“Yeah It’s on. ”
基础
Gateway
Gateway(网关)是一种网络设备或软件,用于连接两个或多个不同的网络,并提供数据传输和交换的功能。它在网络中起到转发和路由数据的作用,使得来自一个网络的数据可以被传递到另一个网络。网关可以连接不同的物理网络、协议和通信方式。
除了数据传输和交换的功能,网关还可以执行其他的网络服务,比如安全策略控制、网络地址转换(NAT)、防火墙、流量监控等。不同类型的网关有不同的功能和用途,如路由器、防火墙、代理服务器等。
在互联网中,ISP(互联网服务提供商)常常提供网关以连接用户的本地网络和互联网。此外,网关也可以用于连接企业内部的局域网(LAN)和广域网(WAN),以建立安全的远程连接和数据传输。
总之,网关是一个连接不同网络之间的中介设备或软件,它允许数据在不同网络之间传输和交换,并提供其他网络服务的功能。
dto
在后端开发中,DTO(Data Transfer Object)是一种数据传输对象的设计模式,它用于在各个层次之间传输数据。DTO定义了一组字段,这些字段只包含要在不同层之间传输的数据,通常不包含任何业务逻辑。DTO通常用于将数据从数据库层映射到服务层,或者将数据从服务层传递到表现层(如前端)。
DTO的设计目的是减少在不同层之间传输数据时的数据冗余和复杂性,提高代码的可读性和可维护性。通过使用DTO,可以明确地定义数据的结构和类型,同时还可以隐藏底层的数据访问细节。
12-factor apps
devops
https://www.zhihu.com/question/58702398
DevOps(Development和Operations的组合词)是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。透过自动化“软件交付”和“架构变更”的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。
线程和进程
Webhook
用于后端api和后端api之间的通信
https://www.redhat.com/zh/topics/automation/what-is-a-webhook
webhook 是一种基于 HTTP 的回调函数,可在 2 个应用编程接口(API)之间实现轻量级的事件驱动通信。许多种类的应用使用 webhook 来从其他应用接收少量数据,但 webhook 也可用于在 GitOps 环境中触发自动化工作流。
QPS 和 TPS
QPS(Queries Per Second,每秒查询率)和TPS(Transactions Per Second,每秒事务数)是衡量系统性能的核心指标,两者的核心差异在于操作粒度和业务完整性。
定义与核心区别
| 维度 | QPS | TPS |
|---|---|---|
| 核心含义 | 每秒处理的查询请求数(如API调用、数据库SELECT) | 每秒完成的完整业务流程数(如支付、订单处理) |
| 操作粒度 | 单一请求(例如:一次HTTP请求、一条SQL查询) | 包含多个步骤的业务流程(例如:支付需验证、扣款、生成订单) |
| 业务完整性 | 无需完整逻辑链,仅统计独立请求次数 | 要求事务的原子性,必须完成所有步骤才算一次有效事务 |
| 数值关系 | 通常 QPS ≥ TPS(一个事务可能触发多次查询 |
示例说明:
- 用户支付流程(TPS):验证账户 → 扣款 → 生成订单 → 返回结果(1个事务)。
- 支付中的操作(QPS):验证账户(1次查询)、扣款(1次更新)、检查库存(1次查询)→ 共3次查询。 若系统每秒处理100笔支付(TPS=100),则QPS至少为300(100×3)
适用场景对比
| 指标 | 典型场景 | 优化方向 |
|---|---|---|
| QPS | 搜索引擎、API接口、数据库查询 | 缓存加速(Redis)、索引优化、查询简化 |
| TPS | 支付系统、订单处理、银行转账 | 分布式事务、锁竞争优化、分库分表 |
场景案例:
- 电商大促:优化支付链路(提升TPS)保障交易成功率;优化商品查询(提升QPS)加快页面加载。
- 社交平台:加载动态页需请求图文、评论、点赞(1次TPS=页面加载完成,3次QPS=资源请求
- QPS是“请求吞吐量”:衡量系统处理独立查询的能力,适合优化高频读场景(如搜索、API)。
- TPS是“业务吞吐量”:衡量系统完成端到端业务流程的能力,适合优化事务型系统(如支付、订单)。
- 协同优化
- 高QPS ≠ 高TPS(例:缓存提升查询QPS,但支付事务仍需保障数据一致性)
- 实际系统需同时监控两者:如电商下单时,QPS反映页面资源加载效率,TPS反映订单成功率。
时间回拨
时间回拨是指系统的时钟在某个时间点之后突然往回走(人为设置),即出现了时间上的逆流情况。
时间回拨在计算机系统中很常见,特别是在分布式系统中。当多台计算机之间存在时间不一致或者时间错误时,需要通过时间回拨来将系统时间进行同步,以确保各个计算机之间的操作和事件记录的一致性。
时间回拨也可以发生在操作系统或应用程序中,例如在某些特殊情况下需要将系统时间回拨来模拟过去的时间场景,或者进行时间故障的调试和修复。
ID
自增ID
懂得都懂
UUID
https://www.cockroachlabs.com/blog/what-is-a-uuid/
UUID是通用唯一标识符(Universally Unique Identifier)的缩写,也称为GUID(全局唯一标识符)。它是一种标识符,用于在计算机系统中唯一地标识信息,以便在不同的系统和网络中进行交流和识别。
UUID是一个128位的,通常以字符串的形式表示,由32个十六进制数组成,并用连字符分隔。UUID的生成算法是根据计算机的MAC地址、当前时间戳、随机数等信息生成的,保证了生成的标识符在全球范围内的唯一性。
一个16进制数由4位二进制数表示,所以一个16进制数占用4位。
UUID的主要优点是生成方便,几乎可以在任何地方生成一个全局唯一的标识符,而不需要中央注册机构进行管理。因此,UUID广泛应用于分布式系统、数据库、网络协议等领域,用于唯一标识不同的实体或数据。
A UUID – that’s short for Universally Unique IDentifier, by the way – is a 36-character alphanumeric string that can be used to identify information. They are often used, for example, to identify rows of data within a database table, with each row assigned a specific UUID.
例子:
acde070d-8c4c-4f0d-9d8a-162843c10333
优点:
- 全球唯一性:UUID是根据一定规则生成的,理论上可以保证全球范围内的唯一性。
- 无需中心化管理:生成UUID的算法基本上是随机的,不需要集中的管理和分配,不会产生冲突。
- 不依赖于数据库:UUID可以独立于数据库生成,可以在分布式系统中保证数据的唯一性。
缺点:
- 可读性差:UUID是由32位十六进制数字组成的字符串,对人类来说不太容易理解和记忆。
- 增加存储空间:UUID是一个128位的数字,相较于较短的主键或者自增长ID,占用的存储空间更大。
- 查询效率低:由于UUID是随机生成的,无法通过递增的方式排序和索引,会影响到数据库的查询效率。
怎么保证UUID的唯一性?
