返回一个构造器,new 该构造器可以返回一个组件实例。
Vue template 编译的理解
Vue 中 template 就是先转化成 AST 树,再得到 render 函数返回 VNode(Vue 的虚拟 DOM 节点)。
- 通过 compile 编译器把 template 编译成 AST 语法树(abstract syntax tree - 源代码的抽象语法结构的树状表现形式),compile 是 createCompiler 的返回值,createCompiler 是用以创建编译器的。另外 compile 还负责合并 option。
- AST 会经过 generate(将 AST 语法树转换成 render function 字符串的过程)得到 render 函数,render 的返回值是 VNode,VNode 是 Vue 的虚拟 DOM 节点,里面有标签名、子节点、文本等待。
vue的key
key 的作用就是在更新组件时判断两个节点是否相同。相同就复用,不相同就删除旧的创建新的。
对于 diff 过程来说 key 是起不到提速作用的
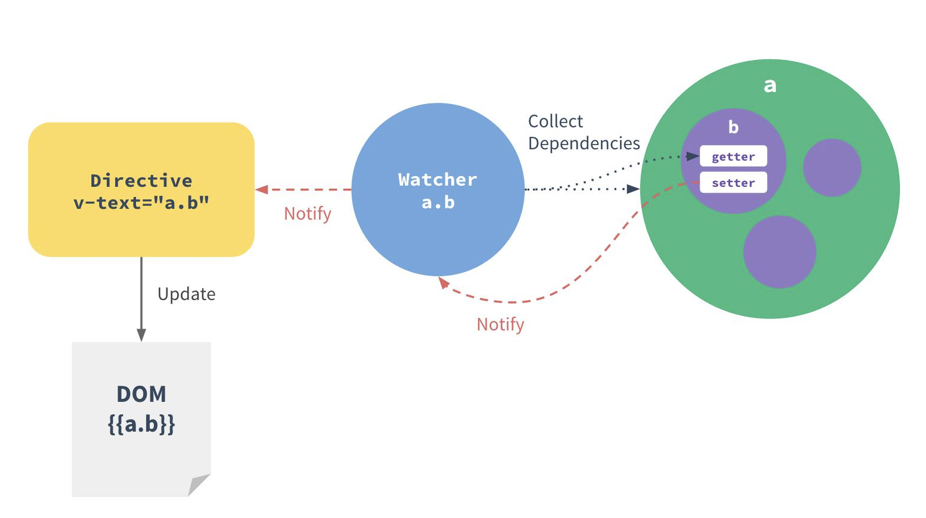
Vue 响应式原理
在 Vue 的初始化中,会先对 props 和 data 进行初始化
在 Object.defineProperty 中自定义 get 和 set 函数,并在 get 中进行依赖收集,在 set 中派发更新。
依赖收集
依赖收集是通过 Dep 来实现的,但是也与 Watcher 息息相关
对于 Watcher 来说,分为两种 Watcher,分别为渲染 Watcher 和用户写的 Watcher。渲染 Watcher 是在初始化中实例化的。
派发更新
改变对象的数据时,会触发派发更新,调用 Dep 的 notify 函数
Object.defineProperty 中的缺陷
如果通过下标方式修改数组数据或者给对象新增属性并不会触发组件的重新渲染,因为 Object.defineProperty 不能拦截到这些操作,更精确的来说,对于数组而言,大部分操作都是拦截不到的,只是 Vue 内部通过重写函数的方式解决了这个问题。
Dep.target什么时候存在
Dep.target是由依赖赋值的。依赖又称为Watcher(侦听者)或者订阅者。在Vue中有三种依赖,其中两种是很常见的,就是watch(侦听器)和computed(计算属性)。还有一种隐藏的依赖———渲染Watcher,在模板首次渲染的过程中创建的。
Dep.target是在依赖创建时被赋值,依赖是用构造函数Watcher创建。
function Watcher(vm, expOrFn, cb, options, isRenderWatcher) {
//...
if (typeof expOrFn === 'function') {
this.getter = expOrFn;
} else {
this.getter = parsePath(expOrFn);
}
this.value = this.lazy ? undefined : this.get();
};
Watcher.prototype.get = function get() {
pushTarget(this);
try {
value = this.getter.call(vm, vm);
} catch (e) {
}
return value
};
Dep.target = null;
var targetStack = [];
function pushTarget(target) {
targetStack.push(target);
Dep.target = target;
}
在构造函数Watcher最后会执行实例方法get,在实例方法get中执行pushTarget(this)中给Dep.target赋值的。
而依赖是在Vue页面或组件初次渲染时创建,所以产生的性能问题应该是首次渲染过慢的问题。
Vue 不能检测数组和对象的变化
https://cn.vuejs.org/v2/guide/reactivity.html#ad
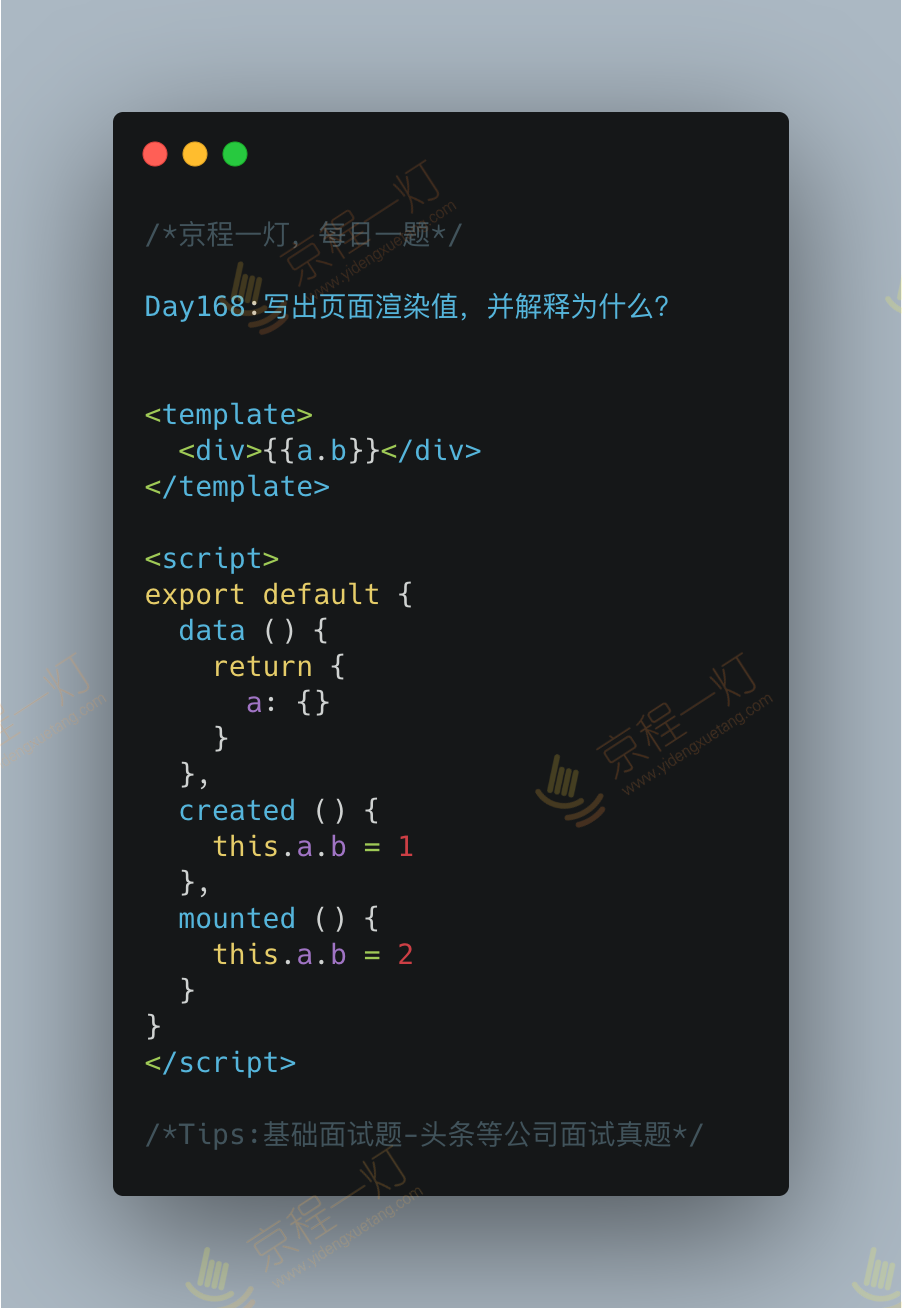
答案:1
解释:
- a.b 是没有经过Object.defineproperty() 所有更改a.b 不会触发render() 不会更新视图
- created是在视图未渲染的时候直接对对象a的属性b赋值data里面的初值会改变,但是在mounted里面更新b是非响应式的,所以视图不会渲染 (created 和 mounted 的区别)
var vm = new Vue({
data:{
a:1
}
})
// `vm.a` 是响应式的
vm.b = 2
// `vm.b` 是非响应式的
为什么Vue使用异步更新队列?
https://github.com/berwin/Blog/issues/22
异步更新队列指的是当状态发生变化时,Vue异步执行DOM更新。
我们在项目开发中会遇到这样一种场景:当我们将状态改变之后想获取更新后的DOM,往往我们获取到的DOM是更新前的旧DOM,我们需要使用vm.$nextTick方法异步获取DOM,例如:
Vue.component('example', {
template: '<span></span>',
data: function () {
return {
message: '没有更新'
}
},
methods: {
updateMessage: function () {
this.message = '更新完成'
console.log(this.$el.textContent) // => '没有更新'
this.$nextTick(function () {
console.log(this.$el.textContent) // => '更新完成'
})
}
}
})
我们都知道这样做很麻烦,但为什么Vue还要这样做呢?
首先我们假设Vue是同步执行DOM更新,会有什么问题?
如果同步更新DOM将会有这样一个问题,我们在代码中同步更新数据N次,DOM也会更新N次,伪代码如下:
this.message = '更新完成' // DOM更新一次
this.message = '更新完成2' // DOM更新两次
this.message = '更新完成3' // DOM更新三次
this.message = '更新完成4' // DOM更新四次
但事实上,我们真正想要的其实只是最后一次更新而已,也就是说前三次DOM更新都是可以省略的,我们只需要等所有状态都修改好了之后再进行渲染就可以减少一些无用功。
而这种无用功在Vue2.0开始变得更为重要,Vue2.0开始引入了Virtualdom,每一次状态发生变化后,状态变化的信号会发送给组件,组件内部使用VirtualDOM进行计算得出需要更新的具体的DOM节点,然后对DOM进行更新操作,每次更新状态后的渲染过程需要更多的计算,而这种无用功也将浪费更多的性能,所以异步渲染变得更加至关重要。
那如何才能将渲染操作推迟到所有状态都修改完毕呢?很简单,只需要将渲染操作推迟到本轮事件循环的最后或者下一轮事件循环。也就是说,只需要在本轮事件循环的最后,等前面更新状态的语句都执行完之后,执行一次渲染操作,它就可以无视前面各种更新状态的语法,无论前面写了多少条更新状态的语句,只在最后渲染一次就可以了。
将渲染推迟到本轮事件循环的最后执行渲染的时机会比推迟到下一轮快很多,所以Vue优先将渲染操作推迟到本轮事件循环的最后,如果执行环境不支持会降级到下一轮。
当然,Vue的变化侦测机制决定了它必然会在每次状态发生变化时都会发出渲染的信号,但Vue会在收到信号之后检查队列中是否已经存在这个任务,保证队列中不会有重复。如果队列中不存在则将渲染操作添加到队列中。
Vue2引入VirtualDOM的真实原因
一个状态对应某个组件,而不再是具体标签,这样做有一个好处是可以大大降低依赖的数量,毕竟组件的数量与DOM中的具体标签比,数量要少的多。但是这样就需要多一个操作,当状态发生变化只通知到组件,那么组件内部如何知道具体更新哪个DOM标签?
