“Yeah It’s on. ”
正文
基础
with关键字
with语句的作用是将代码的作用域设置到一个特定的作用域中
基本语法如下:
with (expression) statement;
使用with关键字的目的是为了简化多次编写访问同一对象的工作,比如下面的例子:
var qs = location.search.substring(1);
var hostName = location.hostname;
var url = location.href;
这几行代码都是访问location对象中的属性,如果使用with关键字的话,可以简化代码如下
with (location){
var qs = search.substring(1);
var hostName = hostname;
var url = href;
}
在这段代码中,使用了with语句关联了location对象,这就以为着在with代码块内部,每个变量首先被认为是一个局部变量,如果局部变量与location对象的某个属性同名,则这个局部变量会指向location对象属性。
注意:在严格模式下不能使用with语句。
with关键字的弊端
- 性能问题
- 语义不明,调试困难
在for循环中使用可能会遇到的坑
https://blog.csdn.net/a727911438/article/details/55224532
var arr = new Array(1, 2, 3, 4, 5); //初始化数字集合
var delete_number = 3; //要被删除的数字
//遍历数组
for(var i=0; i<arr.length; i++){
if(arr[i] === delete_number){ //如果找到要被删除的数字所在的数组下标
var num = arr.splice( i, 1 ); //从i位置开始删除1个数字
console.log("成功删除 "+num); //输出被删除的数字
}
else{
console.log(arr[i]+" 未被删除"); //如果i下标的数组元素不是需要被删除的数字,就输出数字
}
}
输出
1 未被删除
2 未被删除
成功删除 3
5 未被删除
splice 是直接操作并修改数组的,所以当找到数字3时在循环中的 i 下标是2,而当删除数字3后,数组下标 i 位置中保存的数字变为了数字4,然后到了下一个循环 i 下标为3时,数组下标 i 位置中保存的数字是5,所以跳过了数字4
解决方案
if(arr[i] === delete_number){ //如果找到要被删除的数字所在的数组下标
var num = arr.splice( i, 1 ); //从i位置开始删除1个数字
console.log("成功删除 "+num); //输出被删除的数字
i = i-1; //解决方案
}
或者
采用逆循环的方式
for (var i = arr.length - 1; i >= 0; i--) {
if (arr[i] === delete_number) { //如果找到要被删除的数字所在的数组下标
var num = arr.splice(i, 1); //从i位置开始删除1个数字
console.log("成功删除 " + num); //输出被删除的数字
}
else {
console.log(arr[i] + " 未被删除"); //如果i下标的数组元素不是需要被删除的数字,就输出数字
}
}
for-of 和 for-in
自ES5正式发布后,你可以使用内建的forEach方法来遍历数组:
myArray.forEach(function (value) {
console.log(value);
});
这段代码看起来更加简洁,但这种方法也有一个小缺陷:你不能使用break语句中断循环,也不能使用return语句返回到外层函数。
for-in循环
for (var index in myArray) { // 千万别这样做
console.log(myArray[index]);
}
这绝对是一个糟糕的选择,为什么呢?
- 在这段代码中,赋给index的值不是实际的数字,而是字符串“0”、“1”、“2”,此时很可能在无意之间进行字符串算数计算,例如:“2” + 1 == “21”,这给编码过程带来极大的不便。
- 作用于数组的for-in循环体除了遍历数组元素外,还会遍历自定义属性。举个例子,如果你的数组中有一个可枚举属性
myArray.name,循环将额外执行一次,遍历到名为“name”的索引。就连数组原型链上的属性都能被访问到。 - 最让人震惊的是,在某些情况下,这段代码可能按照随机顺序遍历数组元素。
- 简而言之,for-in是为普通对象设计的,你可以遍历得到字符串类型的键,因此不适用于数组遍历。
强大的for-of循环
for (var value of myArray) {
console.log(value);
}
是的,与之前的内建方法相比,这种循环方式看起来是否有些眼熟?那好,我们将要探究一下for-of循环的外表下隐藏着哪些强大的功能。现在,只需记住:
- 这是最简洁、最直接的遍历数组元素的语法
- 这个方法避开了for-in循环的所有缺陷
- 与forEach()不同的是,它可以正确响应break、continue和return语句
for-in循环用来遍历对象属性。 for-of循环用来遍历数据 — 例如数组中的值。
for-of循环也可以遍历其它的集合
for-of循环不仅支持数组,还支持大多数类数组对象,例如DOM NodeList对象。
for-of循环也支持字符串遍历,它将字符串视为一系列的Unicode字符来进行遍历:
for (var chr of "") {
alert(chr);
}
它同样支持Map和Set对象遍历
举个例子,Set对象可以自动排除重复项:
// 基于单词数组创建一个set对象
var uniqueWords = new Set(words);
生成Set对象后,你可以轻松遍历它所包含的内容:
for (var word of uniqueWords) {
console.log(word);
}
Map对象稍有不同:内含的数据由键值对组成,所以你需要使用解构(destructuring)来将键值对拆解为两个独立的变量:
for (var [key, value] of phoneBookMap) {
console.log(key + "'s phone number is: " + value);
}
for-of就是为遍历所有这些集合特别设计的循环语句。
但是for-of循环不支持普通对象
如果你想迭代一个对象的属性,你可以用for-in循环(这也是它的本职工作)或内建的Object.keys()方法:
// 向控制台输出对象的可枚举属性
for (var key of Object.keys(someObject)) {
console.log(key + ": " + someObject[key]);
}
那么我们只想循环对应的对象该怎么做呢,这里引入hasOwnProperty()方法,hasOwnProperty()函数用于指示一个对象自身(不包括原型链)是否具有指定名称的属性。如果有,返回true,否则返回false。
var obj = {
name:"echolun",
age:"24",
sex:"male"
},
objName=[], //用来装对象属性名
objVal=[]; //用来装对象属性值
Object.prototype.game="lastgame";
for(var i in obj){
if(obj.hasOwnProperty(i)) {
objName.push(i);
objVal.push(obj[i]);
}
}
console.log(objName,objVal);
}
例如:
let arr = ["a","b"];
for (let a in arr) {
console.log(a);//0,1
}
for (let a of arr) {
console.log(a);//a,b
}
由于for of的这个特性,他还可以实现对iterator对象的遍历,而for in就是简单的遍历了。
for in是ES5标准,for of是ES6标准
Object.create相关
Object.create(proto [, propertiesObject ])
https://juejin.im/post/5c08bb18e51d451de22a4723
Object.create()方法创建一个新对象,使用现有的对象来提供新创建的对象的__proto__
propertiesObject 参数的详细解释:(默认都为false) 数据属性:
- writable:是否可任意写
- configurable:是否能够删除,是否能够被修改
- enumerable:是否能用 for in 枚举
- value:值 访问属性:
- get(): 访问
- set(): 设置
newObj = Object.create(obj, {
t1: {
value: 'yupeng',
writable: true
},
bar: {
configurable: false,
get: function() {
return bar;
},
set: function(value) {
bar = value
}
}
})
通过 Object.create() 方法,使用一个指定的原型对象和一个额外的属性对象创建一个新对象。这是一个用于对象创建、继承和重用的强大的新接口。说直白点,就是一个新的对象可以继承一个对象的属性,并且可以自行添加属性。
Object.create(null)
var o = Object.create(null,{
a:{
writable:true,
configurable:true,
value:'1'
}
})
console.log(o) // {a: "1"}
可以看到,新创建的对象除了自身属性a之外,原型链上没有任何属性,也就是没有继承Object的任何东西,此时如果我们调用o.toString()会报Uncaught TypeError的错误。
这个一定要注意
这个和{}创建的对象不一样
var o = {a:1};
console.log(o)
这里的o对象继承了Object自身的方法,如hasOwnProperty、toString等
Object.create({})
这样创建的对象和使用{}创建对象已经很相近了
但是还是有一点区别:多了一层proto嵌套。
Object.create如何做到和{…}创建对象一样
var o = Object.create(Object.prototype,{
a:{
writable:true,
configurable:true,
value:'1'
}
})
console.log(o)
这次就和使用{}创建的对象一模一样了
Object.create(null)屏蔽__proto__
当我们创建一个对象的时候,沿着原型链向上查找,总是会找到一个__proto__为Object
那么要如何做才能屏蔽掉呢?
我们使用Object.create(null)
let a = {};
let b = Object.create(null);
let c = Object();
a.xxx = 'xxx';
b.xxx = 'xxx';
c.xxx = 'xxx';
console.log(a);
console.log(b);
console.log(c);
{xxx: "xxx"} __proto__: Object
{xxx: "xxx"}
{xxx: "xxx"} __proto__: Object
使用Object.create(null)创建对象,屏蔽__proto__,可以节省一些性能
用 Object.create实现类式继承
// Shape - 父类(superclass)
function Shape() {
this.x = 0;
this.y = 0;
}
// 父类的方法
Shape.prototype.move = function(x, y) {
this.x += x;
this.y += y;
console.info('Shape moved.');
};
// Rectangle - 子类(subclass)
function Rectangle() {
Shape.call(this); // call super constructor.
}
// 子类续承父类
Rectangle.prototype = Object.create(Shape.prototype);
Rectangle.prototype.constructor = Rectangle;
// 因为使用“.prototype =...”后,constructor会改变为“=...”的那个
// constructor,所以要重新指定.constructor 为自身。
var rect = new Rectangle();
console.log('Is rect an instance of Rectangle?',
rect instanceof Rectangle); // true
console.log('Is rect an instance of Shape?',
rect instanceof Shape); // true
rect.move(1, 1); // Outputs, 'Shape moved.'
call和apply和bind
重写bind
Function.prototype.myBind = function (context, ...args) {
const self = this;
return function (...innerArgs) {
return self.apply(context, [...args, ...innerArgs]);
};
};
var obj = {
name: 'sebe',
};
var func = function (a, b, c, d) {
alert(this.name);
alert([a, b, c, d]);
}.myBind(obj, 1, 2);
func(3, 4);
想把arguments转成正的数的时候,可以借用 Array.prototype.slice 方法
Function.apply.bind
https://blog.csdn.net/weixin_37787381/article/details/81509361
关键点在于 bind可以预设参数
也是就是说bind的第二个参数null,为apply的第一个参数
apply(null,…args) 那么就意味着我们并不关心执行时其内部的this指向谁
var sum = function(x, y) {
console.log(x, y);
}
var foo = Function.apply.bind(sum, null);
foo([10, 20]); // 10, 20
这里我们有一个函数sum,通过Function.apply.bind(sum, null)我们创建了一个新的函数foo(…)。
我们一步步分析Function.apply.bind(sum, null)这段代码。
sum.apply(null, [10, 20])这句代码将第一个参数置为null,第二个参数是一个数组,用于拆开后作为sum的最终参数。
熟悉sum.apply(…)方法的朋友一定知道,如果将sum.apply(…)的第一个参数设置为null,那么就意味着我们并不关心sum在执行时其内部的this指向谁。而Function.apply.bind(sum, null)目的就是将sum.apply(…)的第一个参数固定为null。其中,Function.apply.bind(sum, null)等价于sum.apply.bind(sum, null)。
所以最终我们得到的foo函数就是sum.apply(null, [10, 20]); [10,20]会拆开成10和20传递给sum(…)。
那么我们再回到最开始的那个Promise的例子,传递给.then()的Promise决议值就是数组[10,20],.then函数的第一个参数(通常我们称之为fulfilled(…)函数)就相当于我们刚才创建的foo(…),执行foo([10, 20])输出结果就是10,20。
Function.apply.bind((x, y) => {
console.log(x, y)
}, null)
相当于
var applyCopy=Function.apply;
var foo=function(a,b){
console.log(a,b)
};
apply.bind(foo,null);
//bind指定this的指向,这里的bind指向foo函数,以函数为this调用函数,就是
foo.applyCall(null)
Function.bind.apply
我第一次见到这样的代码是在《你不知道的JS》中卷的2.4小节。讲回调的时候。针对回调的调用过早的问题,有经验的开发者们给出了这样的解决方式(当然ES6之后解决回调函数调用过早的问题还是倾向于借助Promise机制):
function asyncify(fn) {
var orig_fn = fn,
intv = setTimeout( function(){
intv = null;
if (fn) fn();
}, 0 )
;
fn = null;
return function() {
// 触发太快,在定时器intv触发指示异步转换发生之前?