- 时间戳:UUID的前32位是基于当前时间的低位。这样做是为了确保生成UUID的独特性,因为时间戳会不断增加。
- 时钟序列号:接下来的16位用于保证生成UUID的独特性。如果在同一时刻生成多个UUID,时钟序列号会递增以确保其唯一性。
- 以太网地址:UUID的后48位用于唯一标识计算机或设备的以太网地址。这个地址通常是设备的MAC地址。
通过这些组成部分的结合,UUID的生成算法能够在所有计算机和网络上生成唯一的标识符。
雪花ID
snowflake是Twitter开源的分布式ID生成算法,长度为 64 位,Long类型的ID,有着全局唯一和有序递增的特点。
152075078181383514 (雪花ID 比 UUID 更短)
雪花 ID 的长度为 64 位,1bit保留 + 41bit时间戳 + 10bit机器 + 12bit序列号。
缺点也是有的,就是强依赖机器时钟,如果机器上时钟回拨,有可能会导致主键重复的问题。
使用 UUID 替代雪花 ID 行不行?
单从唯一性来考虑的话,那么 UUID 和雪花 ID 的效果是一致的,二者都能保证分布式系统下的数据唯一性,但是即使这样,也不建议使用 UUID 替代雪花 ID,因为这样做的问题有以下两个:
- 可读性问题:UUID 内容很长,但没有业务含义,就是一堆看不懂的“字母”。
- 性能问题:UUID 是字符串类型,而字符串类型在数据库的查询中效率很低。
集群
集群是指将多个独立的计算机系统通过网络互联,以形成一个整体,共同完成某个复杂任务的计算机系统。
集群系统中的每个计算机节点被称为节点,节点之间通过网络进行通信和协作。集群采用并行计算的方式,将任务分解成多个小任务,并由每个节点分别执行,最后将实现的结果合并起来,提高计算效率和可靠性。集群广泛应用于高性能计算、大数据处理、云计算、分布式存储等领域。
quorum
翻译: 法定人数
集群的quorum是指集群中的多数成员必须达成共识才能进行重要的决策或操作的一种机制。在分布式系统中,quorum是一种有效的解决并发冲突和数据一致性的方法。
具体而言,quorum指的是集群中需要参与决策的成员的最小数量。例如,如果集群有5个成员,并且quorum设置为3,则至少需要3个成员达成共识才能进行重要操作。这种方式可以防止由于网络故障、成员失效或其他原因导致的部分决策和不一致的出现。
Quorum机制可以确保集群中多数成员的一致性,并提高系统的可用性和稳定性。它在分布式数据库、分布式存储系统、分布式文件系统等分布式系统中经常被使用。
锁
锁(Lock)是一种并发控制机制,用于保护共享资源的访问,确保在多线程或多进程环境下的数据一致性和并发安全性。
常见的锁包括:
- 互斥锁(Mutex):提供了独占访问的能力,在同一时间只有一个线程可以持有该锁。
- 读写锁(ReadWrite Lock):允许多个线程在没有写操作时并发地读取共享资源,但只有一个线程可以进行写操作。
- 自旋锁(Spin Lock):在获取锁失败时,线程会循环不停地尝试获取锁,而不进入阻塞状态,适用于临界区很短暂的情况。
- 条件变量(Condition Variable):用于线程之间的等待和通知,允许线程在某个条件满足或等待其他线程通知后继续执行。
悲观锁
- 假设并发访问时会发生冲突,因此在操作之前先获取锁,阻止其他线程操作该资源。
- 在获取锁期间,其他线程无法对该资源进行读或写,只有锁被释放后才能继续操作。
- 适用于并发冲突较多的场景,例如数据库中的行级锁或表级锁。
- 使用悲观锁会导致阻塞和上下文切换的开销增加,但可以保证数据的一致性和并发安全。
举个例子:
行级锁(Row-Level Lock):行级锁是一种在行级别进行的锁定操作,可以更细粒度地控制并发访问。在SQL中,可以通过在事务中使用SELECT ... FOR UPDATE语句的条件约束来获取行级锁。只有满足特定条件的数据行才会被锁定。
BEGIN TRANSACTION;
SELECT * FROM table_name WHERE column_name = 'value' FOR UPDATE;
-- 对查询结果进行操作
COMMIT;
乐观锁
- 假设并发访问时不会发生冲突,允许多个线程同时进行操作,但在更新数据时会检查是否与其他线程的操作冲突。
- 在读取数据时,会记录当前的版本号或时间戳。
- 在更新数据时,会检查当前的版本号或时间戳是否与记录的一致,如果一致则更新成功,否则操作失败需要重试或放弃更新。
- 适用于读多写少的场景,例如缓存、乐观并发控制算法(如CAS)等。
- 使用乐观锁可以避免阻塞和等待,但可能需要重试操作,且无法保证数据的一致性。
举个例子:
在SQL数据库中
版本号(Versioning):为数据表添加一个表示版本的字段,每次更新数据时都会对该字段进行更新。当事务提交时,会比较版本号是否一致,如果一致则更新成功,否则表示数据已被修改,需要回滚事务并重试。
-- 创建带版本号的表
CREATE TABLE table_name (
id INT PRIMARY KEY,
data VARCHAR(255),
version INT DEFAULT 1
);
-- 更新数据时更新版本号
UPDATE table_name SET data = 'new_data', version = version + 1 WHERE id = 1 AND version = old_version;
-- 提交事务时检查版本号
COMMIT;
分布式锁
保持数据一致性
在集群中的问题
无锁
https://www.cnblogs.com/cosmos-wong/p/11902088.html
无锁是一种乐观的策略,它假设线程访问共享资源不会发生冲突,所以不需要加锁,因此线程将不断执行,不需要停止。一旦碰到冲突,就重试当前操作直到没有冲突为止。
无锁的策略使用一种叫做比较交换的技术(CAS Compare And Swap)来鉴别线程冲突,一旦检测到冲突产生,就重试当前操作直到没有冲突为止。(CAS操作属于乐观派)
CAS全称是Compare and swap。字面翻译的意思就是比较并交换。
CAS是系统原语,CAS操作是一条CPU的原子指令,所以不会有线程安全问题
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值。否则,处理器不做任何操作。无论哪种情况,它都会在 CAS 指令之前返回该位置的值。(在 CAS 的一些特殊情况下将仅返回 CAS 是否成功,而不提取当前值。)CAS 有效地说明了“我认为位置 V 应该包含值 A;如果包含该值,则将 B 放到这个位置;否则,不要更改该位置,只告诉我这个位置的值即可。”
分布式
分布式架构
分布式架构:分布式系统是若干独立计算机的集合,这些计算机对用户来说就像单个相关系统,即整个系统是由不同的计算机组成,而用户是无感知的,就像访问一台计算机一样。这里强调的是系统由不同物理上分离的计算机(服务器)组成。
主从架构