答案是VirtualDOM。
也就是说,当粒度调整为中等之后,需要多一个操作就是在组件内部使用VirtualDOM去重新渲染。
Vue很聪明地通过变化侦测+VirtualDOM这两种技术方案,提升了框架运行的性能问题。
所以说,Vue2.0引入VirtualDOM并不是因为VirtualDOM有多好,而是恰好VirtualDOM结合变化侦测可以将绑定调整成中等粒度来解决依赖追踪的开销问题。
依赖属性收集依赖
初始化时,页面渲染会将“渲染Watcher”入栈,并挂载到Dep.target
在页面渲染过程中遇到计算属性,对其取值,因此执行 watcher.evaluate 的逻辑,接着调用 this.get:
get () {
// 1
pushTarget(this)
let value
const vm = this.vm
try {
// 2
value = this.getter.call(vm, vm) // 计算属性求值
} catch (e) {
if (this.user) {
handleError(e, vm, `getter for watcher "${this.expression}"`)
} else {
throw e
}
} finally {
popTarget()
this.cleanupDeps()
}
return value
}
Dep.target = null
let stack = [] // 存储 watcher 的栈
export function pushTarget(watcher) {
stack.push(watcher)
Dep.target = watcher
}
export function popTarget(){
stack.pop()
Dep.target = stack[stack.length - 1]
}
很重要的一点 watcher 会形成一个栈
pushTarget 轮到“计算属性Watcher”入栈,并挂载到Dep.target,此时栈中为 [渲染Watcher, 计算属性Watcher]
this.getter 对计算属性求值,在获取依赖属性时,触发依赖属性的 数据劫持get,执行 dep.depend 收集依赖(“计算属性Watcher”)
计算属性Watcher => 依赖data的监听方法get (get的依赖收集)
实际上是defineReactive中的get方法的dep.depend()将computed的watcher推入依赖data的dep的sub队列中
收集渲染Watcher
this.getter 求值完成后popTragte,“计算属性Watcher”出栈,Dep.target 设置为“渲染Watcher”,此时的 Dep.target 是“渲染Watcher”
if (Dep.target) {
watcher.depend()
}
watcher.depend 收集依赖:
depend() {
let i = this.deps.length
while (i--) {
this.deps[i].depend()
}
}
deps 内存储的是依赖属性的 dep,这一步是依赖属性收集依赖(“渲染Watcher”)
经过上面两次收集依赖后,依赖属性的 subs 存储两个 Watcher,[计算属性Watcher,渲染Watcher]
- 渲染Watcher的
this.getter是一个函数如下所示:
updateComponent = function() {
vm._update(vm._render(), hydrating);
};
其中vm._render()会把template模板生成的渲染函数render转成虚拟DOM(VNode):vnode = render.call(vm._renderProxy, vm.$createElement);
为什么依赖属性要收集渲染Watcher
模板内只用到计算属性
<template>
<div></div>
</template>
export default {
data(){
return {
msg: 'hello'
}
},
computed:{
msg1(){
return this.msg + ' world'
}
}
}
模板上没有使用到依赖属性,页面渲染时,那么依赖属性是不会收集 “渲染Watcher”的。此时依赖属性里只会有“计算属性Watcher”,当依赖属性被修改,只会触发“计算属性Watcher”的 update。而计算属性的 update 里仅仅是将 dirty 设置为 true,并没有立刻求值,那么计算属性也不会被更新。
所以需要收集“渲染Watcher”,在执行完“计算属性Watcher”后,再执行“渲染Watcher”。页面渲染对计算属性取值,执行 watcher.evaluate 才会重新计算求值,页面计算属性更新。
Vue的数据为什么频繁变化但只会更新一次
- 检测到数据变化
- 开启一个队列
- 在同一事件循环中缓冲所有数据改变
- 如果同一个
watcher (watcherId相同)被多次触发,只会被推入到队列中一次
不优化,每一个数据变化都会执行: setter->Dep->Watcher->update->run
优化后:执行顺序update -> queueWatcher -> 维护观察者队列(重复id的Watcher处理) -> waiting标志位处理 -> 处理$nextTick(在为微任务或者宏任务中异步更新DOM)
Functional component
优化前的组件代码如下:
<template>
<div class="cell">
<div v-if="value" class="on"></div>
<section v-else class="off"></section>
</div>
</template>
<script>
export default {
props: ['value'],
}
</script>
优化后的组件代码如下:
<template functional>
<div class="cell">
<div v-if="props.value" class="on"></div>
<section v-else class="off"></section>
</div>
</template>
优化前:
优化后:
函数式组件和普通的对象类型的组件不同,它不会被看作成一个真正的组件,我们知道在 patch 过程中,如果遇到一个节点是组件 vnode,会递归执行子组件的初始化过程;而函数式组件的 render 生成的是普通的 vnode,不会有递归子组件的过程,因此渲染开销会低很多。
因此,函数式组件也不会有状态,不会有响应式数据,生命周期钩子函数这些东西。你可以把它当成把普通组件模板中的一部分 DOM 剥离出来,通过函数的方式渲染出来,是一种在 DOM 层面的复用。
Vue3
为什么 Vue 3.0 中使用 Proxy
- Vue 中使用 Object.defineProperty 进行双向数据绑定时,告知使用者是可以监听数组的,但是只是监听了数组的 push()、pop()、shift()、unshift()、splice()、sort()、reverse() 这八种方法,其他数组的属性检测不到。
- Object.defineProperty 只能劫持对象的属性,因此对每个对象的属性进行遍历时,如果属性值也是对象需要深度遍历,那么就比较麻烦了,所以在比较 Proxy 能完整劫持对象的对比下,选择 Proxy。
- 为什么 Proxy 在 Vue 2.0 编写的时候出来了,尤大却没有用上去?因为当时 es6 环境不够成熟,兼容性不好,尤其是这个属性无法用 polyfill 来兼容。(polyfill 是一个 js 库,专门用来处理 js 的兼容性问题-js 修补器)
PatchFlag
https://juejin.cn/post/6903171037211557895?utm_source=gold_browser_extension
Vue 2.x 中的虚拟 DOM 是全量对比的模式,而到了 Vue 3.0 开始,新增了静态标记(PatchFlag)。
hoistStatic(静态提升)
https://juejin.cn/post/6903171037211557895?utm_source=gold_browser_extension#heading-1
cacheHandler(事件监听缓存)
https://juejin.cn/post/6903171037211557895?utm_source=gold_browser_extension#heading-2
SSR 服务端渲染
https://juejin.cn/post/6903171037211557895?utm_source=gold_browser_extension#heading-3
当你在开发中使用 SSR 开发时,Vue 3.0 会将静态标签直接转化为文本,相比 React 先将 jsx 转化为虚拟 DOM,再将虚拟 DOM 转化为 HTML,Vue 3.0 已经赢了。
Vuex
Vuex 全局维护着一个对象,使用到了单例设计模式。在这个全局对象中,所有属性都是响应式的,任意属性进行了改变,都会造成使用到该属性的组件进行更新。并且只能通过 commit 的方式改变状态,实现了单向数据流模式。
在使用 Vuex 之前,我们都需要调用 Vue.use(Vuex) 。在调用 use 的过程中,Vue 会调用到 Vuex 的 install 函数
install 函数作用很简单
- 确保 Vuex 只安装一次
- 混入
beforeCreate钩子函数,可以在组件中使用this.$store
VueRouter
- hash 模式 (可以通过
hashchange事件来监听到 URL 的变化,从而进行跳转页面。) - history 模式 (History 模式是 HTML5 新推出的功能)
对于路由注册来说,核心就是调用 Vue.use(VueRouter),使得 VueRouter 可以使用 Vue。然后通过 Vue 来调用 VueRouter 的 install 函数。在该函数中,核心就是给组件混入钩子函数和全局注册两个路由组件。
在实例化 VueRouter 的过程中,核心是创建一个路由匹配对象,并且根据 mode 来采取不同的路由方式。
createMatcher 函数的作用就是创建路由映射表,然后通过闭包的方式让 addRoutes 和 match 函数能够使用路由映射表的几个对象,最后返回一个 Matcher 对象。
路由初始化
当根组件调用 beforeCreate 钩子函数时,会执行以下代码
beforeCreate () {
// 只有根组件有 router 属性,所以根组件初始化时会初始化路由
if (isDef(this.$options.router)) {
this._routerRoot = this
this._router = this.$options.router
this._router.init(this)
Vue.util.defineReactive(this, '_route', this._router.history.current)
} else {
this._routerRoot = (this.$parent && this.$parent._routerRoot) || this
}
registerInstance(this, this)
}
在路由初始化时,核心就是进行路由的跳转,改变 URL 然后渲染对应的组件。接下来来看一下路由是如何进行跳转的。
作为插件
VueRouter 对象是在 src/index.js 中暴露出来的,这个对象有一个静态的 install 方法:
/* @flow */
// 导入 install 模块
import { install } from './install'
// ...
import { inBrowser, supportsHistory } from './util/dom'
// ...
export default class VueRouter {
// ...
}
// 赋值 install
VueRouter.install = install
// 自动使用插件
if (inBrowser && window.Vue) {
window.Vue.use(VueRouter)
}
install
https://github.com/DDFE/DDFE-blog/issues/9
install 在这里是一个单独的模块,继续来看同级下的 src/install.js 的主要逻辑:
// router-view router-link 组件
import View from './components/view'
import Link from './components/link'
// export 一个 Vue 引用 (注意这里)
export let _Vue
// 安装函数
export function install (Vue) {
if (install.installed) return
install.installed = true
// 赋值私有 Vue 引用
_Vue = Vue
// 注入 $router $route
Object.defineProperty(Vue.prototype, '$router', {
get () { return this.$root._router }
})
Object.defineProperty(Vue.prototype, '$route', {
get () { return this.$root._route }
})
// beforeCreate mixin
Vue.mixin({
beforeCreate () {
// 判断是否有 router
if (this.$options.router) {
// 赋值 _router
this._router = this.$options.router
// 初始化 init
this._router.init(this)
// 定义响应式的 _route 对象
Vue.util.defineReactive(this, '_route', this._router.history.current)
}
}
})
// 注册组件
Vue.component('router-view', View)
Vue.component('router-link', Link)
// ...
}
- 为啥要 export 一个 Vue 引用?
插件在打包的时候是肯定不希望把 vue 作为一个依赖包打进去的,但是呢又希望使用
Vue对象本身的一些方法,此时就可以采用上边类似的做法,在install的时候把这个变量赋值Vue,这样就可以在其他地方使用Vue的一些方法而不必引入 vue 依赖包(前提是保证install后才会使用)。
- 通过给
Vue.prototype定义$router、$route属性就可以把他们注入到所有组件中吗?