if (intv) {
fn = orig_fn.bind.apply(
orig_fn,
// 将包装函数的`this`加入`bind(..)`调用的
// 参数,同时currying其他所有的传入参数
[this].concat( [].slice.call( arguments ) )
);
}
// 说明没有过早触发,这里已经是异步
else {
// 调用原来的函数
orig_fn.apply( this, arguments );
}
};
}
和前面类似,我们将orig_fn.bind.apply(orig_fn, args)拆成两部分来看:函数orig_fn.bind(…)和.apply(orig_fn, args)。根据.apply(…)的定义,orig_fn.bind.apply(orig_fn, args)其实就意味着我们将orig_fn.bind(…)函数的this指向orig_fn,然后.apply(orig_fn, args)的第二个参数会将剩下的参数传递给orig_fn.bind(…)函数。
那么我们现在分析一下剩下的参数([this].concat( [].slice.call( arguments ))都是什么吧,首先arguments是外界传入的其余参数(return function(…)这个函数传入的参数),接下来我们借助[].slice.call( arguments )将其转化为一个参数数组,备用。由于.bind(…)的第一个参数为在 origin_fn 调用中用到的 this (我们在前一段就已经提到过,这个this其实就指向orig_fn),所以使用 [this] 将构造的参数数组中的第一个参数设置为 this 。[this]再与我们前面的备用数组拼接起来,一同传递给.bind(…)。
此时,.bind(…)的第一个参数就是this,剩余参数就是外界传入的参数。所以,除了传递给orig_fn.bind(…)的第一个参数this,其余的参数都会作为柯里化参数(预设值)。
在这里的关键点是:.bind(…) 函数是通过 .apply(…) 调用的,所以 .bind(…) 自身所需要的 this 对象是一个函数(函数也是对象,在这里即 origin_fn)。
new结合bind或apply
https://github.com/bramblex/jsjs
发现:在写js解析器操作ast时发现些神奇的代码
NewExpression: (node: ESTree.NewExpression, scope: Scope) => {
const func = evaluate(node.callee, scope)
const args = node.arguments.map(arg => evaluate(arg, scope))
return new (func.bind.apply(func, [null].concat(args)))
},
bind.apply和new结合,引起了我的兴趣,所以就搜索资料进行了学习
https://www.cnblogs.com/pspgbhu/p/6796795.html
Fn.bind.apply()解决new操作符不能用与apply或call同时使用
小明想要用数组的形式为 Cls.func 传入多个参数,他想到了以下的写法:
var a = new Cls.func.apply(null, [1, 2, 3]);
然而浏览器却报错 Cls.func.apply is not a constructor。 乍一看是 new 操作符去修饰 Cls.func.apply 了,于是他又这么写:
var a = (new Cls.func).apply(null, [1, 2, 3]);
浏览器依旧报错。。。好吧,还是好好查一查相关的解决方法吧,还好这是个好时代,没有什么是网上查不出来的。
解决方案:
https://stackoverflow.com/questions/1606797/use-of-apply-with-new-operator-is-this-possible
function newCall(Fn) {
return new (Function.prototype.bind.apply(Fn, arguments));
// or even
// return new (Fn.bind.apply(Fn, arguments));
// if you know that Fn.bind has not been overwritten
}
// It can be used as follows:
var s = newCall(Fn, a, b, c);
// or even directly:
var a = new (Function.prototype.bind.call(Fn, null, 1, 2, 3));
var a = new (Function.prototype.bind.apply(Fn, [null, 1, 2, 3]));
以上关键就在于 .bind.apply() 或 .bind.call() 这中写法。
Function.prototype.bind() 等同于 Fn.bind() 会创建一个新的函数,第一个参数为新函数的 this 指向,而后多个参数为绑定函数被调用时,这些参数将置于实参之前传递给被绑定的方法。
先分析一下 Function.prototype.bind.call() 这种写法:
var a = new (Function.prototype.bind.call(Fn, null, 1, 2, 3)); call() 接受多个参数,第一个参数为函数执行的上下文环境,后面的参数会依次传递给前面的 bind 作为参数。
所以 bind() 接到的参数为 bind(null, 1, 2, 3)。所以上面的那种写法就等同于:
var a = new ( Fn.bind(null, 1, 2, 3)() );
同理再推导 Function.prototype.bind.apply() 写法:
var a = new (Function.prototype.bind.apply(Fn, [null, 1, 2, 3]);
call() 接受两个参数,第一个参数为函数执行的上下文环境,第二个参数为数组,数组的每一项会一次作为 bind() 的参数,因此 bind() 接受到的参数也为 bind(null, 1, 2, 3)。因此也等价于:
var a = new ( Fn.bind(null, 1, 2, 3)() );
有了上面的推导,我们可以抽象出一个通用方法
function newApply(Fn, argsAry) {
argsAry.unshift(null);
return new (Fn.bind.apply(Fn, argsAry));
}
// 调用
newApply(Cls.func, [1, 2, 3]) // well done !!
call和apply参数为null/undefined
call和apply的第一个参数是null/undefined时函数内的的this指向window或global
||和&&的高级用法
用于赋值
- &&:从左往右依次判断,当当前值为true则继续,为false则返回此值。是返回未转换为布尔值时的原值
-
:从左往右依次判断,当当前值为false则继续,为true则返回此值。是返回未转换为布尔值时的原值
// => aaa
var attr = true && 4 && "aaa";
// => 0
var attr = true && 0 && "aaa";
// => 100
var attr = 100 || 12;
// => e
var attr = "e" || "hahaha"
// => hahaha
var attr = "" || "hahaha"
经过多次判断的赋值
/*
x>=15时 => 4
x>=12时 => 3
x>=10时 => 2
x>=5时 => 1
x<5时 => 0
*/
console.log((x>=15 && 4) || (x>=12 && 3) || (x>=10 && 2) || (x>=5 && 1) || 0);
与对象形式的变量合体
/*
x=15 时 => 4
x=12 时 => 3
x=10 时 => 2
x=5 时 => 1
其它 => 0
*/
console.log( {'5':1,'10':2,'12':3,'15':4}[x] || 0 );
用于执行语句
if(a >=5){alert("你好");}
//可以写成:
a >= 5 && alert("你好");
&&、||同时存在的思考
true || alert(2) && false
// 结果为true,alert(2)并没有执行
false && false || alert(1)
// 结果弹窗1,执行了alert(1)
如果按从左往右的顺序执行,短路运算生效,应该不会执行alert(1)
究竟是怎么回事?
| **遇到 | 运算符,先去左边的表达式得出结果,如果结果为true,则不会去执行右边的表达式,则短路运算生效;如果结果为false,则去执行右边的表达式,再去根据两边的结果去执行 | 运算符** |
| **当同时存在多个 | 时,从左到右,一一执行上述规则。** |
Array.reduce
按顺序运行 Promise
* @param {array} arr - promise arr 非Promise也可以Promise.resolve转化一下
* @return {Object} promise object
*/
function runPromiseInSequence(arr, input) {
return arr.reduce(
(promiseChain, currentFunction) => promiseChain.then(currentFunction),
Promise.resolve(input)
)
}
数组切割
function chunk(arr = [], size = 1) {
return arr.reduce(
(t, v) => {
t[t.length - 1].length === size ? t.push([v]) : t[t.length - 1].push(v);
return t
},
[[]]
);
}
const res = chunk(["a", "b", "c", "d", "e", "f", "g"], 3);
// [['a','b','c'],['d','e','f'],['g']]
元素的尺寸
Determining the dimensions of elements
clientWidth 和 getBoundingClientRect().width
getBoundingClientRect().width获取到的其实是父级的右边距离浏览器原点(0,0)减去左边距离浏览器原点(0,0)的距离, 即宽度+2padding+2border
clientWidth等于宽度+2padding,不包括边框的宽度
offsetWidth和offsetHeight
If you need to know the total amount of space an element occupies, including the width of the visible content, scrollbars (if any), padding, and border
一般情况 getBoundingClientRect等于对应offset属性
例如: getBoundingClientRect().width === offsetWidth
但是
In case of transforms, the offsetWidth and offsetHeight returns the element’s layout width and height, while getBoundingClientRect() returns the rendering width and height.
屏蔽属性
一条赋值语句引出的思考:
myObject.foo = "bar";
如果myObject 对象中包含名为foo 的普通数据访问属性,这条赋值语句只会修改已有的属性值。
如果foo 不是直接存在于myObject 中,[[Prototype]] 链就会被遍历,类似[[Get]] 操作。如果原型链上找不到foo,foo 就会被直接添加到myObject 上。然而,如果foo 存在于原型链上层,赋值语句myObject.foo = “bar” 的行为就会有些不同
如果属性名foo 既出现在myObject 中也出现在myObject 的[[Prototype]] 链上层, 那么就会发生屏蔽。
myObject 中包含的foo 属性会屏蔽原型链上层的所有foo 属性,因为myObject.foo 总是会选择原型链中最底层的foo 属性。
下面我们分析一下如果foo 不直接存在于myObject 中而是存在于原型链上层时myObject.foo = “bar” 会出现的三种情况。
- 如果在[[Prototype]] 链上层存在名为foo 的普通数据访问属性并且没有被标记为只读(writable:false),那就会直接在myObject 中添加一个名为foo 的新属性,它是屏蔽属性。
- 如果在[[Prototype]] 链上层存在foo,但是它被标记为只读(writable:false),那么无法修改已有属性或者在myObject 上创建屏蔽属性。如果运行在严格模式下,代码会抛出一个错误。否则,这条赋值语句会被忽略。总之,不会发生屏蔽。
- 如果在[[Prototype]] 链上层存在foo 并且它是一个setter(参见第3 章),那就一定会调用这个setter。foo 不会被添加到(或者说屏蔽于)myObject,也不会重新定义foo 这个setter。
http://www.cnblogs.com/ziyunfei/archive/2012/10/31/2738728.html
globalThis
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/globalThis
全局属性 globalThis 包含全局的 this 值,类似于全局对象(global object)。
跨环境统一性
- 浏览器:
globalThis指向window对象 - Node.js:指向
global对象 - Web Workers:指向
self对象 - 其他环境:如 Deno、物联网设备等,均通过
globalThis提供一致的全局对象访问方式
Object的keys的顺序
const objWithStrings = {
"002": "002",
c: "c",
2: "1",
b: "b",
1: "1",
[Symbol("second")]: "second",
"001": "001",
};
console.log(Reflect.ownKeys(objWithStrings));
console.log(Object.keys(objWithStrings));
console.log(Object.getOwnPropertyNames(objWithStrings));
输出:
['1', '2', '002', 'c', 'b', '001', Symbol(second)]
['1', '2', '002', 'c', 'b', '001']
['1', '2', '002', 'c', 'b', '001']
总结:
- 在 ES6 之前 Object 的键值对是无序的;
- 在 ES6 之后 Object 的键值对按照自然数、非自然数和 Symbol 进行排序,自然数是按照大小升序进行排序,其他两种都是按照插入的时间顺序进行排序。
AbortController
https://developer.mozilla.org/zh-CN/docs/Web/API/AbortController
AbortController 接口表示一个控制器对象,允许你根据需要中止一个或多个 Web 请求。
controller = new AbortController();
const signal = controller.signal;
fetch(url, { signal })
.then((response) => {
console.log("Download complete", response);
})
.catch((err) => {
console.error(`Download error: ${err.message}`);
});
// 在 fetch 的过程中
controller.abort(); // 中断请求
MessageChannel
https://developer.mozilla.org/zh-CN/docs/Web/API/MessageChannel
Channel Messaging API 的 MessageChannel 接口允许我们创建一个新的消息通道,并通过它的两个 MessagePort 属性发送数据。
MessageChannel是以DOM Event的形式发送消息,所以它是一个宏任务,会在下一个事件循环的开头执行。
MessageChannel回调的执行时机会比setTimeout早
浏览器的宏任务队列其实是一个有序集合,这意味着队列里到期的事件不一定会按入队的顺序执行,因为DOM Event的优先级比计时器高,所以会出现上面的打印结果。
requestAnimationFrame
requestAnimationFrame打印时机不稳定,因为不是每次事件循环都会触发重渲染,浏览器可能将多次渲染合成一次;