主从架构(Master-slave architecture)是一种分布式系统架构模式,其中一个节点作为主节点(Master)负责协调和管理其他节点(从节点/Slave),从而实现任务的分配和处理。主节点负责接收和处理客户端请求,然后将任务分发给从节点处理,从节点负责执行主节点分配给它的任务。主节点负责监控从节点的状态,并在从节点故障时重新分配任务到其他可用的从节点。主从架构可以提高系统的可伸缩性、可靠性和性能。 在主从架构中,主节点负责处理复杂的任务、存储系统的元数据和协调节点之间的通信。从节点负责执行实际的任务,如计算、存储数据等。主从架构通常用于数据库、分布式存储系统和分布式计算集群等场景,以提高系统的性能和容错能力。
base理论
cap 理论
分布式事务
tcc
时间戳
在分布式系统中,时间戳是用来标记事件发生的顺序和时间的重要信息。由于分布式系统中的不同节点可能位于不同的物理位置,并且可能存在网络延迟和时钟漂移等问题,因此确保分布式系统中的时间戳的一致性是一个挑战。
以下是几种常见的解决方案来处理分布式系统中的时间戳问题:
- 逻辑时钟:逻辑时钟是一种基于事件顺序而不是实际时间的时钟。它使用事件发生的顺序来为事件分配时间戳,而不依赖于实际的时钟时间。逻辑时钟通常采用向量时钟或Lamport时钟的形式来实现。
- 物理时钟同步:在分布式系统中,可以使用网络时间协议(Network Time Protocol,NTP)或物理时钟同步协议(Physical Clock Synchronization Protocol)来同步各个节点上的物理时钟,以确保它们的时间差不会太大。
- 时钟漂移校正:由于分布式系统中的节点可能存在时钟漂移,因此可以通过定期校正时钟来解决该问题。这可以通过使用定期的时钟校正算法来实现,其中节点将其时钟与其他节点进行比较并进行调整。
- 基于一致性时钟的算法:一致性时钟是一种特殊的时钟,可以在分布式系统中保持全局时间的一致性。这可以通过算法如Google的TrueTime或Spanner时钟来实现。
向量时钟和Lamport时钟
向量时钟和Lamport时钟是用于在分布式系统中对事件进行排序和同步的算法。
- 向量时钟:向量时钟是一种由多个进程维护的时钟机制,每个进程都有一个向量,每个向量的元素表示各个进程对其他进程的时间观。每当一个进程产生一个事件时,它将自己的向量自增,并将更新后的向量广播给其他进程。当进程收到其他进程的向量时,它会将自己的向量的相应位置更新为较大值。通过比较向量的大小,可以判断事件的先后顺序。向量时钟可以保证在任意两个事件之间保持因果关系,但不能保证全局时钟一致。
- Lamport时钟:Lamport时钟是一种逻辑时钟机制,每个进程维护一个递增的整数时钟,并在事件发生时将该时钟的值一并发送给其他进程。当进程收到其他进程的时钟值时,它会将自己的时钟值更新为较大值加一。通过比较时钟的大小,可以判断事件的先后顺序。Lamport时钟可以保证在任意两个事件之间保持因果关系,但不能保证全局时钟一致。
区别:
- 向量时钟是使用向量来记录各个进程的时间观,而Lamport时钟是使用递增整数时钟。
- 向量时钟可以保证因果关系,即如果事件A发生在事件B之前,那么向量时钟在A和B之间的比较也会反映这一关系。而Lamport时钟只能保证这种关系的近似,即如果事件A发生在事件B之前,那么Lamport时钟在A和B之间的比较可能会反映这一关系,但也可能不会。
- 向量时钟可以在不同进程之间保持一致性,每个进程都具有满足一定条件的全局时间观。而Lamport时钟不能保证全局一致性,每个进程只能维护自己的本地时间观。
CRDT
CRDT (Conflict-free Replicated Data Type) 是一种数据结构,用于在分布式系统中实现数据的复制和同步。它的设计目标是实现高可用性、强一致性和分区容错性,同时避免传统的基于锁或者是中心化的复制模型的限制。
CRDT 使用一种称为 “最后写胜出” 的原则来解决冲突。具体来说,每个节点在更新本地副本时都会为其分配一个唯一的时间戳,并将更新操作应用于该副本。当副本被传播到其他节点时,每个节点会将其与自己的副本进行比较,并根据时间戳选择最新的值来合并。这样,在没有网络分区的情况下,所有副本最终达成相同的值,即强一致性。
CRDT 可以支持并发更新,并且在网络分区恢复时能够自动合并不同副本的更新。它适用于需要处理大量并发更新操作或在网络不稳定的环境中运行的分布式系统。CRDT 可以应用于各种数据类型,如集合、映射和计数器等。
总之,CRDT 提供了一种在分布式系统中实现数据复制和同步的方法,它通过使用时间戳和最后写胜出的原则来解决冲突,从而实现了高可用性、强一致性和分区容错性。
发布
| 蓝绿部署 | 同时存在两个集群,两个集群中只有一个集群真正提供服务,另外一个集群测试、验证或待命 | 服务文档,版本回退简单,适用于各种场景的升级,大版本不兼容升级的或迭代兼容升级 | 浪费硬件资源,需要同时有两个集群,如果集群比较大,比如有1000个节点,这种方式几乎不可用 |
|---|---|---|---|
| 金丝雀部署 | 逐点部署,逐步替换线上服务 | 小步快跑,快速迭代 | 只能适用于兼容迭代的方式,如果是大版本不兼容的场景,就没办法使用这种方式了 |
灰度发布
又称之为金丝雀发布
灰度发布是指在黑与白之间,能够平滑过渡的一种发布方式。
AB test就是一种灰度发布方式,让一部分用户继续用A,一部分用户开始用B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面来。灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。
蓝绿部署
成本比较高,现代企业很难承受
https://cloud.tencent.com/developer/article/1835861
蓝绿色部署是一种通过运行两个相同的称为 BLUE 和 GREEN 的生产环境来减少停机时间和降低风险的技术。
蓝绿部署,以颜色命名,简单的理解就是,线上有两套集群环境,在架构图中,一套标记成蓝色,称为蓝色集群BLUE;一套标记为绿色,称为绿色集群GREEN。通过将流量引入两个集群,完成系统升级切换。
消息队列
- 异步处理:消息队列能够将发送和接收消息的过程进行解耦,发送方不需要等待接收方处理完毕才能继续执行,而是将消息放入队列后立即返回。接收方则可以根据自身的处理能力和资源情况,逐条或批量地从队列中获取消息并进行处理。这种方式可以提高系统的吞吐量和响应速度,并且可以避免因为某个环节的延迟导致整个系统的性能下降。
- 解耦:消息队列可以将不同模块或不同系统之间的耦合度降低。发送方可以将消息发布到一个共享的消息队列中,而接收方可以通过订阅这个队列来接收消息。这样,当发送方需要改变处理逻辑或者新增其他消费者时,不会对接收方产生影响。消息队列也可以用来解决不同系统之间的数据一致性问题,通过将数据操作转变为消息发送,可以确保在处理失败时进行重试。
- 流量削峰平谷:消息队列对于流量的控制和调节也提供了支持。当系统中的请求过多导致资源不足时,可以将请求先放入消息队列中,然后按照系统的处理能力进行逐步消费,以避免系统的过载。同时,在系统资源闲置时,可以从消息队列中获取未被处理的消息进行消费,提高资源的利用率。
RocketMQ
half 消息
RabbitMQ
redis
Redis是一个开源的、高性能的键值对存储数据库。它以内存为主要存储方式,通过将数据存储在内存中来提供快速的读写性能。Redis支持多种数据结构,如字符串、列表、哈希表、集合等,并提供了丰富的命令集合,使得开发者能够灵活地使用和操作数据。它常用于缓存、消息队列、计数器、分布式锁等场景中,是非常流行的 NoSQL 数据库。