在 Vue.js 中所有的组件都是被扩展的 Vue 实例,也就意味着所有的组件都可以访问到这个实例原型上定义的属性。
React
Reconciler工作的阶段被称为render阶段。因为在该阶段会调用组件的render方法。Renderer工作的阶段被称为commit阶段。就像你完成一个需求的编码后执行git commit提交代码。commit阶段会把render阶段提交的信息渲染在页面上。render与commit阶段统称为work,即React在工作中。相对应的,如果任务正在Scheduler内调度,就不属于work。
父组件setState触发子组件更新
https://segmentfault.com/q/1010000011289209/a-1020000011289904
react的数据驱动,依赖于 state 和 props 的改变,改变state 必然会对组件 render 函数调用,如果父组件中的子组件过于复杂,一个父组件的 state 改变,就会牵一发动全身,必然影响性能,所以如果把很多依赖请求的组件抽离出来,可以直接减少渲染次数。
你可能会觉得这样不是很傻吗,我又没有传递属性给子组件,那父组件更新会触发所有后代组件的重渲染过程不是很低效且没有意义吗?但是React不能检测到你是否给子组件传了属性,所以它必须进行这个重渲染过程(术语叫做reconciliation)。但是这不会使得react有多低效,因为reconciliation过程是执行的JavaScript,而重渲染的性能开销主要是更新DOM导致的,最后diff算法会介入,决定是否要真正更新DOM,JavaScript的执行速度很快的,所以即使父组件render会触发所有后代组件的render过程(reconciliation过程),这个效率也不会有太大影响。
Reconciler(协调器)
每当有更新发生时,Reconciler会做如下工作:
- 调用函数组件、或class组件的
render方法,将返回的JSX转化为虚拟DOM - 将虚拟DOM和上次更新时的虚拟DOM对比
- 通过对比找出本次更新中变化的虚拟DOM
- 通知Renderer将变化的虚拟DOM渲染到页面上
- react 15 => Stack reconciler
- react 16 => Fiber reconciler
在React16中,Reconciler与Renderer不再是交替工作。当Scheduler将任务交给Reconciler后,Reconciler会为变化的虚拟DOM打上代表增/删/更新的标记,类似这样:
export const Placement = /* */ 0b0000000000010;
export const Update = /* */ 0b0000000000100;
export const PlacementAndUpdate = /* */ 0b0000000000110;
export const Deletion = /* */ 0b0000000001000;
整个Scheduler与Reconciler的工作都在内存中进行。只有当所有组件都完成Reconciler的工作,才会统一交给Renderer。
React 中各种组件复用的优劣势
(mixin、render props、hoc、hook)
react16废弃了哪几个生命周期api
从v16.3.0开始如下三个生命周期钩子被标记为UNSAFE。
- componentWillMount
- componentWillRecieveProps
- componentWillUpdate
目前React 16.8 +的生命周期分为三个阶段,分别是挂载阶段、更新阶段、卸载阶段。
挂载阶段:
-
constructor: 构造函数,最先被执行,我们通常在构造函数里初始化state对象或者给自定义方法绑定this
-
getDerivedStateFromProps: static getDerivedStateFromProps(nextProps, prevState),这是个静态方法,当我们接收到新的属性想去修改我们state,可以使用getDerivedStateFromProps
-
render: render函数是纯函数,只返回需要渲染的东西,不应该包含其它的业务逻辑,可以返回原生的DOM、React组件、Fragment、Portals、字符串和数字、Boolean和null等内容
-
componentDidMount: 组件装载之后调用,此时我们可以获取到DOM节点并操作,比如对canvas,svg的操作,服务器请求,订阅都可以写在这个里面,但是记得在componentWillUnmount中取消订阅
更新阶段:
- getDerivedStateFromProps: 此方法在更新个挂载阶段都可能调用;
- shouldComponentUpdate: shouldComponentUpdate(nextProps,nextState),有两个参数nextProps和nextState,表示新的属性和变化之后的state,返回一个布尔值,true表示会触发重新渲染,false表示不会触发重新渲染,默认返回true,我们通常利用此生命周期来优化React程序性能;
- render: 更新阶段也会触发此生命周
- getSnapshotBeforeUpdate(prevProps, prevState),这个方法在render之后,componentDidUpdate之前调用;
- componentDidUpdate:componentDidUpdate
(prevProps, prevState, snapshot),该方法在getSnapshotBeforeUpdate方法之后被调用,有三个参数prevProps,prevState,snapshot,表示之前的props,之前的state,和snapshot。第三个参数是getSnapshotBeforeUpdate返回的,如果触发某些回调函数时需要用到 DOM 元素的状态,则将对比或计算的过程迁移至 getSnapshotBeforeUpdate,然后在 componentDidUpdate 中统一触发回调或更新状态。
卸载阶段:
- componentWillUnmount: 当我们的组件被卸载或者销毁了就会调用,我们可以在这个函数里去清除一些定时器,取消网络请求,清理无效的DOM元素等垃圾清理工作
setState 是同步还是异步
https://blog.shenfq.com/2020/react-%E6%9E%B6%E6%9E%84%E7%9A%84%E6%BC%94%E5%8F%98-%E4%BB%8E%E5%90%8C%E6%AD%A5%E5%88%B0%E5%BC%82%E6%AD%A5/
https://zh-hans.reactjs.org/docs/faq-state.html#when-is-setstate-asynchronous
https://mp.weixin.qq.com/s/CpEtFuez-MqX1FFAfIHFAw
网上有很多文章称 setState 是『异步操作』,所以导致 setState 之后并不能获取到最新值,其实这个观点是错误的。setState 是一次同步操作,只是每次操作之后并没有立即执行,而是将 setState 进行了缓存,mount 流程结束或事件操作结束,才会拿出所有的 state 进行一次计算。
如果 setState 脱离了 React 的生命周期 或者 React 提供的事件流,setState 之后就能立即拿到结果。(例如:在setTimeout中)
class App extends React.Component {
state = { val: 0 }
componentDidMount() {
setTimeout(() => {
// 第一次调用
this.setState({ val: this.state.val + 1 });
console.log('first setState', this.state); // 1
// 第二次调用
this.setState({ val: this.state.val + 1 });
console.log('second setState', this.state); // 2
});
}
render() {
return <div> val: { this.state.val } </div>
}
}
// setState 之后就能立即看到 state.val 的值发生了变化
总结:
- legacy模式命中batchedUpdates时异步
- legacy模式未命中batchedUpdates时同步 (例如:在setTimeout中)
- Concurrent模式都是异步的
setState 合并原因
setState 的时候,batchingStrategy.isBatchingUpdates 为 false 会开启一个事务,将组件放入脏组件队列,最后进行更新操作,而且这里都是同步操作。讲道理,setState 之后,我们可以立即拿到最新的 state。
然而,事实并非如此,在 React 的生命周期及其事件流中,batchingStrategy.isBatchingUpdates 的值早就被修改成了 true。
在组件 mount 和事件调用的时候,都会调用 batchedUpdates,这个时候已经开始了事务,所以只要不脱离 React,不管多少次 setState 都会把其组件放入脏组件队列等待更新。一旦脱离 React 的管理,比如在 setTimeout 中,setState 立马变成单打独斗。
var batchingStrategy = {
// 判断是否在更新流程中
isBatchingUpdates: false,
// 开始进行批量更新
batchedUpdates: function (callback, component) {
// 获取之前的更新状态
var alreadyBatchingUpdates = ReactDefaultBatchingStrategy.isBatchingUpdates;
// 将更新状态修改为 true (注意这里)
ReactDefaultBatchingStrategy.isBatchingUpdates = true;
if (alreadyBatchingUpdates) {
// 如果已经在更新状态中,等待之前的更新结束
return callback(callback, component);
} else {
// 进行更新
return transaction.perform(callback, null, component);
}
}
};
举个例子
https://github.com/facebook/react/issues/11527
For example, if we’re inside a browser click handler, and both Child and Parent call setState, we don’t want to re-render the Child twice, and instead prefer to mark them as dirty, and re-render them together before exiting the browser event.
例如,如果我们在浏览器的单击处理程序中,并且子程序和父程序都调用setState,我们不想重新呈现子程序两次,而宁愿将它们标记为dirty,并在退出浏览器事件之前一起重新呈现它们。
Guaranteeing Internal Consistency
Even if state is updated synchronously, props are not. (You can’t know props until you re-render the parent component, and if you do this synchronously, batching goes out of the window.)
Right now the objects provided by React (state, props, refs) are internally consistent with each other(相互一致). This means that if you only use those objects, they are guaranteed to refer to a fully reconciled tree (even if it’s an older version of that tree). Why does this matter?