PointerEvent
用于web白板中,可适用多个设备,如ipad的触控笔
https://developer.mozilla.org/zh-CN/docs/Web/API/Pointer_events
目前绝大多数的 Web 内容都假设用户的指针定点设备为鼠标。然而,近年来的新兴设备支持更多不同方式的指针定点输入,如各类触控笔和触摸屏幕等。这就有必要扩展现存的定点设备事件模型,以有效追踪各类指针事件。
我们可以简单地将 Pointer Events 理解成是 Mouse Event 和 Touch Event 的结合。
key
- object的key只能是 string/Symbol (number类型会隐式转换成string)
- map的key可以是任何js类型
补充
toFixed和fixed
toFixed() 方法可把 Number 四舍五入为指定小数位数的数字。
语法
NumberObject.toFixed(num)
num 必需。规定小数的位数,是 0 ~ 20 之间的值,包括 0 和 20,有些实现可以支持更大的数值范围。如果省略了该参数,将用 0 代替。
Show the number 13.37 with one decimal:
<script type="text/javascript">
var num = new Number(13.37);
document.write (num.toFixed(1))
</script>
输出:
Show the number 13.37 with one decimal:
13.4
fixed() 方法用于把字符串显示为打字机字体。 stringObject.fixed()
JS中的“use strict” 严格模式
ECMAScript 5 引入严格模式(‘strict mode’)概念。通过严格模式,在函数内部选择进行较为严格的全局或局部的错误条件检测,使用严格模式的好处是可以提早知道代码中的存在的错误,
及时捕获一些可能导致编程错误的ECMAScript行为,在开发中使用严格模式能帮助我们早发现错误。
严格模式影响范围
- 变量: var、delete、变量关键字
- 对象: 只读属性、 对象字面量属性重复申明
- 函数:参数重名、arguments对象、申明
- 其他:this、eval、关键字…
设立”严格模式”的目的,主要有以下几个:错误检测、规范、效率、安全、面向未来
- 消除Javascript语法的一些不合理、不严谨之处,减少一些怪异行为;
- 消除代码运行的一些不安全之处,保证代码运行的安全;
- 提高编译器效率,增加运行速度;
- 为未来新版本的Javascript做好铺垫。
进入”严格模式”的编译指示(pragma),是下面这行语句:
"use strict";
将”use strict”放在脚本文件的第一行,则整个脚本都将以”严格模式”运行。
如果这行语句不在第一行,则无效,整个脚本以”正常模式”运行。
如果不同模式的代码文件合并成一个文件,这一点需要特别注意。
Object.is()
https://juejin.im/post/5d560c0cf265da03c61e4d33
Object.is(),其行为与===基本一致
不过有两处不同:
- +0不等于-0。
- NaN等于自身。
+0 === -0 //true
NaN === NaN // false
Object.is(+0, -0) // false
Object.is(NaN, NaN) // true
includes startsWith endsWith padStart padEnd
ES6 引入了字符串补全长度的功能,如果某个字符串不够指定长度,会在头部活尾部补全。
- includes() 返回布尔值,表示是否找到了参数字符串
- startsWith() : 返回布尔值,表示参数字符串是否在原字符串的头部
-
endsWith() : 返回布尔值,表示参数字符串是否在原字符串的头部
- padStart() 用于头部补全;
- padEnd() 用于尾部补全。
// 第一个参数表示最终生成字符串的长度
'x'.padStart(5, 'ab') // 'ababx'
'x'.padStart(4, 'ab') // 'abax'
'x'.padEnd(5, 'ab') // 'xabab'
'x'.padEnd(4, 'ab') // 'xaba'
eval() 函数
定义和用法
eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
语法
eval(string) string 必需。要计算的字符串,其中含有要计算的 JavaScript 表达式或要执行的语句。
返回值 通过计算 string 得到的值(如果有的话)。
说明
该方法只接受原始字符串作为参数,如果 string 参数不是原始字符串,那么该方法将不作任何改变地返回。因此请不要为 eval() 函数传递 String 对象来作为参数。
如果试图覆盖 eval 属性或把eval()方法赋予另一个属性,并通过该属性调用它,则 ECMAScript 实现允许抛出一个 EvalError 异常。
提示和注释
虽然 eval() 的功能非常强大,但在实际使用中用到它的情况并不多。
实例
<script type="text/javascript">
eval("x=10;y=20;document.write(x*y)")
document.write(eval("2+2"))
var x=10
document.write(eval(x+17))
</script>
输出:
200
4
27
eval("2+3") // 返回 5
var myeval = eval; // 可能会抛出 EvalError 异常
myeval("2+3"); // 可能会抛出 EvalError 异常
可以使用下面这段代码来检测 eval() 的参数是否合法:
try {
alert("Result:" + eval(prompt("Enter an expression:","")));
}
catch(exception) {
alert(exception);
}
js中这个函数eval()对json数据有什么用?那eval( ‘(‘ + content + ‘)’ )里边为什么要加引号呢?
对于服务器返回的JSON字符串,如果jquery异步请求没做类型说明,或者以字符串方式接受,那么需要做一次对象化处理,方式不是太麻烦,就是将该字符串放于eval()中执行一次。这种方式也适合以普通javascipt方式获取json对象,以下举例说明:
var dataObj=eval(“(“+data+”)”);//转换为json对象 为什么要 eval这里要添加 “(“(“+data+”)”);//”呢?
原因在于:eval本身的问题。 由于json是以”{}”的方式来开始以及结束的,在JS中,它会被当成一个语句块来处理,所以必须强制性的将它转换成一种表达式。
加上圆括号的目的是迫使eval函数在处理JavaScript代码的时候强制将括号内的表达式(expression)转化为对象,而不是作为语 句(statement)来执行。
举一个例子,例如对象字面量{},如若不加外层的括号,那么eval会将大括号识别为JavaScript代码块的开始 和结束标记,那么{}将会被认为是执行了一句空语句。所以下面两个执行结果是不同的:
alert(eval("{}"); // return undefined
alert(eval("({})");// return object[Object]
变量提升
在ES6之前,JavaScript没有块级作用域(一对花括号{}即为一个块级作用域),只有全局作用域和函数作用域。变量提升即将变量声明提升到它所在作用域的最开始的部分。上个的例子如:
console.log(global); // undefined
var global = 'global';
console.log(global); // global
function fn () {
console.log(a); // undefined
var a = 'aaa';
console.log(a); // aaa
}
fn();
之所以会是以上的打印结果,是由于js的变量提升,实际上上面的代码是按照以下来执行的:
var global; // 变量提升,全局作用域范围内,此时只是声明,并没有赋值
console.log(global); // undefined
global = 'global'; // 此时才赋值
console.log(global); // 打印出global
function fn () {
var a; // 变量提升,函数作用域范围内
console.log(a);
a = 'aaa';
console.log(a);
}
fn();
函数提升
js中创建函数有两种方式:函数声明式和函数字面量式。只有函数声明才存在函数提升! 如:
console.log(f1); // function f1() {}
console.log(f2); // undefined
function f1() {}
var f2 = function() {}
只所以会有以上的打印结果,是由于js中的函数提升导致代码实际上是按照以下来执行的:
function f1() {} // 函数提升,整个代码块提升到文件的最开始
console.log(f1);
console.log(f2);
var f2 = function() {}
函数作用域跟块级作用域
- 函数作用域:变量在定义的函数内及嵌套的子函数内处处可见
- 块级函数域:变量在离开定义的块级代码后马上被回收。
那么为什么两者会有这样的区别呢? 因为在函数作用域内,变量声明有一个提升hoisting的过程。
(function () {
console.log(b)
console.log(c)
var b =3
let c = 3
})();
let定义的变量具有块级作用域,待会讲。
如果var定义的变量跟let定义的变量一样没有hoisting的过
程,那么两者应该都是ReferenceError,但是结果发现b是undefined,说明b发生了提升
那如果在提升的时候发生重命名了怎么办?
(function () {
function a() {
}
console.log(a)
var a = 12
console.log(a);
var a = 'aaa'
console.log(a)
})();
是这样吗?
(function () {
function a() {
}
var a;
var a;
console.log(a)
a = 12
console.log(a);
a = 'aaa'
console.log(a)
})();
那么之后的var a为什么没有覆盖掉function a(){}这个定义,使第一个打印为undefined?
因为编译器在遇到变量声明时(函数表达式可以理解为包含了声明和赋值的操作),会先查看当前作用域,如果该变量不存在,则在该作用域中声明该变量;如果存在,则会忽略该声明。
所以,正确代码:
(function () {
function a() {
}
console.log(a)
a = 12
console.log(a)
a = 'aaa'
console.log(a)
})();
注意不要把a跟隐式全局变量混淆。
立即执行函数不存在提升的情况
var x = 21;
var girl = function () {
console.log(x);
var x = 20;
};
girl ();
输出: undefined
函数内部变量提升。 相当于
var x = 21;
var girl = function() {
var x;
console.log(x); // undefined
x = 20;
}
块级作用域
let关键字
let定义的变量遵从块级作用域,不会提升,不会在整个函数域内起作用。
const关键字
const定义的变量是在let的基础上,增加了必须在声明时赋值为一个常量的限制
块中定义的函数声明
直接在函数体内定义的函数声明,整个都会提前;
但是在块中定义的函数声明,只会提升其声明部分,不分配实际的内存空间
(function () {
console.log(a)
console.log(b)
{
function a() {
alert("haha")
}
}
function b() {
}
})();
输出结果
undefined
ƒ b() {
}
Url 编码
一般来说,URL只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。比如,世界上有英文字母的网址 “http://www.haorooms.com”, 但是没有希腊字母的网址“http://www.aβγ.com”
“只有字母和数字[0-9a-zA-Z]、一些特殊符号“$-_.+!*’(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL。”
这意味着,如果URL中有汉字,就必须编码后使用。但是麻烦的是,RFC 1738没有规定具体的编码方法,而是交给应用程序(浏览器)自己决定。这导致“URL编码”成为了一个混乱的领域。
JavaScript中有三个可以对字符串编码的函数,分别是: escape,encodeURI,encodeURIComponent,相应3个解码函数:unescape,decodeURI,decodeURIComponent 。
escape已废弃,不建议使用
“; / ? : @ & = + $ , #”,这些在encodeURI()中不被编码的符号,在encodeURIComponent()中统统会被编码。
encodeURI()函数
定义和用法 encodeURI() 函数可把字符串作为 URI 进行编码。
语法 encodeURI(URIstring)
参数 描述 URIstring 必需。一个字符串,含有 URI 或其他要编码的文本。
返回值 URIstring 的副本,其中的某些字符将被十六进制的转义序列进行替换。
说明 该方法不会对 ASCII 字母和数字进行编码,也不会对这些 ASCII 标点符号进行编码: - _ . ! ~ * ‘ ( ) 。
该方法的目的是对 URI 进行完整的编码,因此对以下在 URI 中具有特殊含义的 ASCII 标点符号,encodeURI() 函数是不会进行转义的:;/?:@&=+$,#
encodeURIComponent() 函数
定义和用法 encodeURIComponent() 函数可把字符串作为 URI 组件进行编码。
语法 encodeURIComponent(URIstring)
参数 描述 URIstring 必需。一个字符串,含有 URI 组件或其他要编码的文本。
返回值 URIstring 的副本,其中的某些字符将被十六进制的转义序列进行替换。
说明 该方法不会对 ASCII 字母和数字进行编码,也不会对这些 ASCII 标点符号进行编码: - _ . ! ~ * ‘ ( ) 。
其他字符(比如 :;/?:@&=+$,# 这些用于分隔 URI 组件的标点符号),都是由一个或多个十六进制的转义序列替换的。
提示和注释 提示:请注意 encodeURIComponent() 函数 与 encodeURI() 函数的区别之处,前者假定它的参数是 URI 的一部分(比如协议、主机名、路径或查询字符串)。因此 encodeURIComponent() 函数将转义用于分隔 URI 各个部分的标点符号。
词法作用域
词法作用域中是在函数内变量作用域是再定义处(即代码书写处)的作用域
这是个非常重要的知识点
看下面一个例子
var bo = 10;
function foo() {
// console.log(this) 此处this一直指向window 所以this.bo一直是10
console.log(bo);
}
(function() {
var bo = 20;
foo();
})();
(function (func) {
var bo = 30;
func();
})(foo)
输出结果 10 10
无论函数在哪里被调用,也无论它如何被调用,它的词法作用域都只由函数被声明时所处的位置决定
JS闭包
当function里嵌套function时,内部的function可以访问外部function里的变量。
闭包是可访问上一层函数作用域里变量的函数,即便上一层函数已经关闭。
闭包就是一个函数引用另一个函数的变量,因为变量被引用着所以不会被回收,因此可以用来封装一个私有变量。这是优点也是缺点,不必要的闭包只会增加内存消耗。 或者说闭包就是子函数可以使用父函数的局部变量,还有父函数的参数。
function foo(x) {
var tmp = 3;
function bar(y) {
alert(x + y + (++tmp));
}
bar(10);
}
foo(2)
不管执行多少次,都会alert16,因为bar能访问foo的参数x,也能访问foo的变量tmp。但,这还不是闭包。当你return的是内部function时,就是一个闭包。内部function会close-over外部function的变量直到内部function结束。
function foo(x) {
var tmp = 3;
return function (y) {
alert(x + y + (++tmp));
}
}
var bar = foo(2); // bar 现在是一个闭包
bar(10);
上面的脚本最终也会alert16,因为虽然bar不直接处于foo的内部作用域,但bar还是能访问x和tmp。 但是,由于tmp仍存在于bar闭包的内部,所以它还是会自加1,而且你每次调用bar时它都会自加1.