使用场景:
- 缓存:将常用的数据存储在内存中,以提高读取速度。例如,可以将数据库中的热数据缓存到Redis中,以减轻数据库的负载。
- 消息队列:Redis支持发布/订阅模式,可以用作分布式系统中的消息队列,实现异步消息传递。
- 计数器和排行榜:Redis支持原子操作,可以用来实现实时计数器和排行榜功能。
- 分布式锁:通过Redis的原子操作和过期时间设置,可以实现分布式系统中的互斥访问控制。
- 地理位置查询:Redis支持地理空间索引,可以存储和查询地理位置数据。
- 实时应用:Redis支持持久化,可以将实时应用程序中的临时状态存储在Redis中,以便于恢复。
- 秒杀活动:Redis的高并发读写能力可以支持秒杀活动中的高并发场景。
- 分布式缓存:Redis可以作为分布式缓存系统的一部分,提供数据的存储和访问功能。
install
https://redis.io/docs/latest/operate/oss_and_stack/install/install-redis/install-redis-on-mac-os/
redis-cli
redis-cli -h <host> -p <port> -a <password>
Go
参考go的blog
consul
Identity-based networking with Consul
Consul uses service identities and traditional networking practices to help organizations securely connect applications running in any environment.
Consul使用服务身份和传统的网络实践来帮助组织安全地连接在任何环境中运行的应用程序。
Consul提供了一组用于注册、发现和连接服务的功能,支持多种服务发现机制,包括DNS、HTTP和gRPC。它还提供了一种分布式一致性协议来确保服务注册数据的一致性和可靠性。Consul还具有丰富的可视化界面、健康检查功能和基于ACL的权限控制。总体来说,Consul提供了一种可靠的方法来管理和连接微服务架构中的各个服务。
Consul和Etcd
Consul和Etcd都是分布式键值存储系统,用于在集群中存储和同步数据,但它们也有一些区别。
- 一致性模型:Consul采用了强一致性模型,即读取和写入数据都会等待集群中的大多数节点确认。而Etcd则采用了弱一致性模型,即可能会存在短暂的数据不一致性。
- 功能特性:Consul提供了一些高级功能,如服务发现、健康检查、负载均衡、故障转移等。而Etcd则更加专注于分布式键值存储的基本功能。
- 架构设计:Consul采用Raft协议来实现一致性,每个节点都有相同的角色,可以进行读写操作。而Etcd也使用Raft协议,但采用了主从架构,其中的Leader节点用于处理写入请求,而Follower节点则用于处理读取请求。
- 数据模型:Consul支持键值对存储,同时还提供了额外的功能如短生命周期的会话、事件等。而Etcd则只支持简单的键值对存储。
综上所述,Consul适用于需要更高级功能的场景,如服务发现和负载均衡等;而Etcd则更适用于简单的键值存储需求。
grafana
Istio
https://istio.io/latest/about/service-mesh/
Istio addresses the challenges developers and operators face with a distributed or microservices architecture. Whether you’re building from scratch or migrating existing applications to cloud native, Istio can help.
calico
https://docs.tigera.io/calico/latest/about
Calico is a networking and security solution that enables Kubernetes workloads and non-Kubernetes/legacy workloads to communicate seamlessly and securely.
service/repostiory/dao 三层结构
DAO(Data Access Object)层
职责:DAO 层主要负责与数据库的直接交互。它封装了所有的数据库操作(如增、删、改、查),并将数据库的具体实现细节与应用程序的其他部分隔离开来。
Repository 层
职责:Repository 层(在某些架构中与 DAO 层合并)主要负责将 DAO 层的操作封装为应用程序的业务操作。它提供了更高层次的数据库操作接口,通常与业务逻辑更紧密。
Service 层
职责:Service 层负责处理应用程序的业务逻辑。它调用 Repository 层来获取和操作数据,并将数据转换为业务逻辑所需的格式。Service 层通常是应用程序的核心部分,负责实现具体的业务规则和逻辑。
HyperKit
HyperKit是一个轻量级的虚拟化工具,用于在macOS上运行轻量级Linux容器。它是Docker for Mac的一部分,由Docker公司开发和维护。HyperKit实际上是一个基于xhyve虚拟机技术的超轻量级Hypervisor,它使用macOS的核心框架Hypervisor.framework来运行和管理Linux容器。HyperKit提供了一种在macOS上本地运行和测试容器化应用程序的方式,可以提供与Linux环境相似的操作体验,并允许容器与macOS宿主机进行通信和共享资源。它主要用于开发和测试目的,让开发人员能够在本地开发环境中方便地构建和运行容器应用。
微服务
微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间互相协调、互相配合,为用户提供最终价值。
微服务鉴权
https://github.com/vianvio/FE-Companions/issues/62
每个微服务除了被用户调用,还有可能被其他的微服务调用,所以这里的鉴权,不仅要对用户鉴权,还要对微服务鉴权。
为了解决这个问题,可以采用单点登录的方案(SSO)
容器技术
容器技术
容器是一种通用技术,docker只是其中的一种实现
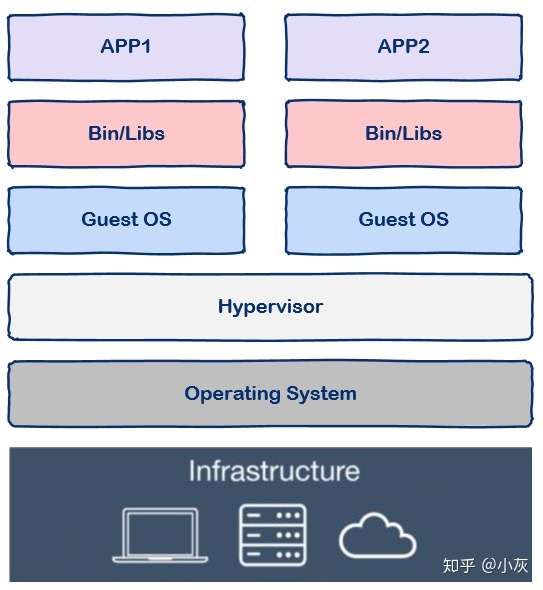
我们知道和一个单纯的应用程序相比,操作系统是一个很重而且很笨的程序
我们没有办法划分出更过虚拟机从而部署更多的应用程序,可是我们部署的是应用程序,要用的也是应用程序而不是操作系统。
如果有一种技术可以让我们避免把内存浪费在“无用”的操作系统上岂不是太香?这是问题一,主要原因在于操作系统太重了。
还有另一个问题,那就是启动时间问题,我们知道操作系统重启是非常慢的,因为操作系统要从头到尾把该检测的都检测了该加载的都加载上,这个过程非常缓慢,动辄数分钟,因此操作系统还是太笨了。
那么有没有一种技术可以让我们获得虚拟机的好处又能克服这些缺点从而一举实现鱼和熊掌的兼得呢?