setState实现
在 React 15 里,多次 setState 会被放到一个队列中,等待一次更新。
//setState 方法挂载到原型链上
ReactComponent.prototype.setState = function (partialState, callback) {
// 调用 setState 后,会调用内部的 updater.enqueueSetState
this.updater.enqueueSetState(this, partialState)
};
var ReactUpdateQueue = {
enqueueSetState(component, partialState) {
// 在组件的 _pendingStateQueue 上暂存新的 state
if (!component._pendingStateQueue) {
component._pendingStateQueue = []
}
// 将 setState 的值放入队列中
var queue = component._pendingStateQueue
queue.push(partialState)
enqueueUpdate(component)
}
}
同样在 Fiber 架构中,也会有一个队列用来存放 setState 的值。每个 Fiber 节点都有一个 updateQueue 属性,这个属性就是用来缓存 setState 值的,只是结构从 React 15 的数组变成了链表结构。
无论是首次 Render 的 Mount 阶段,还是 setState 的 Update 阶段,内部都会调用 enqueueUpdate 方法。
//--- Render 阶段 ---
function initializeUpdateQueue(fiber) {
var queue = {
baseState: fiber.memoizedState,
firstBaseUpdate: null,
lastBaseUpdate: null,
shared: {
pending: null
},
effects: null
}
fiber.updateQueue = queue
}
ReactDOMRoot.prototype.render = function render(children) {
var root = this._internalRoot
var update = createUpdate()
update.payload = { element: children }
const rootFiber = root.current
// 初始化 rootFiber 的 updateQueue
initializeUpdateQueue(rootFiber)
//update 对象放到 rootFiber 的 updateQueue 中
enqueueUpdate(rootFiber, update)
// 开始更新流程
scheduleUpdateOnFiber(rootFiber)
}
//--- Update 阶段 ---
Component.prototype.setState = function (partialState, callback) {
this.updater.enqueueSetState(this, partialState)
}
var classComponentUpdater = {
enqueueSetState: function (inst, payload) {
// 获取实例对应的 fiber
var fiber = get(inst)
var update = createUpdate()
update.payload = payload
//update 对象放到 rootFiber 的 updateQueue 中
enqueueUpdate(fiber, update)
scheduleUpdateOnFiber(fiber)
}
}
enqueueUpdate 方法的主要作用就是将 setState 的值挂载到 Fiber 节点上。
function enqueueUpdate(fiber, update) {
var updateQueue = fiber.updateQueue;
if (updateQueue === null) {
//updateQueue 为空则跳过
return;
}
var sharedQueue = updateQueue.shared;
var pending = sharedQueue.pending;
if (pending === null) {
update.next = update;
} else {
// 链表连接
update.next = pending.next;
pending.next = update;
}
sharedQueue.pending = update;
}
多次 setState 会在 sharedQueue.pending 上形成一个单向循环链表,具体例子更形象的展示下这个链表结构。
我们来看一个例子:
class App extends React.Component {
state = { val: 0 }
click () {
for (let i = 0; i < 3; i++) {
this.setState({ val: this.state.val + 1 })
}
}
render() {
return <div onClick={() => {
this.click()
}}>val: { this.state.val }</div>
}
}
点击 div 之后,会连续进行三次 setState,每次 setState 都会更新 updateQueue。

useEffect 和 componentDidMount 的差异
https://cooperhu.com/2020/09/03/useEffect-componentDidMount/
Hooks 是一种范式转换,从“生命周期和时间”的思维模式转变为“状态和与DOM的同步”的思维模式。如果尝试采用旧的思维模式并找到与其对应的钩子,可能会阻碍我们正确的理解和使用 Hooks
执行时机不同
componentDidMount在组件挂载之后运行。如果立即(同步)设置 state,那么React就会触发一次额外的render,并将第二个render的响应用作初始UI,这样用户就不会看到闪烁。
假设需要使用componentDidMount读取一个DOM元素的宽度,并希望更新state来反映宽度。事件的执行顺序应该是下面这样的:
- 首次执行render
- 此次 render 的返回值 将用于更新到真正的 Dom 中
- componentDidMount 执行而且执行setState
- state 变更导致 再次执行 render,而且返回了新的 返回值
- 浏览器只显示了第二次 render 的返回值,这样可以避免闪屏
可以理解为上面的过程都是同步执行的,会阻塞到浏览器将真实DOM最终绘制到浏览器上,当我们需要它的时候,这样的工作模式是合理的。但大多数情况下,我们可以在UI Paint 完毕之后,再执行一些异步拉取数据之后setState之类的副作用。
useEffect 也是在挂载后运行,但是它更往后,它不会阻塞真实Dom的渲染,因为 useEffect 在 Paint (绘制)之后延迟异步运行。这意味着如果需要从DOM读取数据,然后同步设置state以生成新的UI,有可能会有闪烁的问题发生。React 也提供了 同步执行模式的 useLayoutEffect,它更加接近 componentDidMount( )的表现。
如果想通过同步设置状态来避免闪烁,那么可以使用useLayoutEffect。但是大部分时间都需要使用useEffect比较好。
Props 和 State 的捕获(Capturing)
在React应用程序中,会存在许多的异步操作。当多个异步操作执行时,props 和 state 的值可能会有点混乱。
假设我们有很多异步代操作流程,在执行时需要知道 count 的状态:
class App extends React.Component {
state = {
count: 0
};
componentDidMount() {
longResolve().then(() => {
alert(this.state.count);
});
}
render() {
return (
<div>
<button
onClick={() => {
this.setState(state => ({ count: state.count + 1 }));
}}
>
Count: {this.state.count}
</button>
</div>
);
}
}
页面加载完成后,在 longResolve 执行完成之前, 假设大概有几秒钟的时间单击按钮几次。如过我在此期间点了5次按钮,那么最后alert最终显示的也是最新的值,也是5次。
同样的场景,我们一开始用 hooks 重构的代码如下:
function App() {
const [count, setCount] = useState(0);
useEffect(() => {
longResolve().then(() => {
alert(count);
});
}, []);
return (
<div>
<button
onClick={() => {
setCount(count + 1);
}}
>
Count: {count}
</button>
</div>
);
}
但是运行后会发现,它的表现和 class 版本有所不同,无论你在 longResolve 执行完毕前点击多少次,最后 alert 的 count 都是 0。
造成这种差异的原因是 useEffect 在创建时就已经捕获了count的值。当我们把回调函数赋给useEffect时,它会存在于内存中,在内存中它只知道 count 在创建时是0(由于闭包)。不管经过了多少时间,以及 count 这个时间内改变了多少次,闭包的本质是只跟创建闭包时这个值的状态有关,我们称之为“捕获”。而在 class组件中,componentDidMount( ) 没有闭包,每次读取的都是当前 count 的值。
情况可以等同于下面的函数来理解,在内存中,useEffect 的回调函数中的 count 再创建时赋予了初始值0,此时 count 的值不会再因外界的变化而受到影响。
() => {
const count = 0
longResolve().then(() => {
alert(count);
});
}
如果我们想让 函数组件 和 类组件 表现一致 该如何去做?
依赖数组(depends array)
Hooks 实现就需要修改为,这样的话表现就跟我们的预期一致了
useEffect(() => {
const id = setInterval(() => {
setCount(count + 1)
}, 1000)
return () => clearInterval(id)
}, [count])
这样的写法可以用下面的函数来理解,一旦依赖项发生变化,每次都销毁上一次的,新建一个新的。
// Hey memory, we need you to store a function...
() => {
const count = 0
const id = setInterval(() => {
setCount(count + 1)
}, 1000)
return () => clearInterval(id)}
// Later on when count changed...
// Hey memory, call the cleanup of that first function, then
// we need you to store another function...
() => {
const count = 1
const id = setInterval(() => {
setCount(count + 1)
}, 1000)
return () => clearInterval(id)
}
总结:
使用 Hooks 模式进行编程时,我们需要忘记 生命周期和时间线 的概念,使用 以状态为中心,以及对应状态发生变化时,哪些副作用需要重新执行 的思想来进行编码。
Update
首先,我们将可以触发更新的方法所隶属的组件分类:
- ReactDOM.render —— HostRoot
- this.setState —— ClassComponent
- this.forceUpdate —— ClassComponent
- useState —— FunctionComponent
- useReducer —— FunctionComponent
由于不同类型组件工作方式不同,所以存在两种不同结构的Update,其中ClassComponent与HostRoot共用一套Update结构,FunctionComponent单独使用一种Update结构。
ClassComponent与HostRoot(即rootFiber.tag对应类型)对应的结构如下:
const update: Update<*> = {
eventTime,
lane,
suspenseConfig,
tag: UpdateState,
payload: null,
callback: null,
next: null,
};
Fiber 架构
什么是fiber
https://blog.shenfq.com/2020/react-%E6%9E%B6%E6%9E%84%E7%9A%84%E6%BC%94%E5%8F%98-%E4%BB%8E%E9%80%92%E5%BD%92%E5%88%B0%E5%BE%AA%E7%8E%AF/
fiber是链表结构
Fiber并不是计算机术语中的新名词,他的中文翻译叫做纤程,与进程(Process)、线程(Thread)、协程(Coroutine)同为程序执行过程。
在很多文章中将纤程理解为协程的一种实现。在JS中,协程的实现便是Generator。
所以,我们可以将纤程(Fiber)、协程(Generator)理解为代数效应思想在JS中的体现。
React内部实现的一套状态更新机制。支持任务不同优先级,可中断与恢复,并且恢复后可以复用之前的中间状态。其中每个任务更新单元为React Element对应的Fiber节点。
任务更新单元就是Fiber节点
任务更新单元就是Fiber节点
任务更新单元就是Fiber节点
- 作为静态的数据结构来说,每个
Fiber节点对应一个React element,保存了该组件的类型(函数组件/类组件/原生组件…)、对应的DOM节点等信息。 - 作为动态的工作单元来说,每个
Fiber节点保存了本次更新中该组件改变的状态、要执行的工作(需要被删除/被插入页面中/被更新…)。
为什么要实现fiber
架构的演变-从递归到循环
react15递归更新组件有明显的缺点,不能暂停更新,一旦开始必须从头到尾,这与 React 16 拆分时间片,给浏览器喘口气的理念明显不符,所以 React 必须要切换架构,将虚拟 DOM 从树形结构修改为链表结构。
链表结构最大的优势就是可以通过循环的方式来遍历,只要记住当前遍历的位置,即使中断后也能快速还原,重新开始遍历。
循环更新的实现
那么,在 setState 的时候,React 是如何进行一次 Fiber 的遍历的呢?
let workInProgress = FiberRoot
// 遍历 Fiber 节点,如果时间片时间用完就停止遍历
function workLoopConcurrent() {
while (
workInProgress !== null &&
!shouldYield() // 用于判断当前时间片是否到期
) {
performUnitOfWork(workInProgress)
}
}
function performUnitOfWork() {
const next = beginWork(workInProgress) // 返回当前 Fiber 的 child
if (next) { //child 存在
// 重置 workInProgress 为 child
workInProgress = next
} else { //child 不存在
// 向上回溯节点
let completedWork = workInProgress
while (completedWork !== null) {
// 收集副作用,主要是用于标记节点是否需要操作 DOM
completeWork(completedWork)
// 获取 Fiber.sibling
let siblingFiber = workInProgress.sibling
if (siblingFiber) {
//sibling 存在,则跳出 complete 流程,继续 beginWork
workInProgress = siblingFiber
return;
}
completedWork = completedWork.return
workInProgress = completedWork
}
}
}
function beginWork(workInProgress) {
// 调用 render 方法,创建子 Fiber,进行 diff
// 操作完毕后,返回当前 Fiber 的 child
return workInProgress.child
}
function completeWork(workInProgress) {
// 收集节点副作用
}
Fiber 的遍历本质上就是一个循环,全局有一个 workInProgress 变量,用来存储当前正在 diff 的节点,先通过 beginWork 方法对当前节点然后进行 diff 操作(diff 之前会调用 render,重新计算 state、prop),并返回当前节点的第一个子节点 ( fiber.child) 作为新的工作节点,直到不存在子节点。然后,对当前节点调用 completedWork 方法,存储 beginWork 过程中产生的副作用,如果当前节点存在兄弟节点 ( fiber.sibling),则将工作节点修改为兄弟节点,重新进入 beginWork 流程。直到 completedWork 重新返回到根节点,执行 commitRoot 将所有的副作用反应到真实 DOM 中。

在一次遍历过程中,每个节点都会经历 beginWork、completeWork ,直到返回到根节点,最后通过 commitRoot 将所有的更新提交
Fiber 架构下每个节点都会经历 递(beginWork) 和 归(completeWork) 两个过程:
- beginWork:生成新的 state,调用 render 创建子节点,连接当前节点与子节点;
- completeWork:依据 EffectTag 收集 Effect,构造 Effect List;
shouldYield
shouldYield 方法决定了当前时间片是否已经用完,这也是决定 React 是同步渲染还是异步渲染的关键。如果去除任务优先级的概念,shouldYield 方法可以说很简单,就是判断了当前的时间,是否已经超过了预设的 deadline。
function getCurrentTime() {
return performance.now()
}
function shouldYield() {
// 获取当前时间
var currentTime = getCurrentTime()
return currentTime >= deadline
}
deadline 又是如何得的呢?