如果在一个大函数中有一些代码能够独立出来, 我们常常把这些代码封装在独立的的小函数里面。独立出来的小函数有助于代码复用,如果这些小函数有一个良好的命名,它们本身也起到了注释的作用。如果这些小函数不需要在程序的其他地方使用,最好是它们用闭包封装起来
var mult = (function () {
var cache = {}
var calculate = function () {
//封闭calculate函数
var a = 1
for (var i = 0, l = arguments.length; i < l; i++) {
a = a * arguments[i]
}
return a
}
return function () {
var args = Array.prototype.join.call(arguments, ',')
if (args in cache) {
return cache[args]
}
return cache[args] = calculate.apply(null, arguments)
}
})()
Range
https://developer.mozilla.org/zh-CN/docs/Web/API/Range
Range 接口表示一个包含节点与文本节点的一部分的文档片段。
可以用 Document 对象的 Document.createRange 方法创建 Range,也可以用 Selection 对象的 getRangeAt 方法获取 Range。另外,还可以通过 Document 对象的构造函数 Range() 来得到 Range。
关于 setStart 和 setEnd
https://stackoverflow.com/questions/27435485/dom-range-setstart-setend
我们来看一个例子:
<div id="test">
<p>h</p>ello
</div>
// 实现加粗hel 这三个字母
var range = document.createRange();
var root_node = document.getElementById("test");
// Start at the `<p>` element.
range.setStart(root_node, 1);
// End in the `ello` text node, between the two `l`s.
range.setEnd(root_node.childNodes[2], 2);
var newNode = document.createElement("b");
range.surroundContents(newNode);
这个方法与
newNode.appendChild(range.extractContents()); range.insertNode(newNode)等价。应用以后,newNode包含在range的边界点中。
BOM和DOM详解
DOM:
DOM 全称是 Document Object Model,也就是文档对象模型。
DOM 就是针对 HTML 和 XML 提供的一个API。什么意思?就是说为了能以编程的方法操作这个 HTML 的内容(比如添加某些元素、修改元素的内容、删除某些元素),我们把这个 HTML 看做一个对象树(DOM树),它本身和里面的所有东西比如 <div></div> 这些标签都看做一个对象,每个对象都叫做一个节点(node),节点可以理解为 DOM 中所有 Object 的父类。
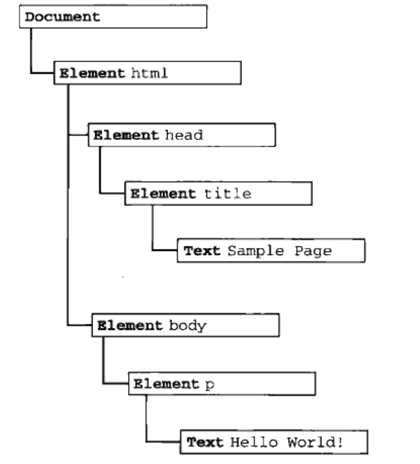
DOM 有什么用?就是为了操作 HTML 中的元素,比如说我们要通过 JS 把这个网页的标题改了,直接这样就可以了:
document.title = 'how to make love';
这个 API 使得在网页被下载到浏览器之后改变网页的内容成为可能。
document
当浏览器下载到一个网页,通常是 HTML,这个 HTML 就叫 document(当然,这也是 DOM 树中的一个 node),从上图可以看到,document 通常是整个 DOM 树的根节点。这个 document包含了标题(document.title)、URL(document.URL)等属性,可以直接在 JS 中访问到。在一个浏览器窗口中可能有多个 document,例如,通过 iframe 加载的页面,每一个都是一个 document。在 JS 中,可以通过 document 访问其子节点(其实任何节点都可以),如
document.body;
document.getElementById('xxx');
BOM
BOM 是 Browser Object Model,浏览器对象模型。
刚才说过 DOM 是为了操作文档出现的接口,那 BOM 顾名思义其实就是为了控制浏览器的行为而出现的接口。
浏览器可以做什么呢?比如跳转到另一个页面、前进、后退等等,程序还可能需要获取屏幕的大小之类的参数。
所以 BOM 就是为了解决这些事情出现的接口。比如我们要让浏览器跳转到另一个页面,只需要
location.href = "http://www.xxxx.com";
这个 location 就是 BOM 里的一个对象。
object类型里的键值
var obj = {"name1":"张三","name2":"李四"};
var key = "name1";
var value = obj.key;//得到了"undefined"
value = obj.name1;//得到了"张三"
其实我是想动态给key赋值,然后得到key为多少所对就的值。但这种做法行不通,obj.key会去找obj下key为”key”所对应的值,结果当然是找不到喽。 于是,我想到了js中遍历对象属性的方法:
function printObject(obj){
//obj = {"cid":"C0","ctext":"区县"};
var temp = "";
for(var i in obj){//用javascript的for/in循环遍历对象的属性
temp += i+":"+obj[i]+"\n";
}
alert(temp);//结果:cid:C0 \n ctext:区县
}
怎么动态给key赋值,然后以obj.key的方式得到对应的value呢
其实以上printObject中有提示,那就是用obj[key]的方法,key可以是动态的,这样就解决了我上面提出的问题了。 最后说一下,还有一个方法也可以,那就是:eval(“obj.”+key)。
总结
js中想根据动态key得到某对象中相对应的value的方法有两个
- var key = “name1”;var value = obj[key];
- var key = “name1”;var value = eval(“obj.”+key);
var obj={"name":"tom","age":22,"job":"it"};
var keys="name";
console.log(obj[keys]); //tom
console.log(eval("obj."+keys)); //tom
toUTCString和toGMTString区别
定义和用法
toGMTString() 方法可根据格林威治时间 (GMT) 把 Date 对象转换为字符串,并返回结果。
语法 dateObject.toGMTString()
返回值 dateObject 的字符串表示。此日期会在转换为字符串之前由本地时区转换为 GMT 时区。
不赞成使用此方法。请使用 toUTCString() 取而代之!!
目前UTC已经取代GMT作为新的世界时间标准
console.log(new Date().toDateString()) //Tue Apr 17 2018
console.log(new Date().toGMTString()) //Tue, 17 Apr 2018 14:37:22 GMT
console.log(new Date().toUTCString()) //Tue, 17 Apr 2018 14:37:22 GMT
target,currentTarget和this
target在事件流的目标阶段;currentTarget在事件流的捕获,目标及冒泡阶段
只有当事件流处在目标阶段的时候,两个的指向才是一样的, 而当处于捕获和冒泡阶段的时候,target指向被单击的对象而currentTarget指向当前事件活动的对象(注册该事件的对象)(一般为父级)。
this指向永远和currentTarget指向一致(只考虑this的普通函数调用)。
<div id="outer" style="background:#099">
click outer
<p id="inner" style="background:#9C0">click inner</p>
<br>
</div>
<script type="text/javascript">
function G(id){
return document.getElementById(id);
}
function addEvent(obj, ev, handler){
if(window.attachEvent){
obj.attachEvent("on" + ev, handler);
}else if(window.addEventListener){
obj.addEventListener(ev, handler, false);
}
}
function test(e){
alert("e.target.tagName : " + e.target.tagName + "\n e.currentTarget.tagName : " + e.currentTarget.tagName);
}
var outer = G("outer");
var inner = G("inner");
//addEvent(inner, "click", test);
addEvent(outer, "click", test);
</script>
当点击inner对象的时候,先触发inner绑定的事件,再触发outer绑定的事件,(因为outer是在事件冒泡阶段绑定的,如果outer是在捕获阶段绑定的,就会先触发out的事件程序,即便inner事件也绑定在捕获阶段。因为捕获流从根部元素开始)。
事件流:捕获(自顶而下)——目标阶段——冒泡(自下而顶)
在事件处理程序内部,对象this始终等于currentTarget的值(换个角度理解,DOM上的方法this指向都为该DOM-方法调用模式),而target则只包含事件的实际目标。如果直接将事件处理程序指定给了目标元素,则this、currentTarget和target包含相同的值。
补充
HTML DOM addEventListener() 方法
第三个参数:useCapture 可选。布尔值,指定事件是否在捕获或冒泡阶段执行。
可能值:
- true - 事件句柄在捕获阶段执行
- false- false- 默认。事件句柄在冒泡阶段执行
监听滚动条事件
在Jquery中: $(window).scrollTop() 方法返回或设置匹配元素的滚动条的垂直位置。
也就是scroll top offset 指的是滚动条相对于其顶部的偏移。
如果该方法未设置参数,则返回以像素计的相对滚动条顶部的偏移。
// 返回值为纯数字 不带px
语法
$(selector).scrollTop(offset)
| 参数 | 描述 |
|---|---|
| offset | 可选。规定相对滚动条顶部的偏移,以像素计。 |
被所有浏览器支持.