答案是肯定的,这就是容器技术。
容器一词的英文是container,其实container还有集装箱的意思
首先,我们来看虚拟机中的隔离
下面我们来看容器技术,容器技术只隔离应用程序的运行时环境但容器之间可以共享同一个操作系统,这里的运行时环境指的是程序运行依赖的各种库以及配置。
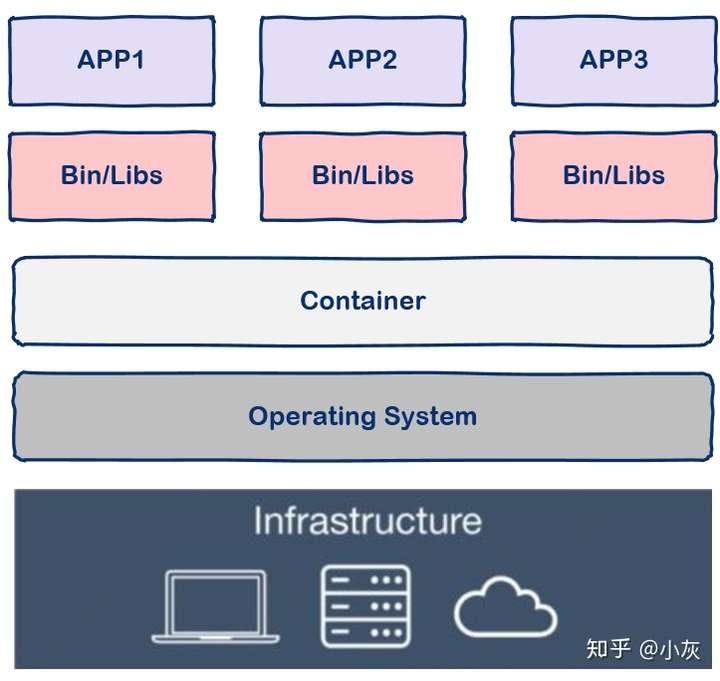
从图中我们可以看到容器更加的轻量级且占用的资源更少,与操作系统动辄几G的内存占用相比,容器技术只需数M空间,因此我们可以在同样规格的硬件上大量部署容器,这是虚拟机所不能比拟的,而且不同于操作系统数分钟的启动时间容器几乎瞬时启动,容器技术为打包服务栈提供了一种更加高效的方式
容器化解决了软件开发过程中一个令人非常头疼的问题,用一段对话描述:
测试人员:你这个功能有问题。
开发人员:我本地是好的啊。
开发人员编写代码,在自己本地环境测试完成后,将代码部署到测试或生产环境中,经常会遇到各种各样的问题。明明本地完美运行的代码为什么部署后出现很多 bug,原因有很多:不同的操作系统、不同的依赖库等,总结一句话就是因为本地环境和远程环境不一致。
容器化技术正好解决了这一关键问题,它将软件程序和运行的基础环境分开。开发人员编码完成后将程序打包到一个容器镜像中,镜像中详细列出了所依赖的环境,在不同的容器中运行标准化的镜像,从根本上解决了环境不一致的问题。
Docker
https://zhuanlan.zhihu.com/p/187505981
具体请查看docker 相关blog
kubernetes
Kubernetes 是谷歌开源的容器集群管理系统,是 Google 多年大规模容器管理技术 Borg 的开源版本,主要功能包括:
- 基于容器的应用部署、维护和滚动升级;
- 负载均衡和服务发现;
- 跨机器和跨地区的集群调度;
- 自动伸缩;
- 无状态服务和有状态服务;
- 插件机制保证扩展性。
cluster
在Kubernetes(k8s)中,cluster是指由一组物理或虚拟机器组成的集群,用于托管和运行应用程序。它是Kubernetes的核心部分,负责管理和调度容器化应用程序的部署、扩展和故障恢复。
一个Kubernetes集群由若干个主节点(master node)和工作节点(worker node)组成。主节点负责整个集群的管理和控制,包括调度应用程序、监控集群状态和处理部署的请求等。工作节点是运行容器化应用程序的机器,它们接收主节点的指令并执行相应的任务。
在一个Kubernetes集群中,主节点和工作节点之间通过网络进行通信。主节点通过API服务器接收和处理来自用户和管理员的命令,并将这些命令转化为集群的操作。工作节点运行Kubernetes代理(kubelet)和容器运行时(如Docker),负责管理和执行容器化应用程序的任务。
service
在Kubernetes中,Service(服务)是一个抽象层,用于将一组具有相同功能的Pod(容器)提供给其他应用或者用户。Service通过为Pod分配一个稳定的虚拟IP地址和一个DNS名称,为应用提供了一个稳定的访问入口。
Deployment
Kubernetes (k8s) 中的 Deployment 是一种资源对象,用于定义和管理应用程序的容器副本。它提供了一个声明式方式来管理容器化应用程序的部署。
expose deployment
expose deployment 是一种将 Deployment (部署)中的 Pods 暴露给集群内外其他应用访问的方法。通过使用 expose 命令,可以创建一个 Service(服务),该 Service 将为 Deployment 创建一个唯一的 DNS 名称,使其他应用能够通过该名称轻松地访问 Deployment 中的 Pods。
当使用kubectl expose deployment命令创建Service时,它会自动创建一个Service对象,将Deployment中的Pod暴露到Kubernetes集群内部网络上。你可以通过指定不同的Service类型和端口配置来控制外部访问。
LoadBalancer
在 Kubernetes (k8s) 中,LoadBalancer 是一种用于将网络流量均匀分发到多个后端服务的负载平衡器。它是 Kubernetes 的一种服务类型,用于向外部暴露集群中运行的服务。
在 Kubernetes 中,一个 LoadBalancer 服务通过分配一个可公开访问的外部 IP 地址,并将流量转发到该 IP 地址的后端服务上来实现负载均衡。这个外部 IP 地址由托管 Kubernetes 集群的云服务提供商来分配和维护。同时,LoadBalancer 还会监控后端服务的健康状态,根据需求对流量进行动态调整,以保证服务的可用性和可伸缩性。
在 k8s 中,用户可以通过定义一个 LoadBalancer 服务类型来创建一个负载均衡器。这个负载均衡器会使用云服务提供商的负载均衡器服务来实现负载均衡功能。用户可以指定不同的负载均衡算法和策略,以满足自己的需求。
tunnel
在Kubernetes中,tunnel(隧道)用于在不同的网络之间建立通信连接。具体来说,它可以用于以下用途:
- Pod之间的通信:Kubernetes集群中的Pod可能分布在不同的节点上,而节点可能属于不同的网络。通过使用隧道技术,可以在不同网络之间建立通信连接,使得Pod之间可以互相通信。这种隧道通信可以使用各种协议,如VXLAN、GRE等。
- Pod与Service之间的通信:Kubernetes的Service可以将一个逻辑上的一组Pod映射到一个虚拟的IP地址,并通过负载均衡将请求转发到实际的Pod上。通过隧道技术,可以将服务的虚拟IP和实际的Pod之间建立通信连接,使得外部请求可以通过服务IP访问到实际的Pod。
- 跨集群通信:在多集群的Kubernetes环境中,不同的集群可能属于不同的网络。通过隧道技术,可以在不同网络之间建立通信连接,实现集群之间的互相通信。
总的来说,隧道在Kubernetes中起到了连接不同网络的作用,使得Pod、Service或集群之间可以互相通信,并提供了网络隔离和安全性。
addon
Kubernetes(简称k8s)的addon是一组可选的功能插件,它们为k8s集群提供了一些附加功能和扩展能力。这些插件可以通过简单的配置方式安装和管理,以增强集群的功能和灵活性。