deadline = currentTime + yieldInterval
更新开始的时候会通过 requestHostCallback(即:port2.send)发送异步消息,在 performWorkUntilDeadline (即:port1.onmessage)中接收消息。performWorkUntilDeadline 每次接收到消息时,表示已经进入了下一个任务队列,这个时候就会更新 deadline。

双缓存Fiber树
在React中最多会同时存在两棵Fiber树。当前屏幕上显示内容对应的Fiber树称为current Fiber树,正在内存中构建的Fiber树称为workInProgress Fiber树。
current Fiber树中的Fiber节点被称为current fiber,workInProgress Fiber树中的Fiber节点被称为workInProgress fiber,他们通过alternate属性连接。
currentFiber.alternate === workInProgressFiber;
workInProgressFiber.alternate === currentFiber;
React应用的根节点通过current指针在不同Fiber树的rootFiber间切换来实现Fiber树的切换。
当workInProgress Fiber树构建完成交给Renderer渲染在页面上后,应用根节点的current指针指向workInProgress Fiber树,此时workInProgress Fiber树就变为current Fiber树。
每次状态更新都会产生新的workInProgress Fiber树,通过current与workInProgress的替换,完成DOM更新。
什么是“双缓存”
https://react.iamkasong.com/process/doubleBuffer.html#%E4%BB%80%E4%B9%88%E6%98%AF-%E5%8F%8C%E7%BC%93%E5%AD%98
当我们用canvas绘制动画,每一帧绘制前都会调用ctx.clearRect清除上一帧的画面。
如果当前帧画面计算量比较大,导致清除上一帧画面到绘制当前帧画面之间有较长间隙,就会出现白屏。
为了解决这个问题,我们可以在内存中绘制当前帧动画,绘制完毕后直接用当前帧替换上一帧画面,由于省去了两帧替换间的计算时间,不会出现从白屏到出现画面的闪烁情况。
这种在内存中构建并直接替换的技术叫做双缓存 (opens new window)。
React使用“双缓存”来完成Fiber树的构建与替换——对应着DOM树的创建与更新。
Diff
https://zh-hans.reactjs.org/docs/reconciliation.html#the-diffing-algorithm
为了防止概念混淆,这里再强调下
一个DOM节点在某一时刻最多会有4个节点和他相关。
current Fiber。如果该DOM节点已在页面中,current Fiber代表该DOM节点对应的Fiber节点。workInProgress Fiber。如果该DOM节点将在本次更新中渲染到页面中,workInProgress Fiber代表该DOM节点对应的Fiber节点。DOM节点本身。JSX对象。即ClassComponent的render方法的返回结果,或FunctionComponent的调用结果。JSX对象中包含描述DOM节点的信息。
Diff算法的本质是对比1和4,生成2。
为了降低算法复杂度,React的diff会预设三个限制:
- 只对同级元素进行
Diff。如果一个DOM节点在前后两次更新中跨越了层级,那么React不会尝试复用他。 - 两个不同类型的元素会产生出不同的树。如果元素由
div变为p,React会销毁div及其子孙节点,并新建p及其子孙节点。 - 开发者可以通过
key prop来暗示哪些子元素在不同的渲染下能保持稳定
我们从Diff的入口函数reconcileChildFibers出发,该函数会根据newChild(即JSX对象)类型调用不同的处理函数。
// 根据newChild类型选择不同diff函数处理
function reconcileChildFibers(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
newChild: any,
): Fiber | null {
const isObject = typeof newChild === 'object' && newChild !== null;
if (isObject) {
// object类型,可能是 REACT_ELEMENT_TYPE 或 REACT_PORTAL_TYPE
switch (newChild.$$typeof) {
case REACT_ELEMENT_TYPE:
// 调用 reconcileSingleElement 处理
// // ...省略其他case
}
}
if (typeof newChild === 'string' || typeof newChild === 'number') {
// 调用 reconcileSingleTextNode 处理
// ...省略
}
if (isArray(newChild)) {
// 调用 reconcileChildrenArray 处理
// ...省略
}
// 一些其他情况调用处理函数
// ...省略
// 以上都没有命中,删除节点
return deleteRemainingChildren(returnFiber, currentFirstChild);
}
我们可以从同级的节点数量将Diff分为两类:
- 当
newChild类型为object、number、string,代表同级只有一个节点 - 当
newChild类型为Array,同级有多个节点
单节点Diff
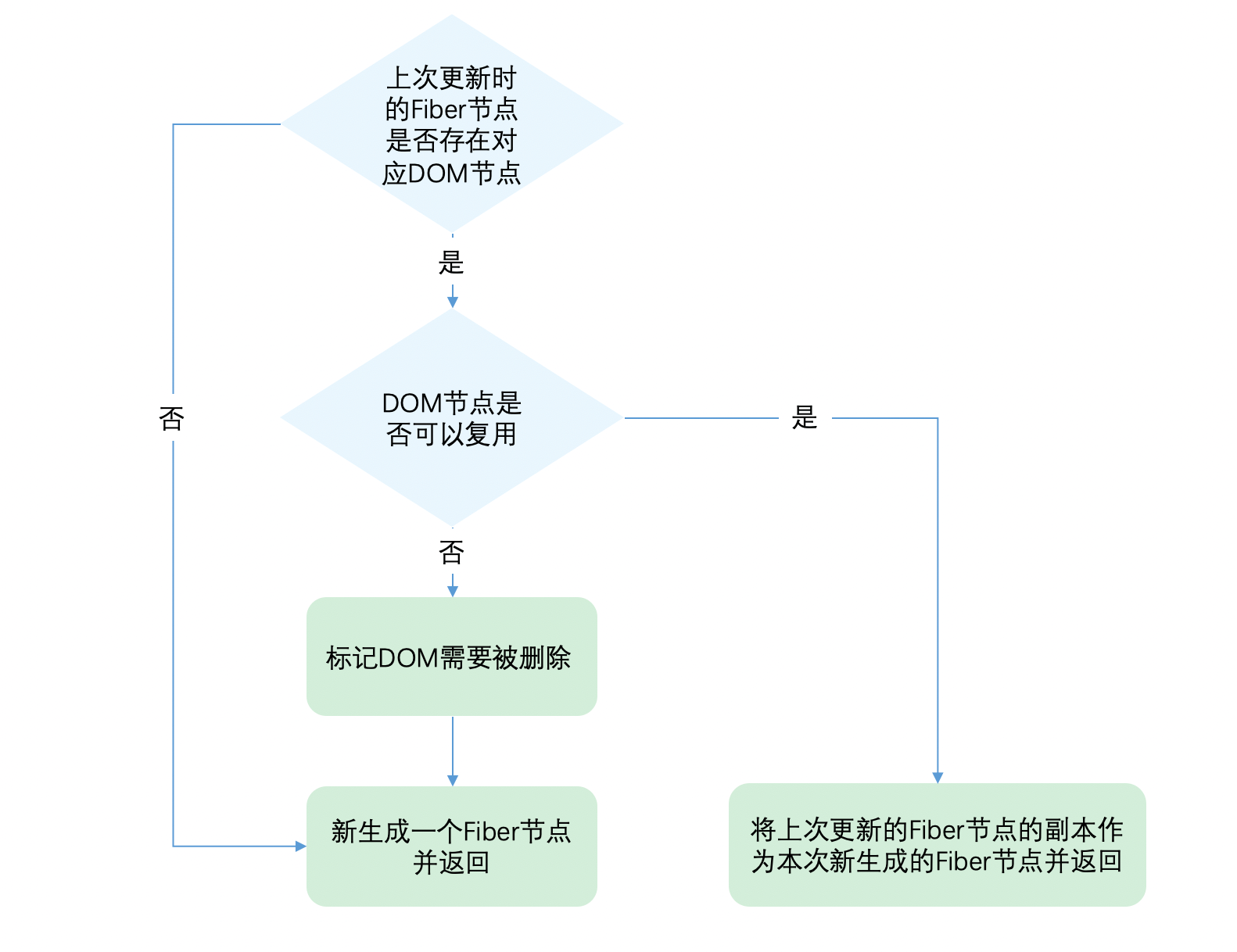
让我们看看第二步判断DOM节点是否可以复用是如何实现的。
function reconcileSingleElement(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
element: ReactElement
): Fiber {
const key = element.key;
let child = currentFirstChild;
// 首先判断是否存在对应DOM节点
while (child !== null) {
// 上一次更新存在DOM节点,接下来判断是否可复用
// 首先比较key是否相同
if (child.key === key) {
// key相同,接下来比较type是否相同
switch (child.tag) {
// ...省略case
default: {
if (child.elementType === element.type) {
// type相同则表示可以复用
// 返回复用的fiber
return existing;
}
// type不同则跳出循环
break;
}
}
// 代码执行到这里代表:key相同但是type不同
// 将该fiber及其兄弟fiber标记为删除
deleteRemainingChildren(returnFiber, child);
break;
} else {
// key不同,将该fiber标记为删除
deleteChild(returnFiber, child);
}
child = child.sibling;
}
// 创建新Fiber,并返回 ...省略
}
从代码可以看出,React通过先判断key是否相同,如果key相同则判断type是否相同,只有都相同时一个DOM节点才能复用。
这里有个细节需要关注下:
- 当
child !== null且key相同且type不同时执行deleteRemainingChildren将child及其兄弟fiber都标记删除。 - 当
child !== null且key不同时仅将child标记删除。
多节点Diff
reconcileChildFibers的newChild参数类型为Array,在reconcileChildFibers函数内部对应如下情况:
if (isArray(newChild)) {
// 调用 reconcileChildrenArray 处理
// ...省略
}
但是React团队发现,在日常开发中,相较于新增和删除,更新组件发生的频率更高。所以Diff会优先判断当前节点是否属于更新。
注意
在我们做数组相关的算法题时,经常使用双指针从数组头和尾同时遍历以提高效率,但是这里却不行。
虽然本次更新的
JSX对象newChildren为数组形式,但是和newChildren中每个组件进行比较的是current fiber,同级的Fiber节点是由sibling指针链接形成的单链表,即不支持双指针遍历。即
newChildren[0]与fiber比较,newChildren[1]与fiber.sibling比较。所以无法使用双指针优化。
react的diff,不像vue,无法使用双指针优化。
react的diff,不像vue,无法使用双指针优化。
react的diff,不像vue,无法使用双指针优化。
基于以上原因,Diff算法的整体逻辑会经历两轮遍历:
- 第一轮遍历:处理
更新的节点。 - 第二轮遍历:处理剩下的不属于
更新的节点。
第一轮遍历的结果:
newChildren与oldFiber同时遍历完newChildren没遍历完,oldFiber遍历完newChildren遍历完,oldFiber没遍历完newChildren与oldFiber都没遍历完 (这是最难的部分)
标记节点是否移动
既然我们的目标是寻找移动的节点,那么我们需要明确:节点是否移动是以什么为参照物?