小案例
dom元素随着滚动条滚动而滚动
也就是说相对窗体,这个dom元素不移动
jQuery(document).ready(function ($) {
var f = parseInt($(".spig").css("top"));
$(window).scroll(function () {
$(".spig").animate({
top: $(window).scrollTop() + f
},
{
queue: false,
duration: 1000
});
});
});
监听window的滑动事件,当window滑动时,改变dom元素的位置
JSON.parse()和JSON.stringify()
parse用于从一个字符串中解析出json对象,如
var str = ‘{“name”:”huangxiaojian”,”age”:”23”}’ 结果: JSON.parse(str)
Object age: “23” name: “huangxiaojian” __proto__: Object
注意:单引号写在{}外,每个属性名都必须用双引号,否则会抛出异常。
stringify()用于从一个对象解析出字符串,如
var a = {a:1,b:2} 结果: JSON.stringify(a)
”{“a”:1,”b”:2}”
将js中的字符串转化成json对象常见的3种方法
var str = ‘{“name”:”小明”,”age”:18}’; 将字符串转化json对象:
- var json = JSON.parse(str);
- var json = eval(“(“ + str + “)”);
- var json = (new Function(“return “ + str))();
坑点
1.字符串的数据格式 以上举例 str = ‘{“name”:”小明”,”age”:18}’; 属性name和age都用双引号引住, 有的人可能会习惯写成对象形式的字符串,如:str = ‘{name:”小明”,age:18}’; 结果使用JSON.parse()来转化会报错,因为使用JSON.parse需严格遵守JSON规范。
2.单引号与双引号 我们看到一开始的举例中 var str = ‘{“name”:”小明”,”age”:18}’; 使用单引号来套双引号,如果反过来写呢,如:var str = “{‘name’:’小明’, ‘age’:18}”;(相信也不少人习惯用双引号套单引号) 结果使用JSON.parse()来转化也会报错
如果使用eval()或者new Function()的方式来转化,那就完全可以忽略上述的这两点需要注意的地方
连等号中的一个注意点
function runMe(){
var c = d = e = f = a =2;
console.log('在函数里面的c=' + c);
console.log('在函数里面的d=' + d);
}
var c = 123,
a = 321;
console.log('这里是函数执行前的c', typeof(c), c);
console.log('这里是函数执行前的a', typeof(a), a);
runMe();
console.log('这里是函数执行后的c', typeof(c), c);
console.log('这里是函数执行后的a', typeof(a), a);
console.log(typeof(d), d === window.d, '在函数外面的d=' + d, e, f );
这里是函数执行前的c number 123
这里是函数执行前的a number 321
在函数里面的c=2
在函数里面的d=2
这里是函数执行后的c number 123
这里是函数执行后的a number 2
number true 在函数外面的d=2 2 2
把var换成let情况一样
在使用 = 进行赋值操作时,如果是在全局作用域下,当然不用说所有的变量都为全局的;
但是如果是在函数里面赋值,在var后面的第一个变量会是局部变量, = 后面的所有其它变量都升级为了全局变量;
这是一个小坑,使用时需多多注意,避免修改了全局变量的值。
如果你非要这样赋值,但是又不想变为全局变量你可以这样。
function runMe(){
var c,
d,
e,
f,
a;
c = d = e = f = a =2;
console.log('在函数里面的c=' + c);
console.log('在函数里面的d=' + d);
}
作者:Xiaodongsu 链接:https://www.jianshu.com/p/34baea9051a2 来源:简书 简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
获取函数的参数个数
https://blog.csdn.net/ycdyx/article/details/80501550
function webyang(a, b) {
console.log(webyang.length);
console.log(arguments.length);
}
webyang(1, 2, 3);
//2 为定义的参数个数
//3 为实际传入的参数个数
JS匿名函数理解
匿名函数的基本形式为(function(){…})();
前面的括号包含函数体,后面的括号就是给匿名函数传递参数并立即执行之
匿名函数的作用是避免全局变量的污染以及函数名的冲突
方式1,调用函数,得到返回值。强制运算符使函数调用执行
(function(x,y){
alert(x+y);
return x+y;
}(3,4));
方式2,调用函数,得到返回值。强制函数直接量执行再返回一个引用,引用再去调用执行
(function(x,y){
alert(x+y);
return x+y;
})(3,4);
这种方式也是很多库爱用的调用方式,如jQuery,Mootools。
方式3,使用void
void function(x) {
x = x-1;
alert(x);
}(9);
JSON.parse深拷贝的弊端
JSON.parse(JSON.stringify(obj))我们一般用来深拷贝,其过程说白了 就是利用JSON.stringify 将js对象序列化(JSON字符串),再使用JSON.parse来反序列化(还原)js对象
javaScript存储对象都是存地址的,所以浅拷贝会导致 obj1 和obj2 指向同一块内存地址。改变了其中一方的内容,都是在原来的内存上做修改会导致拷贝对象和源对象都发生改变,而深拷贝是开辟一块新的内存地址,将原对象的各个属性逐个复制进去。对拷贝对象和源对象各自的操作互不影响。
我们在使用 JSON.parse(JSON.stringify(xxx))时应该注意一下几点:
如果obj里面有时间对象,则JSON.stringify后再JSON.parse的结果,时间将只是字符串的形式。而不是时间对象;
var test = {
name: 'a',
date: [new Date(1536627600000), new Date(1540047600000)],
};
let b;
b = JSON.parse(JSON.stringify(test))
// date: ["2018-09-11T01:00:00.000Z", "2018-10-20T15:00:00.000Z"]
如果obj里有RegExp、Error对象,则序列化的结果将只得到空对象;
const test = {
name: 'a',
date: new RegExp('\\w+'),
};
const copyed = JSON.parse(JSON.stringify(test));
console.log(copyed)
// {name: "a", date: {}}
如果obj里有函数,undefined,则序列化的结果会把函数或 undefined丢失;
const test = {
name: 'a',
date: function hehe() {
console.log('fff')
},
};
const copyed = JSON.parse(JSON.stringify(test));
console.log(copyed)
//{name: "a"}
如果obj里有NaN、Infinity和-Infinity,则序列化的结果会变成null
JSON.stringify()只能序列化对象的可枚举的自有属性,例如 如果obj中的对象是有构造函数生成的, 则使用JSON.parse(JSON.stringify(obj))深拷贝后,会丢弃对象的constructor;
在函数上添加函数属性
我们在看axios的源码的时候,发现
axios({
method: 'post',
url: '/user/12345',
data: {
firstName: 'Fred',
lastName: 'Flintstone'
}
});
axios.create({
baseURL: 'https://some-domain.com/api/',
timeout: 1000,
headers: {'X-Custom-Header': 'foobar'}
});
asxios本身是一个函数,在他上面又添加了函数属性
相当于
let aaa = function () {
console.log("aaa")
}
aaa.bbb = function () {
console.log("bbb")
}
aaa.ccc = function () {
console.log("ccc")
}
那如果我们要沿着原型链查找,怎么样才能找到bbb
答案是
aaa.prototype.constructor.bbb
console.log(aaa.prototype.constructor.bbb === aaa.bbb) // true
分号的重要性
let a = 1 + 2
[1, 2].forEach(item => {
console.log("item", item)
})
上面的代码会报错
Uncaught TypeError: Cannot read property 'forEach' of undefined
在 js 的语法中,如果语句独占一行,通常可以省略句末的分号
但实际上 js 解析代码的时候,只有在句末缺少分号就无法正常运行的时候,才会自动填补分号
如果前后的语句能够组成一个语法正确的语句,则不会自动填补分号
上面的函数中,js 实际处理的代码为:
let a = 1 + 2[1, 2].forEach(item => {
console.log("item", item)
})
解决方案:
let a = 1 + 2
;[1, 2].forEach(item => {
console.log("item", item)
})
++和–
++或–优先作为前缀操作
但如果语句以 “++” 或者 “–” 开始的时候,会优先作为前缀操作符进行解析
function test(x, y) {
x
++
y
}
如图的语句会被解析为 x; ++y 而不是 x++; y
++或–语句返回的结果
- 前置运算符语句返回执行后的结果
- 后置运算符语句返回本来的结果
举个例子:
let index = -1
let r = index++
console.log(r) // -1
let index = -1;
let l = ++index;
console.log("l", l); // 0
所以在while循环中,我们一般要采用前置运算符
let arr = [1,2,3,4,5,6,7,8]
let index = -1
while(++index < arr.length){
// 采用++index 如果使用index++ 会多出无用的最后一项 undefined
console.log("111",index,arr[index])
}
自增/自加运算符所在前后
let i = 5
function test(i){
console.log(--i)
}
test(i)
// 输出4
let i = 5
function test(i){
console.log(i--)
}
test(i)
// 输出5
所以,可以得出结论自增/自加运算符在变量后面的话,会先执行变量所在语句再执行自增/自加运算符
类方法不可枚举
http://es6.ruanyifeng.com/#docs/class
类的内部所有定义的方法,都是不可枚举的(non-enumerable)
class T {
constructor(config) {
this.config = config;
}
aaa() {
console.log('aaa');
}
bbb() {
console.log('bbb');
}
}
let t = new T();
for (let key in t) {
console.log(key);
}
// 打印输出 config
class Point {
constructor(x, y) {
// ...
}
toString() {
// ...
}
}
Object.keys(Point.prototype)
// []
Object.getOwnPropertyNames(Point.prototype)
// ["constructor","toString"]
上面代码中,toString方法是Point类内部定义的方法,它是不可枚举的。这一点与 ES5 的行为不一致。
也就是说for-in循环无法遍历类方法
var Point = function (x, y) {
// ...
};
Point.prototype.toString = function() {
// ...
};
Object.keys(Point.prototype)
// ["toString"]
Object.getOwnPropertyNames(Point.prototype)
// ["constructor","toString"]
上面代码采用 ES5 的写法,toString方法就是可枚举的。
那如果我们真的想要遍历类方法,该怎么办呢
class T {
constructor(config) {
this.config = config;
this.aaa = this.aaa.bind(this);
this.bbb = this.bbb.bind(this);
}
aaa() {
console.log('aaa');
}
bbb() {
console.log('bbb');
}
}
let t = new T();
for (let key in t) {
console.log(key);
}
// 输出
// config
// aaa
// bbb
forEach循环会遍历null
let arr = [1, 1, 1, null];
arr.forEach(item => {
console.log('111', item);
});
这里的null会打印出来,也就是说forEach循环会遍历null
类数组转化为数组
Array.prototype.slice.call
[网页链接](https://blog.csdn.net/hellokin
gqwe/article/details/52585169)
Array.prototype.slice.call(arguments)可以将 类数组 转化为真正的数组
什么是类数组?
有length属性,属性值为数字;其他属性值为数字‘0’,‘1’,等
var myobject ={ // array-like collection
length: 4,
'0': 'zero',
'1': 'one',
'2': 'two',
'3': 'three'
}
到了该去看看Array.prototype.slice源码的时候了!
查看 V8 引擎 array.js 的源码,可以将 slice 的内部实现简化为:
function slice(start, end) {
var len = ToUint32(this.length), result = [];
for(var i = start; i < end; i++) {
result.push(this[i]);
}
return result;
}
可以看出,slice 并不需要 this 为 array 类型,只需要有 length 属性即可。并且 length 属性可以不为 number 类型,当不能转换为数值时,ToUnit32(this.length) 返回 0.
多种调格式
- [].slice.call(arguments)
- Array.prototype.slice.call(arguments) //最高效
- new Array().prototype.slice.call(arguments)
扩展运算符
任何 Iterator 接口的对象,都可以用扩展运算符转为真正的数组。
var nodeList = document.querySelectorAll('div');
var array = [...nodeList];
上面代码中,querySelectorAll方法返回的是一个nodeList对象。它不是数组,而是一个类似数组的对象。这时,扩展运算符可以将其转为真正的数组,原因就在于NodeList对象实现了 Iterator 接口。 对于那些没有部署 Iterator 接口的类似数组的对象,扩展运算符就无法将其转为真正的数组。
tip:
扩展运算符内部调用的是数据结构的 Iterator 接口,因此只要具有 Iterator 接口的对象,都可以使用扩展运算符,比如 Map 结构。
let map = new Map([
[1, 'one'],
[2, 'two'],
[3, 'three'],
]);
let arr = [...map.keys()]; // [1, 2, 3]
如果对没有iterator接口的对象,使用扩展运算符,将会报错
Object.prototype.toString
在JavaScript中数据类型分为:1.基本类型,2.引用类型
基本类型:Undefined,Boolean,String,Number,Null 引用类型:Object (Array,Date,RegExp,Function)
var a = 'hello world';
var b = [];
var c = function(){};
1.首先:typeof
console.log(typeof (a)+';'+typeof (b)+';'+typeof (c))
输出:string;object;function
2.其次:instanceof
console.log(a instanceof Object) //false
console.log(b instanceof Object) //true
console.log(c instanceof Object) //true
console.log(a instanceof Array) //false
console.log(b instanceof Array) //true
console.log(c instanceof Array) //false
console.log(a instanceof Function) //false
console.log(b instanceof Function) //false
console.log(c instanceof Function) //true
从上面两个例题可以看出,typeof(),insctanceof,这两种方法都只能对简单的变量进行判断,如果比较复杂的变量判断时就会有误,不精确;
下面我们介绍Object.prototype.toString.call()方法;
3.Object.prototype.toString.call()
console.log(Object.prototype.toString.call(a))
console.log(Object.prototype.toString.call(b))
console.log(Object.prototype.toString.call(c))
输出:
[object String]
[object Array]
[object Function]
可以写个方法传值进入判断:
function isType(obj,type){
if(obj != ''){
return Object.prototype.toString.call(obj)==='[object '+type+']'
}else{
alert('对象不能为空')
}
}
console.log(isType('hello world','String')) //true
那为什么不直接用obj.toString()
同样是检测对象obj调用toString方法(关于toString()方法的用法的可以参考toString的详解),obj.toString()的结果和Object.prototype.toString.call(obj)的结果不一样,这是为什么?