一些常见的k8s addon包括:
- Dashboard:一个基于Web的图形化用户界面,可以用于监控和管理k8s集群。
- DNS:为k8s集群中的Pod提供DNS解析功能,使得Pod可以通过域名进行通信。
- Ingress Controller:实现对k8s集群中的应用程序的访问控制和负载均衡,通过定义Ingress资源来配置应用程序的路由规则。
- Metrics Server:收集k8s集群中的资源利用率和性能指标,用于监控和自动扩展Pod。
- Logging and Monitoring:提供实时日志和监控的能力,以帮助运维人员快速诊断和解决问题。
- Storage Class:定义持久化存储的类型和属性,使得应用程序可以方便地使用存储卷进行数据持久化。
- Cluster Autoscaler:自动调整k8s集群中的节点数量,以匹配当前工作负载的需求。
这些addon可以根据实际需求进行选择和配置,以扩展和增强k8s集群的功能。
CNI
CNI 是 Container Network Interface(容器网络接口)的缩写,它是一个用于定义和配置容器运行时网络的规范。CNI 定义了插件接口以及与容器运行时(如 Docker、Kubernetes 等)交互的标准协议。
CNI 使得不同的容器运行时可以采用不同的网络插件,而不需要对核心功能进行修改。这样,用户可以根据自己的需求选择和切换不同的网络解决方案。CNI 插件可以用来配置容器的网络,包括创建和管理虚拟网络设备、IP 地址分配以及路由等操作。CNI 还支持多种网络模型,如主机模式、桥接模式、Overlay 网络等。
总之,CNI 是一个用于定义和配置容器运行时网络的标准接口,使得容器运行时和网络插件可以更加灵活地集成和协同工作。
声明式系统
Kubernetes 的所有管理能力构建在对象抽象的基础上,核心对象包括:
- Node:计算节点的抽象,用来描述计算节点的资源抽象、健康状态等。
- Namespace:资源隔离的基本单位,可以简单理解为文件系统中的目录结构。
- Pod:用来描述应用实例,包括镜像地址、资源需求等。 Kubernetes 中最核心的对象,也是打通应用和基础架构的秘密武器。
- Service:服务如何将应用发布成服务,本质上是负载均衡和域名服务的声明。
kubeadm 和 kubectl
- kubeadm(Kubernetes Admin)是一个命令行工具,用于创建和管理Kubernetes集群。它提供一种简化部署过程的方式,可以快速创建一个Kubernetes集群的初始配置,并安装必要的组件。kubeadm还可以用于升级Kubernetes版本,管理集群的网络和存储配置,以及添加或删除节点等操作。
- kubectl是Kubernetes的命令行控制工具,用于与Kubernetes集群进行交互。它可以用来管理集群中的各种资源,如Pod、Deployment、Service等。kubectl可以执行各种操作,如创建、删除、更新和查询资源对象,以及查看集群状态和事件等。它还支持通过命令行或YAML文件来配置和部署应用程序。
总结来说,kubeadm用于集群的创建和管理,而kubectl用于与集群进行交互和管理集群中的资源。
helm
The package manager for Kubernetes
平台工程
https://platformengineering.org/slack-rd
云原生
在包括公有云、私有云、混合云等动态环境中构建和运行规模化应用的能力。
云原生是一种思想,是技术、企业管理方法的集合。
云原生是从云的概念上衍生出来的。云原生不仅仅是一种技术,更是一种思想,它依托于一堆的技术和流程配合,使得应用能够更好地在云平台上运行。云原生鼓励一种动态的环境,使得应用能够更好地适应云平台的变化,从而保证应用的高可用性。因此,云原生和云是紧密相关的,云原生是为了更好地利用云平台提供的资源和服务而发展出来的一种技术和思想。
- 技术层面
- 应用程序从设计之初就为在云上运行而做好准备。
- 云平台基于自动化体系。
- 流程层面
- 基于 DevOps, CI/CD。
- 基于多种手段
- 应用容器化封装;
- 服务网格;
- 不可变基础架构;
- 声明式 API。
- 云原生的意义
- 提升系统的适应性、可管理性、可观察性;
- 使工程师能以最小成本进行频繁和可预测的系统变更。
- 提升速度和效率,助力业务成长,缩短 I2M(Idea to Market)。
nacos
https://nacos.io/zh-cn/docs/what-is-nacos.html
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service的首字母简称,一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
shell 编程
https://wangdoc.com/bash/intro
云计算
在数字化时代,互联网已经成为基础设施。云计算使得数据中心能够像一台计算机一样去工作。通过互联网将算力以按需使用、按量付费的形式提供给用户,包括:计算、存储、网络、数据库、大数据计算、大模型等算力形态。
云计算两个最明显的优势是弹性和敏捷:弹性能让您按需使用各类服务,灵活扩缩容,从容应对业务流量的不确定性。敏捷能让您快速部署应用而无需购买任何物理资源即可完成业务创新。
Raft协议
https://thesecretlivesofdata.com/raft/
Raft协议基于quorum机制,即大多数同意原则,任何的变更都需超过半数的成员确认
RAFT协议是一种共识算法, 用于在分布式系统中选择一个领导者节点, 以确保数据的一致性和可用性。RAFT协议是由Diego Ongaro和John Ousterhout在2013年提出的。 RAFT协议的核心思想是将领导者的选举过程分解为三个独立的子问题:领导者选举、日志复制和安全性。
由于RAFT协议的可理解性和高可用性,它在分布式系统中得到了广泛应用,比如etcd、Consul等系统就采用了RAFT协议。
3种角色:
分别是Leader(领导者)、Follower(追随者)和Candidate(候选人)。这些角色在分布式系统中协同工作,以实现一致性和容错性。在正常情况下,一个节点将担任Follower角色,接收来自Leader的心跳消息以保持同步。如果Follower在一段时间内没有收到Leader的心跳消息,它将成为Candidate角色,发起新的选举。节点在成为Candidate后,将请求其他节点投票,并通过接收大多数节点的投票来成为新的Leader。Leader负责处理客户端的请求,它在日志复制过程中将日志分发给Followers,并确保集群中的每个节点保持同步。
Raft 4.2.1引入的新角色 => Learner 当出现一个etcd集群需要增加节点时,新节点与Leader的数据差异较大,需要较多数据同步才能跟上leader的最新的数据。 此时Leader的网络带宽很可能被用尽,进而使得leader无法正常保持心跳。进而导致follower重新发起投票。进而可能引发etcd集群不可用。 Learner角色只接收数据而不参与投票,因此增加learner节点时,集群的quorum不变。
swagger
Swagger 是一种用于设计、构建、文档化和使用 RESTful 风格的 Web 服务的开源工具和框架。它定义了一种规范,可以帮助开发人员自动生成可交互的 API 文档。Swagger 提供了一种简单易用的方式来描述 API 的结构和行为,并通过可以用于各种编程语言的代码生成工具,使开发人员能够快速地构建和集成 API。通过使用 Swagger,开发人员可以更好地理解和使用 RESTful API,以及与其他开发人员共享和协作开发 API。
elastic
elastic连接elasticsearch时自动转换连接地址
elastic.SetSniff(false)
elasticsearch
elastic.NewClient(
// Must turn off sniff in docker
// 不会自动转换地址
elastic.SetSniff(false))
Sniffing
https://juejin.cn/post/6959746724995072031
Kafka
Kafka 是一种分布式流处理平台和高吞吐量的发布订阅消息系统。它在2010年由LinkedIn开发,之后被Apache软件基金会接受并成为一个Apache项目。Kafka 提供了持久化、高可靠性、可水平扩展的消息传递系统,可以处理用于日志收集、流处理、事件源等各种实时数据流的需求。
Kafka 主要由消息生产者、消息消费者和消息代理(broker)组成。生产者将消息发布到 Kafka 主题(topic),然后消费者可以订阅这些主题并接收消息。Kafka 的消息存储机制是基于磁盘的持久化存储,这使得它能够处理大规模的消息流并实现高吞吐量。
Makefile
Makefile 是一个用于指导 make 工具如何编译和链接程序的文件。它在自动化构建过程中扮演着重要角色,特别是在管理大型项目时。以下是 Makefile 的主要作用和基本用法:
主要作用
- 自动化构建:定义编译和链接程序的规则,使得构建过程自动化。
- 依赖管理:管理文件之间的依赖关系,确保只有必要的文件被重新编译。
- 简化复杂构建过程:通过定义规则和变量,简化复杂的构建过程。
- 提高效率:通过增量构建,只重新编译发生变化的部分,提高构建效率。
基本结构
一个典型的 Makefile 包含以下元素:
- 目标(target):要生成的文件或执行的操作。
- 依赖(dependencies):生成目标所依赖的文件。
- 命令(commands):生成目标所需执行的命令。
示例
以下是一个简单的 Makefile 示例,用于编译一个名为 main 的可执行文件:
# 定义编译器和编译选项
CC = gcc
CFLAGS = -Wall -g
# 目标文件
TARGET = main
# 目标文件依赖的源文件
SRCS = main.c foo.c bar.c
OBJS = $(SRCS:.c=.o)
# 默认目标
all: $(TARGET)
# 链接目标文件
$(TARGET): $(OBJS)
$(CC) $(CFLAGS) -o $(TARGET) $(OBJS)
# 编译源文件
%.o: %.c
$(CC) $(CFLAGS) -c $< -o $@
# 清理生成的文件
clean:
rm -f $(TARGET) $(OBJS)
解释
- 变量定义:
CC:指定编译器,这里是gcc。CFLAGS:编译选项,启用所有警告并启用调试信息。TARGET:生成的目标文件名,这里是main。SRCS:源文件列表。OBJS:将源文件列表转换为目标文件列表。
- 默认目标:
all: $(TARGET):默认目标是all,它依赖于$(TARGET)。
- 目标规则:
$(TARGET): $(OBJS):定义如何生成目标文件$(TARGET)。它依赖于目标文件列表$(OBJS)。$(CC) $(CFLAGS) -o $(TARGET) $(OBJS):链接目标文件,生成可执行文件。
- 模式规则:
%.o: %.c:定义如何从.c文件生成.o文件。$(CC) $(CFLAGS) -c $< -o $@:编译源文件生成目标文件。
- 清理规则:
clean:定义清理规则,删除生成的目标文件和中间文件。
使用
在命令行中使用 make 命令来执行 Makefile 中的规则:
make # 执行默认目标
make clean # 执行清理规则
总结
Makefile 是一个强大的工具,用于自动化和管理构建过程。它通过定义目标、依赖和命令,使得复杂的构建过程变得简单高效。合理使用 Makefile 可以显著提高开发和构建效率。
补充
虚拟网络
虚拟网络是一种通过软件技术在物理网络基础上创建的逻辑网络。它可以将多个物理网络资源(如服务器、路由器、交换机)组合起来,形成一个逻辑上独立的自定义网络环境。
虚拟网络提供了以下功能和特点:
- 隔离性:虚拟网络可以将不同的用户、应用或工作负载隔离开来,使它们互不干扰,增强了安全性和性能。
- 弹性和灵活性:虚拟网络可以根据需求进行动态调整和部署,使网络资源的使用更加灵活和高效。
- 多租户支持:虚拟网络可以支持多个租户同时使用,并为每个租户提供独立的网络资源和隔离环境。