我们的参照物是:最后一个可复用的节点在oldFiber中的位置索引(用变量lastPlacedIndex表示)。
时间复杂度
Renderer
Renderer 有两个阶段: render阶段 和 commit阶段
render阶段开始于performSyncWorkOnRoot或performConcurrentWorkOnRoot方法的调用。这取决于本次更新是同步更新还是异步更新commit阶段开始于commitRoot方法的调用。其中rootFiber会作为传参。
render阶段 :
- beginWork
- completeWork
Renderer工作的阶段被称为commit阶段,commit阶段可以分为三个子阶段:
- before mutation阶段(执行
DOM操作前) - mutation阶段(执行
DOM操作) - layout阶段(执行
DOM操作后)
state的变化在render阶段产生与上次更新不同的JSX对象,通过Diff算法产生effectTag,在commit阶段渲染在页面上。渲染完成后workInProgress Fiber树变为current Fiber树,整个更新流程结束。
beginWork
beginWork流程图
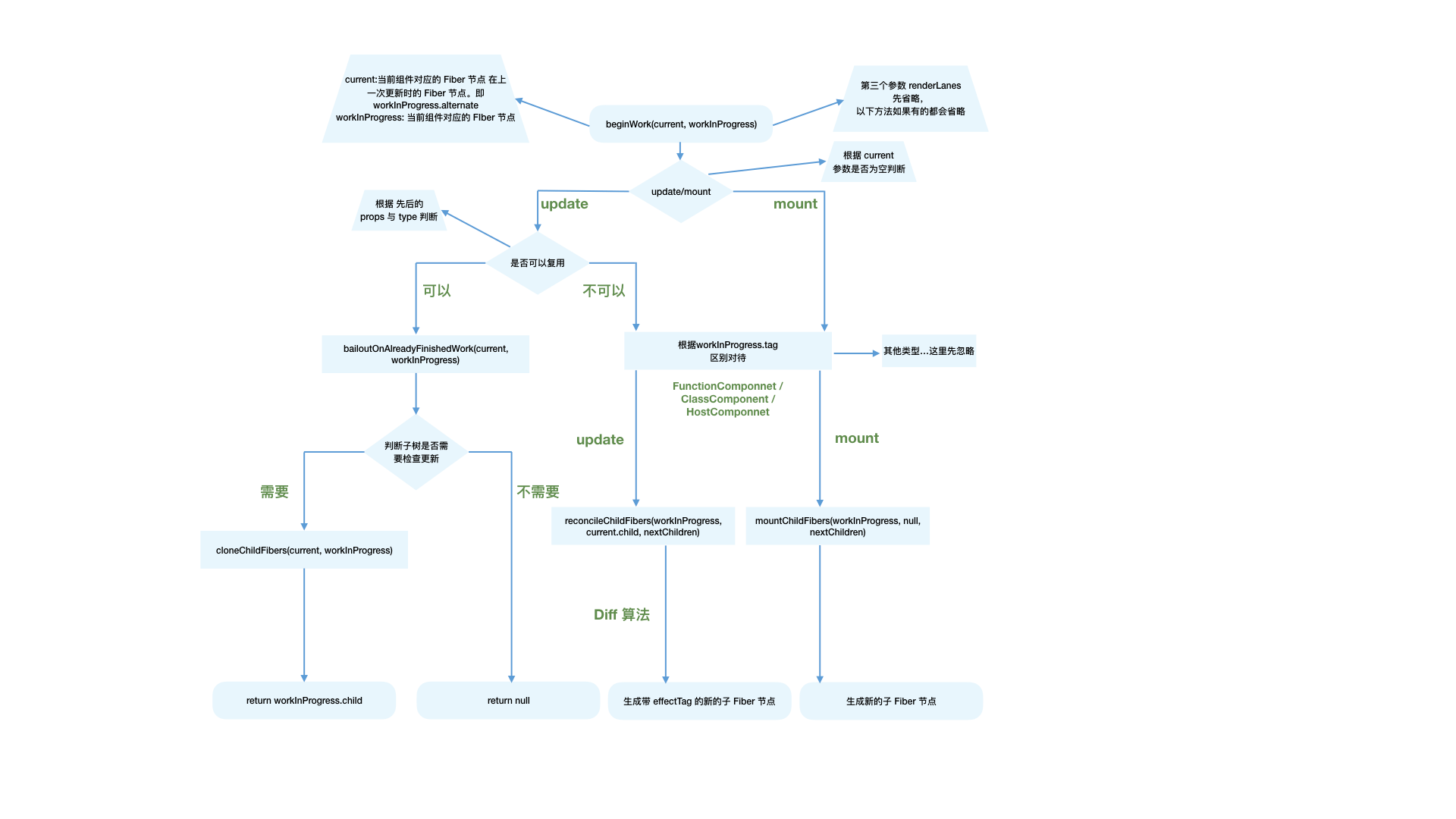
在React中,有如下方法可以触发状态更新(排除SSR相关):
- ReactDOM.render
- this.setState
- this.forceUpdate
- useState
- useReducer
这些方法调用的场景各不相同,他们是如何接入同一套状态更新机制呢?
答案是:每次状态更新都会创建一个保存更新状态相关内容的对象,我们叫他Update。在render阶段的beginWork中会根据Update计算新的state。
completeWork
类似beginWork,completeWork也是针对不同fiber.tag调用不同的处理逻辑。
和beginWork一样,我们根据current === null ?判断是mount还是update。
completeWork流程图
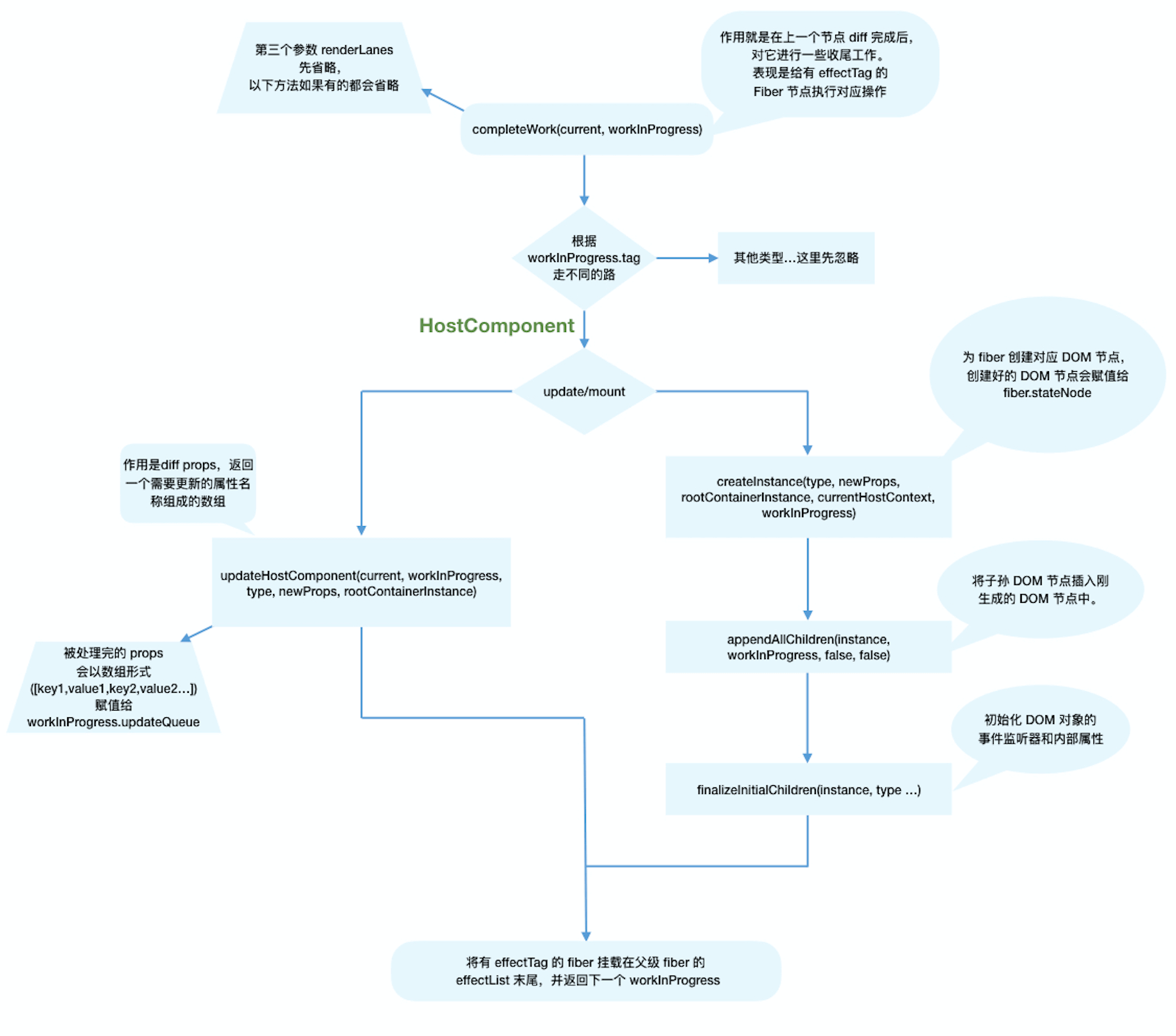
update
当update时,Fiber节点已经存在对应DOM节点,所以不需要生成DOM节点。需要做的主要是处理props
在updateHostComponent内部,被处理完的props会被赋值给workInProgress.updateQueue,并最终会在commit阶段被渲染在页面上。
workInProgress.updateQueue = (updatePayload: any);
其中updatePayload为数组形式,他的奇数索引的值为变化的prop key,偶数索引的值为变化的prop value。
mount
同样,我们省略了不相关的逻辑。可以看到,mount时的主要逻辑包括三个:
- 为
Fiber节点生成对应的DOM节点 - 将子孙
DOM节点插入刚生成的DOM节点中 - 与
update逻辑中的updateHostComponent类似的处理props的过程
mutation阶段
mutation阶段会遍历effectList,依次执行commitMutationEffects。该方法的主要工作为“根据effectTag调用不同的处理函数处理Fiber。
FunctionComponent mutation
当fiber.tag为FunctionComponent,会调用commitHookEffectListUnmount。该方法会遍历effectList,执行所有useLayoutEffect hook的销毁函数。
所谓“销毁函数”,见如下例子:
useLayoutEffect(() => {
// ...一些副作用逻辑
return () => {
// ...这就是销毁函数
}
})
effectList
还有一个问题:作为DOM操作的依据,commit阶段需要找到所有有effectTag的Fiber节点并依次执行effectTag对应操作。难道需要在commit阶段再遍历一次Fiber树寻找effectTag !== null的Fiber节点么?
这显然是很低效的。
为了解决这个问题,在completeWork的上层函数completeUnitOfWork中,每个执行完completeWork且存在effectTag的Fiber节点会被保存在一条被称为effectList的单向链表中。
effectList中第一个Fiber节点保存在fiber.firstEffect,最后一个元素保存在fiber.lastEffect。
类似appendAllChildren,在“归”阶段,所有有effectTag的Fiber节点都会被追加在effectList中,最终形成一条以rootFiber.firstEffect为起点的单向链表。
nextEffect nextEffect
rootFiber.firstEffect -----------> fiber -----------> fiber
这样,在commit阶段只需要遍历effectList就能执行所有effect了。
effectList相较于Fiber树,就像圣诞树上挂的那一串彩灯。
mountChildFibers打effectTag?
mountChildFibers的时候会不会打effectTag?
假设mountChildFibers也会赋值effectTag,那么可以预见mount时整棵Fiber树所有节点都会有Placement effectTag。那么commit阶段在执行DOM操作时每个节点都会执行一次插入操作,这样大量的DOM操作是极低效的。
为了解决这个问题,在mount时只有rootFiber会赋值Placement effectTag,在commit阶段只会执行一次插入操作。
Concurrent 模式
Concurrent 模式是 React 的新功能,可帮助应用保持响应,并根据用户的设备性能和网速进行适当的调整。
Concurrent 模式说白就是让组件更新异步化,切分时间片,渲染之前的调度、diff、更新都只在指定时间片进行,如果超时就暂停放到下个时间片进行,中途给浏览器一个喘息的时间。
浏览器的运作流程: 渲染 -> tasks -> 渲染 -> tasks -> 渲染 -> ....
这些 tasks 中有些我们可控,有些不可控,比如 setTimeout 什么时候执行不好说,它总是不准时;资源加载时间不可控。但一些 JS 我们可以控制,让它们分派执行,tasks 的时长不宜过长,这样浏览器就有时间优化 JS 代码与修正 reflow !