这是因为toString为Object的原型方法,而Array ,function等类型作为Object的实例,都重写了toString方法。不同的对象类型调用toString方法时,根据原型链的知识,调用的是对应的重写之后的toString方法(function类型返回内容为函数体的字符串,Array类型返回元素组成的字符串…..),而不会去调用Object上原型toString方法(返回对象的具体类型),所以采用obj.toString()不能得到其对象类型,只能将obj转换为字符串类型;因此,在想要得到对象的具体类型时,应该调用Object上原型toString方法。
我们可以验证一下,将数组的toString方法删除,看看会是什么结果:
var arr=[1,2,3];
console.log(Array.prototype.hasOwnProperty("toString"));//true
console.log(arr.toString());//1,2,3
delete Array.prototype.toString;//delete操作符可以删除实例属性
console.log(Array.prototype.hasOwnProperty("toString"));//false
console.log(arr.toString());//"[object Array]"
删除了Array的toString方法后,同样再采用arr.toString()方法调用时,不再有屏蔽Object原型方法的实例方法,因此沿着原型链,arr最后调用了Object的toString方法,返回了和Object.prototype.toString.call(arr)相同的结果。
千万不能使用typeof来判断对象和数组,因为这两种类型都会返回”object”。
进行封装
可以写个方法传值进入判断:
function isType(obj,type){
if(obj != ''){
return Object.prototype.toString.call(obj)==='[object '+type+']'
}else{
alert('对象不能为空')
}
}
console.log(isType('hello world','String')) //true
高阶函数
高阶函数只是将函数作为参数或返回值的函数。
add = function(a,b){
return a + b;
};
function math(func,array){
return func(array[0],array[1]);
}
console.log(math(add,[1,2]));
> math(add,[1,2])
< 3
在jQuery中:
// Convert dashed to camelCase; used by the css and data modules
// Microsoft forgot to hump their vendor prefix (#9572)
camelCase: function( string ) {
return string.replace( rmsPrefix, "ms-" ).replace( rdashAlpha, fcamelCase );
}
高阶函数实现AOP
AOP(面向面编程)的主要作用是把一些核心业务逻辑模块无关的功能抽离出来,这些跟 业务逻辑无关的功能通常包括日志统计、安全控制、异常处理。这些功能出来之后, 通过“动态”的方式业辑模中。
Function.prototype.before = function (beforeFn) {
var _self = this; //保存原函数的引用
return function () {
//返回了包含了原函数和新函数的"代理"函数
beforeFn.apply(this, arguments) //执行新函数,修正this
return _self.apply(this, arguments) //执行原函数
}
}
Function.prototype.after = function (afterFn) {
var _self = this
return function () {
var ret = _self.apply(this, arguments)
afterFn.apply(this, arguments)
return ret
}
}
var func = function () {
console.log(2)
}
func = func.before(() => console.log(1)).after(() => console.log(3))
func() //输出1 2 3
数组在循环中删除元素
在数组循环中我们用splice删除一个元素,删除后会马上改变数组长度,为了保证我们循环的长度还是原数组长度,我们进行i–操作。
let arr = [1, 2, 3, 4, 5, 6, 7, 8, 9]
for (let i = 0; i < arr.length; i++) {
if (arr[i] === 3) {
arr.splice(i, 1)
i--
}
console.log(`下标 ${i} 的值为:${arr[i]} ,当前数组长度:${arr.length}`)
}
遍历9次等于原数组长度
下标 0 的值为:1 ,当前数组长度:9
下标 1 的值为:2 ,当前数组长度:9
下标 1 的值为:2 ,当前数组长度:8
下标 2 的值为:4 ,当前数组长度:8
下标 3 的值为:5 ,当前数组长度:8
下标 4 的值为:6 ,当前数组长度:8
下标 5 的值为:7 ,当前数组长度:8
下标 6 的值为:8 ,当前数组长度:8
下标 7 的值为:9 ,当前数组长度:8
如果不进行i–
let arr = [1, 2, 3, 4, 5, 6, 7, 8, 9]
for (let i = 0; i < arr.length; i++) {
if (arr[i] === 3) {
arr.splice(i, 1)
}
console.log(`下标 ${i} 的值为:${arr[i]} ,当前数组长度:${arr.length}`)
}
下标 0 的值为:1 ,当前数组长度:9
下标 1 的值为:2 ,当前数组长度:9
下标 2 的值为:4 ,当前数组长度:8
下标 3 的值为:5 ,当前数组长度:8
下标 4 的值为:6 ,当前数组长度:8
下标 5 的值为:7 ,当前数组长度:8
下标 6 的值为:8 ,当前数组长度:8
下标 7 的值为:9 ,当前数组长度:8
只遍历8次
AggregateError
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/AggregateError
Promise.any([Promise.reject(new Error("some error"))]).catch((e) => {
console.log(e instanceof AggregateError); // true
console.log(e.message); // "All Promises rejected"
console.log(e.name); // "AggregateError"
console.log(e.errors); // [ Error: "some error" ] 枚举所有errors
});
柯里化(Currying)
在计算机科学中,柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数且返回结果的新函数的技术。
柯里化可是函数式编程中的一个技巧
使函数理解并处理部分应用
http://www.zhangxinxu.com/wordpress/2013/02/js-currying/
柯里化有3个常见作用
- 参数复用
- 提前返回
- 延迟计算/运行
window和document之addEventListener区别
任何事件都会经上三个阶段
- 捕获
- 目标元素
- 冒泡
事件不管是捕获还是冒泡,都会经过window和document。
因此,你使用window.addEventListener和document.addEventListener来处理页面上的事件,区别仅仅在于,不同事件模型上,处理的顺序不一样:
- 捕获,window先于document
- 冒泡,document先于window
我们可以addEventListener的第三个参数来使用不同的事件模型,true代表我们想在捕获阶段处理事件,false代表我们想在冒泡阶段处理事件,默认是false。
- 捕获,从外面往里面触发事件
- 冒泡,从里面往外面触发事件
函数名是指针
函数名其实就是指向函数体的指针 不加括号, 可以认为是查看该函数的完整信息, 不加括号传参,相当于传入函数整体 加括号 表示立即调用(执行)这个函数里面的代码(花括号部分的代码)
<button id="btn">单击这里</button>
复制代码
function demo1(){
var m=5;
return m;
}
function demo2(){
var m=55;
alert(m);
}
var a=demo1;//a是整个函数体,是一个函数对象
var b=demo1();//b是函数执行后返回的值5
alert(demo1);
alert(demo1());
结果:
1.alert弹出框的的内容
function demo1(){
var m=5;
return m;
}
2.alert弹出框的的内容
5
函数名就是指针
canvas图片getImageData,toDataURL跨域问题
https://www.zhangxinxu.com/wordpress/2018/02/crossorigin-canvas-getimagedata-cors/
而主页面所在域名往往不一样,当需要需要对canvas图片进行getImageData()或toDataURL()操作的时候,跨域问题就出来了,而且跨域问题还不止一层。
首先,第一步,图片服务器需要配置Access-Control-Allow-Origin信息,例如:
此时,Chrome浏览器就不会有Access-Control-Allow-Origin相关的错误信息了,但是,还会有其他的跨域错误信息。
利用a标签下载文件
function downloadImage(url, fileName = '') {
// 阿里云cdn会根据url参数返回响应类型
url = url + '?response-content-type=application/octet-stream'
// 同域图片会忽略_blank属性执行下载
const a = document.createElement('a')
a.setAttribute('href', url)
a.setAttribute('target', '_blank')
// download属性值 跨域时无效
a.setAttribute('download', fileName)
document.body.appendChild(a)
a.click()
document.body.removeChild(a)
}
const url = 'https://image-cdn.xhvip100.com/dev/teacher/personal_poster/5df794972431320001aa5395.jpg'
downloadImage(url,"")
fastClick的原理
FastClick的实现原理是在检测到touchend事件的时候,会通过DOM自定义事件立即出发模拟一个click事件,并把浏览器在300ms之后的click事件阻止掉。
点击穿透问题
既然click点击有300ms的延迟,那对于触摸屏,我们直接监听touchstart事件不就好了吗?
使用touchstart去代替click事件有两个不好的地方。
- 第一:touchstart是手指触摸屏幕就触发,有时候用户只是想滑动屏幕,却触发了touchstart事件,这不是我们想要的结果;
- 第二:使用touchstart事件在某些场景下可能会出现点击穿透的现象。
什么是点击穿透?
假如页面上有两个元素A和B。B元素在A元素之上。我们在B元素的touchstart事件上注册了一个回调函数,该回调函数的作用是隐藏B元素。我们发现,当我们点击B元素,B元素被隐藏了,随后,A元素触发了click事件。
这是因为在移动端浏览器,事件执行的顺序是touchstart > touchend > click。而click事件有300ms的延迟,当touchstart事件把B元素隐藏之后,隔了300ms,浏览器触发了click事件,但是此时B元素不见了,所以该事件被派发到了A元素身上。如果A元素是一个链接,那此时页面就会意外地跳转。
用css解决ios点击300毫秒延迟
*,
*:before,
*:after {
// box-sizing: inherit;
@media screen and (max-width: 760px){
/* 解决 Ios 300毫秒延迟 */
touch-action: manipulation;
-webkit-overflow-scrolling: touch;
overflow-scrolling: touch;
}
}
manipulation
浏览器只允许进行滚动和持续缩放操作。任何其它被auto值支持的行为不被支持。启用平移和缩小缩放手势,但禁用其他非标准手势,例如双击以进行缩放。 禁用双击可缩放功能可减少浏览器在用户点击屏幕时延迟生成点击事件的需要。 这是“pan-x pan-y pinch-zoom”(为了兼容性本身仍然有效)的别名。
获取屏幕滚动高度
换句话说也就是获取 scollTop
var heightTop = document.documentElement.scrollTop || document.body.scrollTop;
console.log(heightTop);
Window pageXOffset 和 pageYOffset 属性
其定义:pageXOffset 设置或返回当前页面相对于窗口显示区左上角的 X 位置。pageYOffset 设置或返回当前页面相对于窗口显示区左上角的 Y 位置。
所有主流浏览器都支持 pageXOffset 和 pageYOffset 属性。
window.pageYOffset == window.scrollY; // 总是返回 true
sort
let res = [1,2,3,4]
res.sort((a,b)=>{
return a - b
})
// 总结:sort函数返回小于0,升序排列;sort函数返回大于0,降序排列
substr和substring
记住名字短的函数第二个参数是长度
substr(start,length)
| 参数 | 描述 |
|---|---|
| start | 必需。要抽取的子串的起始下标。必须是数值。如果是负数,那么该参数声明从字符串的尾部开始算起的位置。也就是说,-1 指字符串中最后一个字符,-2 指倒数第二个字符,以此类推。 |
| length | 可选。子串中的字符数。必须是数值。如果省略了该参数,那么返回从 stringObject 的开始位置到结尾的字串。 |
substring(start,stop)
| 参数 | 描述 |
|---|---|
| start | 必需。一个非负的整数,规定要提取的子串的第一个字符在 stringObject 中的位置。 |
| stop | 可选。一个非负的整数,比要提取的子串的最后一个字符在 stringObject 中的位置多 1。如果省略该参数,那么返回的子串会一直到字符串的结尾。 |
字符串可以使用slice
- 字符串可以使用slice()
- 字符串不可以使用splice()
在map和set中get一个对象
有一个很容易忽略的点,如果在map和set中get一个对象,因为对象是引用型数据,所以当我们修改这个对象时,对应map里面存储的这个对象也会变
let map = new Map()
map.set("aaa", { aa: "aa", zab: "bb" })
let obj = map.get("aaa")
obj.ccc = "ccc"
console.log(obj)
let afterOBj = map.get("aaa")
console.log(afterOBj)
console.log(obj === afterOBj) // true
map是有序的
Map 中的键值是有序的,因此,当对它进行遍历时,Map 对象是按插入的顺序返回键值
Map在涉及频繁增删键值对的场景下会有些性能优势。
获取map中第一个元素的值
let map = new Map()
map.set("a", "a")
map.set("b", "a")
map.set("c", "a")
map.set("d", "a")
console.log(map.keys()) //返回的是MapIterator对象
for (let item of map.keys()) {
console.log(item);
}
我们想获取map中第一个元素的值,又不想去循环map,该如何做?