- 路由和转发功能:虚拟网络可以通过虚拟路由器和虚拟交换机等技术实现网络数据的路由和转发,使网络流量能够正确地传输到目标地址。
- 虚拟化管理:虚拟网络可以通过虚拟化管理工具进行管理和监控,方便管理员对网络资源进行配置、监控和维护。
虚拟网络在云计算、数据中心、软件定义网络(SDN)等领域广泛应用,提供了更高效、灵活和可扩展的网络解决方案。
虚拟网卡是一种软件定义的网络设备,它在操作系统中被创建和使用。虚拟网卡可以模拟物理网卡的功能,包括接收和发送网络数据包。虚拟网卡通常用于虚拟化环境中,例如虚拟机、容器等。在虚拟化环境中,每个虚拟机或容器都可以有一个或多个虚拟网卡,它们可以连接到虚拟网络或物理网络中,并与其他设备进行网络通信。虚拟网卡可以帮助隔离和管理网络流量,实现虚拟环境中的网络互连、隔离和安全访问等功能。
Veth
Veth是一个网络设备,它是Virtual Ethernet的缩写。在计算机网络中,veth通常用于创建虚拟网络接口对,其中一个接口连接到主机的某个网络命名空间,另一个接口连接到另一个网络命名空间或容器。veth对允许在不同网络命名空间或容器之间进行通信提供了一种有效的方法。
分布式和微服务的区别
- 概念层面不同
微服务架构:微服务是设计层面的东西,一般考虑如何将系统从逻辑上进行拆分,也就是垂直拆分。微服务可以是分布式的,即可以将不同服务部署在不同计算机上,当然如果量小也可以部署在单机上。
分布式架构:分布式是部署层面的东西,即强调物理层面的组成,即系统的各子系统部署在不同计算机上。
- 解决问题不同
微服务架构:微服务解决的是系统复杂度问题: 一般来说是业务问题,即在一个系统中承担职责太多了,需要打散,便于理解和维护,进而提升系统的开发效率和运行效率,微服务一般来说是针对应用层面的。微服务如果用在其它系统,如存储系统感觉怪怪的,就像说Mysql集群是微服务的,总觉得哪里不舒服。
分布式架构:分布式解决的是系统性能问题: 即解决系统部署上单点的问题,尽量让组成系统的子系统分散在不同的机器上进而提高系统的吞吐能力。
- 部署方式不同
微服务架构:微服务的应用可以部署在是同一个服务器,不一定是分散在多个服务器上。微服务架构是一项在云中部署应用和服务的新技术。微服务架构是一种架构模式,它将一个复杂的大型应用程序划分成多个微服务,这些小型服务都在各自独立的进程中运行。
分布式架构:分布式是将一个大的系统划分为多个业务模块,这些业务模块会分别部署到不同的机器上,通过接口进行数据交互。
分布式是否属于微服务?
答案是属于。微服务的意思也就是将模块拆分成一个独立的服务单元通过接口来实现数据的交互。但是微服务不一定是分布式,因为微服务的应用不一定是分散在多个服务器上,他也可以是同一个服务器。这也是分布式和微服务的一个细微差别。
压测
压测离不开 2 个重点指标:QPS 与 并发处理数。它们的结果用于衡量业务面临的请求压力。
并发处理数 = QPS * 单个请求的平均耗时[秒]
脑裂问题
脑裂(split-brain)就是“大脑分裂”,本来一个“大脑”被拆分成两个或多个。
https://cloud.tencent.com/developer/article/1913575
在Elasticsearch、ZooKeeper这些集群环境中,有一个共同的特点,就是它们有一个“大脑”。比如,Elasticsearch集群中有Master节点,ZooKeeper集群中有Leader节点。
集群中的Master或Leader节点往往是通过选举产生的。在网络正常的情况下,可以顺利的选举出Leader(后续以Zookeeper命名为例)。但当两个机房之间的网络通信出现故障时,选举机制就有可能在不同的网络分区中选出两个Leader。当网络恢复时,这两个Leader该如何处理数据同步?又该听谁的?这也就出现了“脑裂”现象。
运维和SRE
运维和SRE 都是为了确保系统的可靠性和稳定性,但它们的职责和重点不同。 传统的运维人员更注重于系统的监控、维护和故障排除,而SRE 工程师则更注重于通过自动化和工程方法来提高系统的可靠性和可伸缩性。
Site Reliability Engineer (SRE):
- 不再负责和物理设备打交道,这部分交给云服务了。
- 通过体系化的手段来保障业务稳定性,比如构建自动化工具,和研发团队一起制定 SLO (Service Level Objective),让双方有可以一起遵守的契约,来保证服务的健康度。
- 工程研发能力。SRE 也可以说是具备研发能力的运维,有些 SRE 还具备很强的研发能力
DevOps
如果拿足球来打比方,研发,SRE ,运维对应的就是前锋,中场,后卫这样的位置,而 DevOps 则是诸如 4-3-3 这样的阵型。
以太坊
以太坊(Ethereum)是一种基于区块链技术的开源平台,旨在支持智能合约的创建和执行。与比特币等其他加密货币不同,以太坊提供了一个更加全面的区块链平台,可以通过智能合约构建和运行去中心化的应用程序(DApps)。
以太坊平台的核心是以太币(Ether,简称ETH),作为平台上的虚拟货币,用于支付交易费用和奖励矿工。以太坊的智能合约是一种自动执行的合约,其中包含了事先定义好的规则和条件。这些合约可以用于各种应用,如数字资产的发行与管理、去中心化金融、供应链追溯、投票和身份验证等。以太坊的智能合约功能使得开发者可以构建各种不同类型的去中心化应用,从而实现更广泛的应用场景。
以太坊的目标是建立一个去中心化的全球计算机,让任何人都能够建立和运行自己的应用程序,无需依赖传统中心化服务提供者。以太坊的区块链技术和智能合约功能为开发者和用户提供了更多的创新空间和自由度,目前已经成为最具活力和广泛应用的区块链平台之一。
ethers.js
https://learnblockchain.cn/ethers_v5/
ethers.js库旨在为以太坊区块链及其生态系统提供一个小而完整的 JavaScript API 库,它最初是与 ethers.io 一起使用,现在已经扩展为更通用的库。
web3.js
如果我们使用JavaScript 来开发 DApp时,很多时候需要使用到 web3.js (当然也可以选择使用 ethers.js)。
https://learnblockchain.cn/docs/web3.js/
web3.js 是一组使用HTTP或IPC连接来和本地或远程以太坊节点进行交互的库。