总结一句, 就是让浏览器休息好,浏览器就能跑得更快 。
Component.setState()
=> enquueState()
=> scheduleUpdate()
=> scheduleCallback()
=> requestHostCallback(flushWork)
=> postMessage()
真正的异步化逻辑就在 requestHostCallback、postMessage 里面,这是 React 内部自己实现的一个调度器
https://github.com/facebook/react/blob/v16.13.1/packages/scheduler/index.js
function unstable_scheduleCallback(priorityLevel, calback) {
var currentTime = getCurrentTime();
var startTime = currentTime + delay;
var newTask = {
id: taskIdCounter++,
startTime: startTime, // 任务开始时间
expirationTime: expirationTime, // 任务终止时间
priorityLevel: priorityLevel, // 调度优先级
callback: callback, // 回调函数
};
if (startTime > currentTime) {
// 超时处理,将任务放到 taskQueue,下一个时间片执行
// 源码中其实是 timerQueue,后续会有个操作将 timerQueue 的 task 转移到 taskQueue
push(taskQueue, newTask)
} else {
requestHostCallback(flushWork);
}
return newTask;
}
requestHostCallback 的实现依赖于 MessageChannel,但是 MessageChannel 在这里并不是做消息通信用的,而是利用它的异步能力,给浏览器一个喘息的机会。
var isMessageLoopRunning = false; // 更新状态
var scheduledHostCallback = null; // 全局的回调
var channel = new MessageChannel();
var port = channel.port2;
channel.port1.onmessage = function () {
if (scheduledHostCallback !== null) {
var currentTime = getCurrentTime();
// 重置超时时间
deadline = currentTime + yieldInterval;
var hasTimeRemaining = true;
// 执行 callback
var hasMoreWork = scheduledHostCallback(hasTimeRemaining, currentTime);
if (!hasMoreWork) {
// 已经没有任务了,修改状态
isMessageLoopRunning = false;
scheduledHostCallback = null;
} else {
// 还有任务,放到下个任务队列执行,给浏览器喘息的机会
port.postMessage(null);
}
} else {
isMessageLoopRunning = false;
}
};
requestHostCallback = function (callback) {
//callback 挂载到 scheduledHostCallback
scheduledHostCallback = callback;
if (!isMessageLoopRunning) {
isMessageLoopRunning = true;
// 推送消息,下个队列队列调用 callback
port.postMessage(null);
}
};
再看看之前传入的 callback(flushWork),调用 workLoop,取出 taskQueue 中的任务执行。
// 精简了相当多的代码
function flushWork(hasTimeRemaining, initialTime) {
return workLoop(hasTimeRemaining, initialTime);
}
function workLoop(hasTimeRemaining, initialTime) {
var currentTime = initialTime;
//scheduleCallback 进行了 taskQueue 的 push 操作
// 这里是获取之前时间片未执行的操作
currentTask = peek(taskQueue);
while (currentTask !== null) {
if (currentTask.expirationTime > currentTime) {
// 超时需要中断任务
break;
}
currentTask.callback(); // 执行任务回调
currentTime = getCurrentTime(); // 重置当前时间
currentTask = peek(taskQueue); // 获取新的任务
}
// 如果当前任务不为空,表明是超时中断,返回 true
if (currentTask !== null) {
return true;
} else {
return false;
}
}
可以看出,React 通过 expirationTime 来判断是否超时,如果超时就把任务放到后面来执行。所以,异步模型中 setTimeout 里面进行 setState,只要当前时间片没有结束(currentTime 小于 expirationTime),依旧可以将多个 setState 合并成一个。
将异步逻辑、循环更新、时间分片串联起来。先回顾一下之前的文章讲过,Concurrent 模式下,setState 后的调用顺序:
Component.setState()
=> enqueueSetState()
=> scheduleUpdate()
=> scheduleCallback(performConcurrentWorkOnRoot)
=> requestHostCallback()
=> postMessage()
=> performWorkUntilDeadline()
scheduleCallback 方法会将传入的回调(performConcurrentWorkOnRoot)组装成一个任务放入 taskQueue 中,然后调用 requestHostCallback 发送一个消息,进入异步任务。performWorkUntilDeadline 接收到异步消息,从 taskQueue 取出任务开始执行,这里的任务就是之前传入的 performConcurrentWorkOnRoot 方法,这个方法最后会调用 workLoopConcurrent(workLoopConcurrent 前面已经介绍过了,这个不再重复)。如果 workLoopConcurrent 是由于超时中断的,hasMoreWork 返回为 true,通过 postMessage 发送消息,将操作延迟到下一个任务队列。
为什么react 15生命周期钩子标记为UNSAFE
https://juejin.cn/post/6847902224287285255#comment
从Reactv16开始,componentWillXXX钩子前增加了UNSAFE_前缀。
究其原因,是因为Stack Reconciler重构为Fiber Reconciler后,render阶段的任务可能中断/重新开始,对应的组件在render阶段的生命周期钩子(即componentWillXXX)可能触发多次。
这种行为和Reactv15不一致,所以标记为UNSAFE_。
为此,React提供了替代的生命周期钩子getSnapshotBeforeUpdate。
我们可以看见,getSnapshotBeforeUpdate是在commit阶段内的before mutation阶段调用的,由于commit阶段是同步的,所以不会遇到多次调用的问题。
Hooks
代数效应是函数式编程中的一个概念,用于将副作用从函数调用中分离。
那么代数效应与React有什么关系呢?最明显的例子就是Hooks。
对于类似useState、useReducer、useRef这样的Hook,我们不需要关注FunctionComponent的state在Hook中是如何保存的,React会为我们处理。
代数效应在浏览器原生就支持类似的实现就是Generator
但是Generator的一些缺陷使React团队放弃了他:
- 类似
async,Generator也是传染性的,使用了Generator则上下文的其他函数也需要作出改变。这样心智负担比较重。 Generator执行的中间状态是上下文关联的。
Hooks规则
https://zh-hans.reactjs.org/docs/hooks-rules.html
- 只在最顶层使用 Hook
不要在循环,条件或嵌套函数中调用 Hook, 确保总是在你的 React 函数的最顶层调用他们。遵守这条规则,你就能确保 Hook 在每一次渲染中都按照同样的顺序被调用。这让 React 能够在多次的 useState 和 useEffect 调用之间保持 hook 状态的正确。
Hooks原理
我们知道,更新产生的update对象会保存在queue中。
不同于ClassComponent的实例可以存储数据,对于FunctionComponent,queue存储在哪里呢?
答案是:FunctionComponent对应的fiber中。
我们使用如下精简的fiber结构:
// App组件对应的fiber对象
const fiber = {
// 保存该FunctionComponent对应的Hooks链表
memoizedState: null,
// 指向App函数
stateNode: App
};
可以看到,Hook与update类似,都通过链表连接。不过Hook是无环的单向链表。
hook = {
// 保存update的queue,即上文介绍的queue
queue: {
pending: null
},
// 保存hook对应的state
memoizedState: initialState,
// 与下一个Hook连接形成单向无环链表
next: null
}
注意
注意区分
update与hook的所属关系:每个
useState对应一个hook对象。调用
const [num, updateNum] = useState(0);时updateNum(即上文介绍的dispatchAction)产生的update保存在useState对应的hook.queue中。
useEffect
// 调度useEffect (在commit阶段 的before mutation阶段)
if ((effectTag & Passive) !== NoEffect) {
if (!rootDoesHavePassiveEffects) {
rootDoesHavePassiveEffects = true;
scheduleCallback(NormalSchedulerPriority, () => {
// 触发useEffect
flushPassiveEffects();
return null;
});
}
}
在这几行代码内,scheduleCallback方法由Scheduler模块提供,用于以某个优先级异步调度一个回调函数。
在此处,被异步调度的回调函数就是触发useEffect的方法flushPassiveEffects。
我们接下来讨论useEffect如何被异步调度,以及为什么要异步(而不是同步)调度。
useLayoutEffect与useEffect
useEffect和useLayoutEffect的执行时机不一样
- 前者被异步调度,当页面渲染完成后再去执行,不会阻塞页面渲染。
- 后者是在commit阶段新的DOM准备完成,但还未渲染到屏幕之前,同步执行。
mutation阶段会执行useLayoutEffect hook的销毁函数。
useLayoutEffect hook从上一次更新的销毁函数调用到本次更新的回调函数调用是同步执行的。
而useEffect则需要先调度,在Layout阶段完成后再异步执行。
这就是useLayoutEffect与useEffect的区别。
Effect数据结构
顾名思义,React底层在函数式组件的Fiber节点设计中带入了hooks链表的概念(memorizedState),在此变量上专门存储每一个函数式组件对应的链表。
而对于副作用(useEffect or useLayoutEffect)来说,对应其hook类型就是Effect。
单个的effect对象包括以下几个属性:
- create: 传入
useEffectoruseLayoutEffect函数的第一个参数,即回调函数; - destroy: 回调函数return的函数,在该effect销毁的时候执行,渲染阶段为
undefined; - deps: 依赖项,改变重新执行副作用;
- next: 指向下一个
effect; - tag: effect的类型,区分是
useEffect还是useLayoutEffect;
effect为什么需要异步调用
https://zh-hans.reactjs.org/docs/hooks-reference.html#timing-of-effects
与 componentDidMount、componentDidUpdate 不同的是,在浏览器完成布局与绘制之后,传给 useEffect 的函数会延迟调用。这使得它适用于许多常见的副作用场景,比如设置订阅和事件处理等情况,因此不应在函数中执行阻塞浏览器更新屏幕的操作。
可见,useEffect异步执行的原因主要是防止同步执行时阻塞浏览器渲染。
然而,并非所有 effect 都可以被延迟执行。例如,在浏览器执行下一次绘制前,用户可见的 DOM 变更就必须同步执行,这样用户才不会感觉到视觉上的不一致。(概念上类似于被动监听事件和主动监听事件的区别。)React 为此提供了一个额外的 useLayoutEffect Hook 来处理这类 effect。它和 useEffect 的结构相同,区别只是调用时机不同。
虽然 useEffect 会在浏览器绘制后延迟执行,但会保证在任何新的渲染前执行。React 将在组件更新前刷新上一轮渲染的 effect。
事件委托的变更
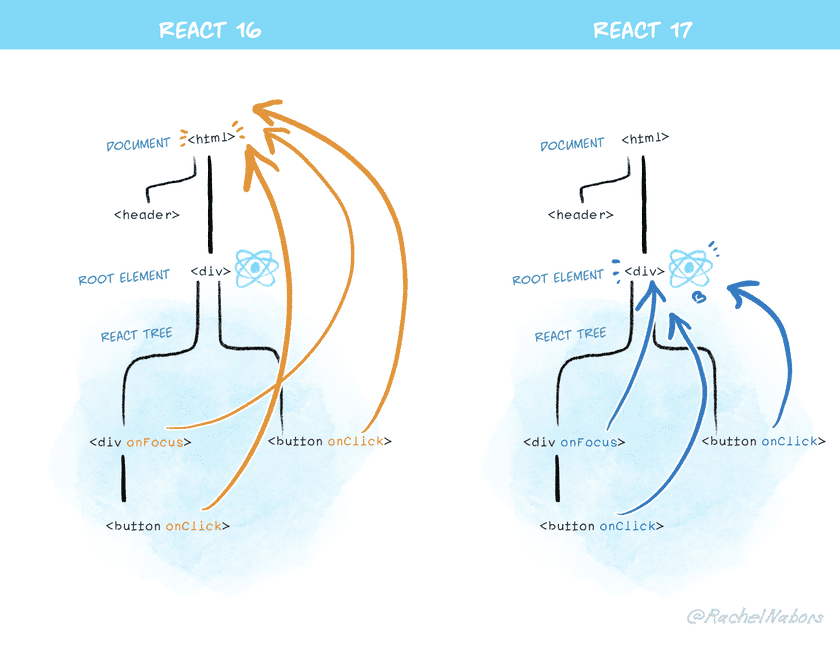
https://zh-hans.reactjs.org/blog/2020/10/20/react-v17.html#changes-to-event-delegation
React v17 中,React 不会再将事件处理添加到 document 上,而是将事件处理添加到渲染 React 树的根 DOM 容器中:
const rootNode = document.getElementById('root');
ReactDOM.render(<App />, rootNode);
在 React 16 及之前版本中,React 会对大多数事件进行 document.addEventListener() 操作。React v17 开始会通过调用 rootNode.addEventListener() 来代替。
全新的 JSX 转换
https://zh-hans.reactjs.org/blog/2020/09/22/introducing-the-new-jsx-transform.html
https://babeljs.io/blog/2020/03/16/7.9.0#a-new-jsx-transform-11154httpsgithubcombabelbabelpull11154
当你使用 JSX 时,编译器会将其转换为浏览器可以理解的 React 函数调用。旧的 JSX 转换会把 JSX 转换为 React.createElement(...) 调用。
例子:
import React from 'react';
function App() {
return <h1>Hello World</h1>;
}
旧的 JSX 转换会将上述代码变成普通的 JavaScript 代码:
import React from 'react';
function App() {
return React.createElement('h1', null, 'Hello world');
}
然而,这并不完美:
- 如果使用 JSX,则需在
React的环境下,因为 JSX 将被编译成React.createElement。 - 有一些
React.createElement无法做到的性能优化和简化。
为了解决这些问题,React 17 在 React 的 package 中引入了两个新入口,这些入口只会被 Babel 和 TypeScript 等编译器使用。新的 JSX 转换不会将 JSX 转换为 React.createElement,而是自动从 React 的 package 中引入新的入口函数并调用。
下方是新 JSX 被转换编译后的结果:
// 由编译器引入(禁止自己引入!)