map.keys()[0] 这样是取不到值的
正确的做法:
console.log(map.keys().next().value)
//a
getComputedStyle
https://blog.csdn.net/hnnd123/article/details/94555496
由于诸如ele.style.display这样的操作只能获取DOM元素的行内样式,所以获取结果可能与实际显示效果不符
通过getComputedStyle方法可以用来获取DOM元素实际显示时的样式
-
第一个参数指定一个用来获取计算样式的DOM元素,
-
第二个参数(可选)指定一个要匹配的伪元素的字符串,普通元素可省略或传null。
// 获取 grid 布局下所有元素 (grid 布局下元素宽高都是不确定的)
const gridItems = document.querySelectorAll('.grid-view .item');
// 获取具体元素高度
const itemHeight = parseFloat(getComputedStyle(gridItems[0]).getPropertyValue('height'))
// parseFloat 的作用 25.25px => 25.25 字符串变成数字
获取标签的名字
举一个在react的例子
<div onClick={(e)=>console.log(e.target.localName)}>1313</div>
// div
scrollIntoView
Element.scrollIntoView() 方法让当前的元素滚动到浏览器窗口的可视区域内。
语法
element.scrollIntoView(); // 等同于element.scrollIntoView(true)
element.scrollIntoView(alignToTop); // Boolean型参数
element.scrollIntoView(scrollIntoViewOptions); // Object型参数
alignToTop可选
一个Boolean
- 如果为
true,元素的顶端将和其所在滚动区的可视区域的顶端对齐。相应的scrollIntoViewOptions: {block: "start", inline: "nearest"}。这是这个参数的默认值。 - 如果为
false,元素的底端将和其所在滚动区的可视区域的底端对齐。相应的scrollIntoViewOptions: {block: "end", inline: "nearest"}。
scrollIntoViewOptions 可选
一个包含下列属性的对象:
-
behavior可选定义动画过渡效果,
"auto"或"smooth"之一。默认为"auto"。 -
block可选定义垂直方向的对齐,
"start","center","end", 或"nearest"之一。默认为"start"。 -
inline可选定义水平方向的对齐,
"start","center","end", 或"nearest"之一。默认为"nearest"。
取决于其它元素的布局情况,此元素可能不会完全滚动到顶端或底端。
理解constructor、prototype、__proto__和原型链
https://juejin.im/post/5cc99fdfe51d453b440236c3
- 对象由函数创建,函数都是Function对象实例
- constructor属性其实就是一个拿来保存自己构造函数引用的属性,没有其他特殊的地方
- prototype对象用于放某同一类型实例的共享属性和方法,实质上是为了内存着想。
- 默认constructor实际上是被当做共享属性放在它们的原型对象中。
- 实例对象.
__proto__= 创建自己的构造函数内部的prototype(原型对象) - 实例对象.
__proto__.constructor = 创建自己的构造函数 - 所有函数的
__proto__指向他们的原型对象,即Function函数的prototype对象 - 所有函数其实都是Function函数的实例
- 最后一个prototype对象是Object函数内的prototype对象。
- Object函数的prototype中的
__proto__指向null
真正的constructor属性藏在哪?
constructor属性为什么我就没在console出来的对象数据中看到呢?
思考个问题:
new Person( )出来的千千万万个实例中如果都有constructor属性,并且都指向创建自己的构造函数,那岂不它们都拥有一个效果相同但却都各自占用一部分内存的属性?
constructor是完全可以被当成一个共享属性存放在原型对象中,作用也依然是指向自己的构造函数,而实际上也是这么处理的。对象的constructor属性就是被当做共享属性放在它们的原型对象中
function Person() {}
var person1 = new Person()
var person2 = new Person()
console.log(person1.constructor) // [Function: Person]
console.log(person2.constructor) // [Function: Person]
person1.constructor = Function
console.log(person1.constructor) // [Function: Function]
console.log(person2.constructor) // [Function: Person] !不是同步为[Function: Function]
这个是因为person1.constructor = Function改的并不是原型对象上的共享属性constructor,而是给实例person1加了一个constructor属性。如下:
console.log(person1)
// 结果:Function { constructor: [Function: Function] }
你可以看到person1实例中多了constructor属性。它原型对象上的constructor是没有改的。
所以说,实例对象.constructor 即等于去找 实例对象.
__proto__.constructor
为什么Object函数不能像Function函数一样让__proto__属性指向自己的prototype?
答案就是如果指向自己的prototype,那当找不到某一属性时沿着原型链寻找的时候就会进入死循环,所以必须指向null,这个null其实就是个跳出条件。
null >= 0 为 true
console.log(null > 0); // false
console.log(null < 0); // false
console.log(null >= 0); // true
console.log(null <= 0); // true
console.log(null == 0); // false
console.log(null === 0); // false
不要把 拿 a > b , a == b 的结果 想当然的去和 a >= b 建立联系
null > 0 // null 尝试转型为number , 则为0 . 所以结果为 false,
null >= 0 // null 尝试转为number ,则为0 , 结果为 true.
null == 0 // null在设计上,在此处不尝试转型. 所以 结果为false.
>=的结果可以根据<的结果推出
因为null<0为false,所以null>=0为true;
IntersectionObserver
https://developer.mozilla.org/zh-CN/docs/Web/API/IntersectionObserver
http://www.ruanyifeng.com/blog/2016/11/intersectionobserver_api.html
IntersectionObserver 常常被用作懒加载
IntersectionObserver的兼容性并不好,IE上无法使用
IntersectionObserver接口 (从属于Intersection Observer API) 提供了一种异步观察目标元素与其祖先元素或顶级文档视窗(viewport)交叉状态的方法。祖先元素与视窗(viewport)被称为根(root)。
当一个IntersectionObserver对象被创建时,其被配置为监听根中一段给定比例的可见区域。一旦IntersectionObserver被创建,则无法更改其配置,所以一个给定的观察者对象只能用来监听可见区域的特定变化值;然而,你可以在同一个观察者对象中配置监听多个目标元素。
var intersectionObserver = new IntersectionObserver(function(entries) {
// If intersectionRatio is 0, the target is out of view
// and we do not need to do anything.
if (entries[0].intersectionRatio <= 0) return;
loadItems(10);
console.log('Loaded new items');
});
// start observing
intersectionObserver.observe(document.querySelector('.scrollerFooter'));
entries 参数,它是个IntersectionObserverEntry对象数组
IntersectionObserverEntry提供观察元素的信息,有七个属性。
- boundingClientRect 目标元素的矩形信息
- intersectionRatio 相交区域和目标元素的比例值 intersectionRect/boundingClientRect 不可见时小于等于0
- intersectionRect 目标元素和视窗(根)相交的矩形信息 可以称为相交区域
- isIntersecting 目标元素当前是否可见 Boolean值 可见为true
- rootBounds 根元素的矩形信息,没有指定根元素就是当前视窗的矩形信息
- target 观察的目标元素
- time 返回一个记录从
IntersectionObserver的时间到交叉被触发的时间的时间戳
intersectionRatio和isIntersecting是用来判断元素是否可见的
总结:其实就是观察一个元素是否在视窗可见。
总结:其实就是观察一个元素是否在视窗可见。
总结:其实就是观察一个元素是否在视窗可见。
即时编译(JIT)
当某部分代码被打上热点标之后,V8 就会将这部分字节码甩给优化编译器,优化编译器会在后台将这部分字节码编译为二进制。如果后面再执行到这部分代码时,V8 会优先选择编译之后的二进制,这样代码的执行速度就大大提升了。这就是即时编译(JIT)技术。
然后,众所周知,JavaScript 是一门动态语言,运行时可以修改对象,但是经过优化编译器编译的代码只是针对某一种固定的结构,一旦对象的结构被动态修改,那么这部分编译优化的代码就需要反优化操作,否则就是无效代码。经过反优化的代码,下次执行时就会回退到解释器解释执行。
V8 引入字节码,也就有了一个相对弹性的空间,内存和执行速度之间就可以去做调节。相比直接将 JS 代码全部编译成字节码(早期的 V8 其实就是这样,后来由于移动端兴起导致的内存问题,便有了现在的结构)
ServiceWorker 和 WebWorker
Web Workers 是 现代浏览器 提供的一个javascript多线程解决方案,我们可以将一些大计算量的代码交由web Worker运行。JavaScript语言执行采用的是单线程模型,也就是说,所有任务排成一个队列,一次只能做一件事。但是有了webworker后就不一样了。
Service Worker是基于Web Worker的事件驱动的,他们执行的机制都是新开一个线程去处理一些额外的,以前不能直接处理的任务。对于Web Worker,我们可以使用它来进行复杂的计算,因为它并不阻塞浏览器主线程的渲染。而Service Worker,我们可以用它来进行本地缓存或请求转发,相当于一个浏览器端本地的proxy。
例如使用Service Worker来进行缓存,是用javascript代码来拦截浏览器的http请求,并设置缓存的文件,直接返回,不经过web服务器,然后,我们就可以开发基于浏览器的离线应用。这使得我们的web应用减少对网络的依赖。 如果我们使用了Service Worker做缓存,浏览器http请求会先经过Service Worker,通过url mapping去匹配,如果匹配到了,则使用缓存数据,如果匹配失败,则继续执行你指定的动作。一般情况下,匹配失败则让页面显示“网页无法打开”。
ServiceWorker
报错:the current origin (‘null’) is not supported
SW registration failed with error SecurityError: Failed to register a ServiceWorker: The URL protocol of the current origin (‘null’) is not supported.
The 1st argument to ServiceWorkerContainer.register is an URL. The error message indicates that your browser is refusing to use a resource because the origin is null - which happens often for local (file://) resources. service-worker.js is local - I’ll bet this is why you’re getting the cross origin resource issue
Service worker will work only if you run it on a server. Just by opening the index.html from the finder will not work. You can use python -m SimpleHTTPServer or any to get started.
服务工作者只有在服务器上运行时才能工作。仅仅从finder中打开index.html是不起作用的。
第一件事是服务工作者只能在https或localhost中的安全模式下工作。 它不适用于本地资源,例如file://或http。
Web Worker
https://developer.mozilla.org/zh-CN/docs/Web/API/Web_Workers_API/Using_web_workers
从主线程传递到worker线程的消息数据要经过序列化转换。当此序列化数据到达worker线程时,它被反序列化,并且数据可用作JavaScript基本类型。当worker线程想要将数据发送回主线程时,使用同样的过程。
毋庸置疑,这是一个多余的步骤,给我们可能已经过度工作的应用程序增加了开销。因此,必须考虑在线程之间来回传递数据,因为从CPU成本方面来说这不是轻松的操作
The close() method is visible inside the worker’s scope. The terminate() method is a part of the worker object’s interface and can be called “from the outside”.
跨域
https://zhuanlan.zhihu.com/p/47878150
Web Workers 在使用过程中要求加载的 JS 文件 URL 必须与当前 Domain 保持同源,即 同源策略,否则就会抛出错误。
postMessage transfer
https://developer.mozilla.org/zh-CN/docs/Web/API/Worker/postMessage
transfer: 一个可选的、会被转移所有权的可转移对象数组。如果一个对象的所有权被转移,它将在发送它的上下文中变为不可用(中止),而仅在接收方的 worker 中可用。
像 ArrayBuffer、MessagePort 或 ImageBitmap 类的实例才是可转移对象,才能够被转移。不能将 null 作为 transfer 的值。
Worker 之间通信
const channel = new MessageChannel();
receivingWorker.postMessage({port: channel.port1}, [channel.port1]);
sendingWorker.postMessage({port: channel.port2}, [channel.port2]);
importScripts
https://developer.mozilla.org/zh-CN/docs/Web/API/WorkerGlobalScope/importScripts
问题:
Cannot use import statement outside a module
解决:
const myWorker = new Worker(aURL, options);
const url = new URL('./worker.ts', import.meta.url)
new Worker(url, {
type: 'module', // 注意这个
})
type:用以指定 worker 类型的DOMString值。该值可以是classic或module. 如果未指定,将使用默认值classic.