import {jsx as _jsx} from 'react/jsx-runtime';
function App() {
return _jsx('h1', { children: 'Hello world' });
}
注意
react/jsx-runtime和react/jsx-dev-runtime中的函数只能由编译器转换使用。如果你需要在代码中手动创建元素,你可以继续使用React.createElement。它将继续工作,不会消失。
你需要更新至最新版本的 Babel(v7.9.0) 和 transform 插件。
https://babeljs.io/docs/en/babel-plugin-transform-react-jsx
https://github.com/babel/babel/tree/main/packages/babel-plugin-transform-react-jsx
Context和全局状态管理库
使用 Context API 的场景
- 小型应用:如果你的应用较小,状态管理的需求相对简单,Context API 足以满足大多数需求。
- 需要跨组件传递状态:如果你需要在多个组件之间共享一些简单的状态(比如主题、认证状态等),Context 是一个理想的选择。
- 没有复杂的状态逻辑:当状态更新的逻辑不复杂时(比如简单的值,或仅需要在父子组件之间传递状态),Context 会更容易实现。
- 易于实现:Context API 相对简单,适合快速原型开发或简化项目的状态管理。
使用全局状态管理库的场景
- 中大型应用:当应用变得复杂,需要处理多个状态切片以及它们之间的逻辑关系时,全局状态管理库可以提供更好的组织和可维护性。
- 复杂的状态逻辑:如果你需要对状态进行复杂的操作,比如异步请求、多个状态依赖或需要优化性能的更新,使用 Redux 等库会更为高效。
- 调试工具和开发支持:Redux 等状态管理库通常提供良好的调试工具和中间件,可以帮助你更好地跟踪和管理状态变化。
- 团队协作:如果多个开发者在同一项目中工作,使用状态管理库会对代码的可理解性和维护性有很大帮助。
Redux
Redux 源码深度解析
首先把多个 reducer 通过 combineReducers 组合在一起
const appReducer = combineReducers({
user: UserReducer,
goods: GoodsReducer,
order: OrdersReducer,
chat: ChatReducer
});
combineReducers 函数总的来说很简单,总结来说就是接收一个对象,将参数过滤后返回一个函数。该函数里有一个过滤参数后的对象 finalReducers,遍历该对象,然后执行对象中的每一个 reducer 函数,最后将新的 state 返回
接下来让我们先来看看 compose 函数
这个函数设计的很巧妙,通过传入函数引用的方式让我们完成多个函数的嵌套使用,术语叫做高阶函数
通过使用 reduce 函数做到从右至左调用函数
Redux解决了什么问题
单一数据源特性
Redux应用中的状态是只读的,即Redux状态不可变。例如,React组件不能直接写入Redux状态,而是发出action来更新状态。
只读状态
唯一可以修改状态的方式,就是发送(dispatch)一个动作(Action),通俗来讲,就是说只有getter,没有setter。
使用纯函数去修改状态
单向数据流
Redux 是 JavaScript 状态容器,提供可预测化的状态管理。 Redux 是由 Flux 演变而来。
对于 Redux 来说,就是把数据当成状态来处理,reducer 就是根据行为(action) 将当前数据(状态)转成新的状态,新的数据状态可以继续被 reducer 处理。
补充
vue和react的区别
https://zhuanlan.zhihu.com/p/100228073
- 监听数据变化的实现原理不同
Vue通过 getter/setter以及一些函数的劫持,能精确知道数据变化。
React默认是通过比较引用的方式(diff)进行的,如果不优化可能导致大量不必要的VDOM的重新渲染。为什么React不精确监听数据变化呢?这是因为Vue和React设计理念上的区别,Vue使用的是可变数据,而React更强调数据的不可变,两者没有好坏之分,Vue更加简单,而React构建大型应用的时候更加鲁棒。
-
触发更新机制:Vue 是通过响应式系统自动及时的进行触发,而 React 则是通过用户手动更改状态(比如 setState)的操作然后进行一系列调度来触发更新。
-
HoC和mixins
-
组件通信的区别
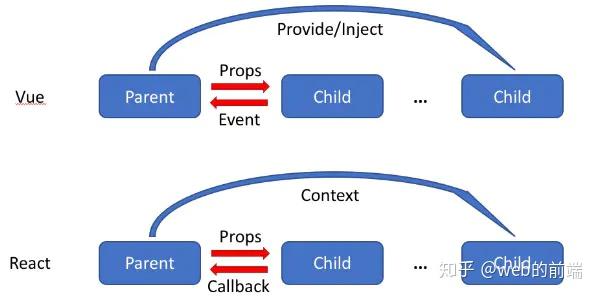
Vue中有三种方式可以实现组件通信:父组件通过props向子组件传递数据或者回调,虽然可以传递回调,但是我们一般只传数据;子组件通过事件向父组件发送消息;通过V2.2.0中新增的provide/inject来实现父组件向子组件注入数据,可以跨越多个层级。
React中也有对应的三种方式:父组件通过props可以向子组件传递数据或者回调;可以通过 context 进行跨层级的通信
- 模板渲染方式的不同
在表层上,模板的语法不同,React是通过JSX渲染模板。而Vue是通过一种拓展的HTML语法进行渲染,但其实这只是表面现象,毕竟React并不必须依赖JSX。
在深层上,模板的原理不同,这才是他们的本质区别:React是在组件JS代码中,通过原生JS实现模板中的常见语法,比如插值,条件,循环等,都是通过JS语法实现的,更加纯粹更加原生。而Vue是在和组件JS代码分离的单独的模板中,通过指令来实现的,比如条件语句就需要 v-if 来实现
- 渲染过程不同
Vue可以更快地计算出Virtual DOM的差异,这是由于它在渲染过程中,会跟踪每一个组件的依赖关系,不需要重新渲染整个组件树。
React在应用的状态被改变时,全部子组件都会重新渲染。通过shouldComponentUpdate这个生命周期方法可以进行控制,但Vue将此视为默认的优化。
变化侦测分为两种类型:一种是“推”(push),另一种是“拉”(pull)。
- Angualar和React中的变化侦测都属于“拉”,这就是说当状态发生变化时,它不知道哪个状态变了,只知道状态有可能变了,然后会发送一个信号告诉框架,框架内部收到信号后,会进行一个暴力对比来找出哪些DOM节点需要重新渲染。这在Angualar中是脏检查的流程,在React中使用的是虚拟DOM。
- Vue.js的变化侦测属于“推”。当状态发生变化时,Vue.js立刻就知道了,而且在一定程度上知道哪些状态变了。因此,它知道的信息更多,也就可以进行更细粒度的更新。
所谓更细粒度的更新,就是说:假如有一个状态绑定着好多个依赖,每个依赖表示一个具体的DOM节点,那么当这个状态发生变化时,向这个状态的所有依赖发送通知,让它们进行DOM更新操作。想比较而言,“拉”的粒度是最粗的。
所谓更细粒度的更新,就是说:假如有一个状态绑定着好多个依赖,每个依赖表示一个具体的DOM节点,那么当这个状态发生变化时,向这个状态的所有依赖发送通知,让它们进行DOM更新操作。想比较而言,“拉”的粒度是最粗的。
但是它也有一定的代价,因为粒度越细,每个状态所绑定的依赖就越多,依赖追踪在内存上的开销就会越大。因此,从Vue.js2.0开始,它引入了虚拟DOM,将粒度调整为中等粒度,即一个状态所绑定的依赖不再是具体的DOM节点,而是一个组件。这样状态变化后,会通知到组件,组件内部再使用虚拟DOM进行对比。这可以大大降低依赖数量,从而降低依赖追踪所消耗的内存。
VUE2 采用中等粒度的方案,在组件级别是 push,每一个组件是一个响应式的 watcher,当数据变动之后可以直接知道哪些组件变了,组件可以进行更新,在组件内部使用 virtual dom 进行比对。
react 则是不检查,不检查难道每次都渲染全部的 dom 么? 也不是,不检查是因为不直接渲染到 dom,而是中间加了一层虚拟 dom,每次都渲染成这个虚拟 dom,然后 diff 下渲染出的虚拟 dom 是否变了,变了的话就去更新对应的 dom。
vuex 和 redux 的区别
在 Vuex 中,$store 被直接注入到了组件实例中,因此可以比较灵活的使用:
- 使用 dispatch 和 commit 提交更新
- 通过 mapState 或者直接通过 this.$store 来读取数据
在 Redux 中,我们每一个组件都需要显示的用 connect 把需要的 props 和 dispatch 连接起来。
- Redux 使用的是不可变数据,而Vuex的数据是可变的。Redux每次都是用新的state替换旧的state,而Vuex是直接修改
- Redux 在检测数据变化的时候,是通过 diff 的方式比较差异的,而Vuex其实和Vue的原理一样,是通过 getter/setter来比较的(如果看Vuex源码会知道,其实他内部直接创建一个Vue实例用来跟踪数据变化)
MVC,MVP 和 MVVM
https://www.ruanyifeng.com/blog/2015/02/mvcmvp_mvvm.html
vnode 有什么优势
首先是抽象,引入 vnode,可以把渲染过程抽象化,从而使得组件的抽象能力也得到提升。
其次是跨平台,因为 patch vnode 的过程不同平台可以有自己的实现,基于 vnode 再做服务端渲染、Weex 平台、小程序平台的渲染都变得容易了很多。
每个DOM上的属性多达 228 个,而这些属性有 90% 多对我们来说都是无用的。VNode 就是简化版的真实 DOM 元素,保留了我们要的属性,并新增了一些在 diff 过程中需要使用的属性,例如 isStatic。
使用 vnode 并不意味着不用操作 DOM 了,很多同学会误以为 vnode 的性能一定比手动操作原生 DOM 好,这个其实是不一定的。
性能并不是 vnode 的优势