Failed to execute ‘importScripts’ on ‘WorkerGlobalScope’: Module scripts don’t support importScripts().
type: ‘module’ 时 worker 里面不支持importScripts
在class中使用箭头函数作为属性
https://www.jianshu.com/p/989a2eb87046
class Warrior{
constructor(element){
this.element = element
}
// 这个是属性会至于原型链 __proto__ 上
ready(){
return `${this.element} is ready for attaching `
}
}
const aWarrior = new Warrior("zidea")
const button = {
onClick : null
}
button.onClick = aWarrior.ready
button.onClick()
因为ready在aWarrior的__proto__上,所以运行的结果不难想象应该为 undefined is ready for attaching undefine
这是因为 button onclick 引用了 Warrior 的 attach 的方法。但是这里 button 中并没有 element 这个属性。所以 undefined。这也就是我们常说的 this 指向的问题。
button.onClick = aWarrior.ready.bind(aWarrior)
button.onClick()
我们通过 bind 的方法将我们方法绑定到指定的对象,这样我们的方法就有了 context 也就是上下文
当然我们也可以也使用 es6 的箭头函数作为 ready 属性,这个箭头好处就是我无需再写 bind 来讲方法绑定到指定对象,箭头方法中 this 对象。
// 改写ready
// 这样ready不会在 __proto__ 上 而会在new出来的实例上
ready = ()=>{
return `${this.element} is ready for attaching `
}
e.persisted
最近,看flexible.js源码发现这样一块源码,里面用到persisted
win.addEventListener('pageshow', function(e) {
if (e.persisted) {
clearTimeout(tid);
tid = setTimeout(refreshRem, 300);
}
}, false);
persisted属性返回一个布尔值,指示是否直接从服务器加载网页,或者当发生pageshow或pagehide事件时页面是否被缓存。此属性是只读的。
一个布尔值,指示网页是否从缓存加载。
- 可能的值:true - 页面由浏览器缓存
- false - 浏览器不缓存页面
byte[]和string相互转换
最近在用qqtea算法进行数据的加密解密,在和后端的对接中,要使用到byte[]和string相互转换,这里简单探究一下。
Byte数组的例子:[13, 60, 70, 27, 75, 186, 159, 221, 206, 96, 25, 89, 165, 149, 238, 90, 92, 13, 57, 38, 56, 201]
stringToBytes
字符串转Byte数组
注意高性能版本:stringToBytes1测试时会有问题,并未上生产环境,尽量勿用
// 高性能版本
function stringToBytes1(str) {
var bytes = new Array();
var len, c;
len = str.length;
for (var i = 0; i < len; i++) {
c = str.charCodeAt(i);
if (c >= 0x010000 && c <= 0x10FFFF) {
bytes.push(((c >> 18) & 0x07) | 0xF0);
bytes.push(((c >> 12) & 0x3F) | 0x80);
bytes.push(((c >> 6) & 0x3F) | 0x80);
bytes.push((c & 0x3F) | 0x80);
} else if (c >= 0x000800 && c <= 0x00FFFF) {
bytes.push(((c >> 12) & 0x0F) | 0xE0);
bytes.push(((c >> 6) & 0x3F) | 0x80);
bytes.push((c & 0x3F) | 0x80);
} else if (c >= 0x000080 && c <= 0x0007FF) {
bytes.push(((c >> 6) & 0x1F) | 0xC0);
bytes.push((c & 0x3F) | 0x80);
} else {
bytes.push(c & 0xFF);
}
}
return bytes;
}
// 低性能版本
function stringToBytes2(str) {
let ch;
let st;
let re = [];
for (let i = 0; i < str.length; i++) {
ch = str.charCodeAt(i); // get char
st = []; // set up "stack"
do {
st.push(ch & 0xFF); // push byte to stack
ch = ch >> 8; // shift value down by 1 byte
}
while (ch);
re = re.concat(st.reverse());
}
return re;
}
1000次测试:
- stringToBytes1 耗时10ms左右
- stringToBytes2 耗时260ms左右
bytesToString
Byte数组转字符串转
function bytesToString(arr) {
let str = ""
for (let i = 0; i < arr.length; i++) {
str += String.fromCharCode(arr[i]);
}
return str;
}
1000次测试:
- bytesToString 耗时10ms左右
控制异步任务大量并发
有时候仅仅是单个依次执行任务又过于节约了,所以我们也要允许多个任务「并发」执行。
import _ from 'lodash'
const { maxParallelExecuteCount = 1 } = this.config;
const chunkedTasks = _.chunk(this.tasks, maxParallelExecuteCount);
return chunkedTasks.reduce((prevPromise, curChunkedTask) => {
return prevPromise.then(prevResults => {
return Promise.all(
curChunkedTask.map(curTask => {
let curPromise = curTask()
curPromise = !isPromiseObj(curPromise) ? Promise.resolve(curPromise) : curPromise
return curPromise
})
).then(curChunkedResults => [ ...prevResults, curChunkedResults ])
})
}, Promise.resolve([]))
Reflect
https://www.zhangxinxu.com/wordpress/2021/07/js-proxy-reflect/
Javascript中的一个内置对象,它提供了一组用于操作对象的方法,包括获取对象属性、设置对象属性、调用对象方法、定义新属性等
使用Reflect 的好处:
Reflect.set可以知道设置是否成功
console.log(input.type = 'number');
// 输出 false
console.log(Reflect.set(input, 'type', 'number'));
不会因为报错而中断正常的代码逻辑执行
'use strict';
var frozen = { 1: 81 };
Object.freeze(frozen);
frozen[1] = 'zhangxinxu';
console.log('no log'); // 不会执行
上面的例子会出现TypeError
如果使用Reflect
'use strict';
var frozen = { 1: 81 };
Object.freeze(frozen);
Reflect.set(frozen, '1', 'zhangxinxu');
console.log('no log'); // 会执行
为什么proxy里一定要使用reflect
举个例子:
const obj = {
_name: 'test',
get name(){
return this._name;
}
};
const proxyObj = new Proxy(obj,{
get(target, property, receiver){
return target[property];
},
});
const child = {
_name: 'child'
};
Reflect.setPrototypeOf(child, proxyObj);
child.name // test
proxyObj.name // test
因为代理对象的get拦截中固定返回的target[property]; target永远指向obj 所以拿到的永远是obj的_name属性值。
const obj = {
_name: 'test',
get name(){
return this._name;
}
};
const proxyObj = new Proxy(obj,{
get(target, property, receiver){
return Reflect.get(target, property, receiver)
},
});
const child = {
_name: 'child'
};
Reflect.setPrototypeOf(child, proxyObj);
child.name // child
proxyObj.name // test
当我们使用Reflect时可以正确转发运行时上下文; 其实主要就是receiver这个参数,receiver 代表的是代理对象本身或者继承自代理对象的对象,它表示触发陷阱时正确的上下文。
try/catch为何捕获不到异步错误
1.try-catch通常(注意在这里是“通常”)高级语言才有,由脚本解释器(或者运行时环境)层实现。
2.在try block 内才跳转到对应的catch block 块。
js 的异步跟事件循环有莫大关系,事件循环伪代码如下
var event;
while (event = getNextEvent()) { // 一直循环是否有事件
getListeners(event).forEach(function(listener){
//一个事件可以绑定多个listener,所以是循环这里!
listener(event);
});
}
js中执行一个异步代码块,实际会经历多次事件循环。我们把先前的异步代码切分成两份,蓝色部分和红色部分。

伪代码分两次事件循环执行如下:
// 第一次循环时执行蓝色部分
var event;
while (event = getNextEvent()) {
getListeners(event).forEach(function(listener){
try {
setTimeout(..., 1000)
}
catch(e){
console.log(e);
}
});
}
// 第二次循环时执行红色部分
var event;
while (event = getNextEvent()) {
getListeners(event).forEach(function(listener){
throw "exception"
});
}
当第一次进入事件循环时,try block 里的指令setTimeout表示此次不执行函数参数里的指令,延长1000毫秒执行。基于事件循环机制,这将会把函数参数里的指令块throw "exception"放到下一次循环,或者下下一次循环(这主要看延迟多少时间执行了)。当执行完setTimeout时,意味着try block 内所有指令执行完毕(这里try block 块里只有一条指令),此时是没有抛出任何异常。所以没有执行catch block里的指令。
假设当第二次进入事件循环时,执行到throw指令,此时发现并没有一个try..catch为它“服务”了。此时程序也不会再往下执行,整个事件循环终止,程序异常退出。这就是try..catch 捕获不到异步执行抛出的异常的原因。
js库环境兼容判断exports.nodeType
https://segmentfault.com/q/1010000015353836
我们去看underscore源码时,发现他的环境兼容处理是
if (typeof exports != "undefined" && !exports.nodeType) {
if (typeof module != "undefined" && !module.nodeType && module.exports) {
exports = module.exports = _;
}
exports._ = _;
} else {
root._ = _;
}
为什么要判断exports.nodeType是否为空呢?
为了防止下面这种情况
<div id="exports"></div>
<div id="module"></div>
如果存在这种带id的元素 可以通过window.xxx 获取到元素 (xxx 为 元素的id名)
监听滚轮滑动事件
vue中
<slider ref="slider" :pages="mypages" :sliderinit="slider" @mousewheel.native="mouseScroll">
</slider>
将组件变成了普通的HTML标签,不加’. native’事件是无法触发的。
mouseScroll(e){
console.log(e.wheelDelta)
if (e.wheelDelta < 0) {
//向下
this.$refs.slider.$emit('slideNext')
} else {
//向上
this.$refs.slider.$emit('slidePre')
}
}
普通js中
注意: onmousewheel不兼容火狐浏览器,只能监听”DOMMouseScroll”
function addMouseWheelEvent(element,func) {
if (typeof element.onmousewheel == "object") {
element.onmousewheel = function() {
func();
};
}
if (typeof element.onmousewheel == "undefined") {
element.addEventListener("DOMMouseScroll",func,false);
}
}
在给元素指定mousewheel事件时,对应的event对象会有一个wheelDelta属性(规范中的属性),当用户向前滚动滚轮时,其值是120的整数倍,当用户向后滚动滚轮时,其值是-120的整数倍。当然在FireFox中这个属性不叫wheelDelta,而是叫detail,当用户向前滚动滚轮时,detail的值是-3的整数倍,当用户向后滚动滚轮时,detail的值是3的整数倍,正负号与wheelDelta的值是相反的。
监听手指移动
http://blog.csdn.net/kk_yanwu/article/details/73251310
移动端
- touchstart:触摸开始的时候触发
- touchmove:手指在屏幕上滑动的时候触发
- touchend:触摸结束的时候触发
会传入event参数
event里面有
- touches:表示当前跟踪的触摸操作的touch对象的数组。
- targetTouches:特定于事件目标的Touch对象的数组。
- changeTouches:表示自上次触摸以来发生了什么改变的Touch对象的数组。
每个touches包含的属性
- clientX:触摸目标在视口中的x坐标。
- clientY:触摸目标在视口中的y坐标。
- identifier:标识触摸的唯一ID。
- pageX:触摸目标在页面中的x坐标。
- pageY:触摸目标在页面中的y坐标。
- screenX:触摸目标在屏幕中的x坐标。
- screenY:触摸目标在屏幕中的y坐标。
- target:触目的DOM节点目标。
在touchend里的event获取不到touches[0]只能获取changeTouches[0]
在Vue中
<template>
<div class="singer2"
@touchstart.prevent="onTouchStart"
@touchmove.prevent="onTouchMove"
@touchend.prevent="onTouchEnd">
</div>
</template>
<script type="text/ecmascript-6">
export default{
created(){
this.touch = {}
},
methods: {
onTouchStart(e){
this.touch.initiated = true
// 用来判断是否为一次移动
this.touch.moved = false
const touch = e.touches[0]
this.touch.startX = touch.pageX
this.touch.startY = touch.pageY
},
onTouchMove(e){
if (!this.touch.initiated) {
return
}
const touch = e.touches[0]
const deltaX = touch.pageX - this.touch.startX
const deltaY = touch.pageY - this.touch.startY
console.log(`在x轴移动: ${deltaX}`)
console.log(`在y轴移动: ${deltaY}`)
// if (Math.abs(deltaY) > Math.abs(deltaX)) {
// // 手指在Y轴的趋势比在X轴明显
// return
// }
if (!this.touch.moved) {
this.touch.moved = true
}
},
onTouchEnd(){
if (!this.touch.moved) {
return
}
// ...
// 剩下操作
this.touch.initiated = false
}
}
}
</script>
PC web端
有一点要非常非常地注意: mousedown在Dom元素上监听,而mousemove和mouseup要在document上监听。
反面例子:
//拖动
var ismove = false; //标记移动
var initMove = false; //一次移动的开始
var _x, _y; //鼠标距离左上角的位置
$(document).ready(function () {
$("#spig").mousedown(function (e) {
console.log("开始移动")
initMove = true;
}).mousemove(function (e) {
if (initMove) {
console.log("移动中")
}
}).mouseup(function (e) {
console.log("移动结束")
initMove = false;
})
})
正面例子:
拖动:
var isMove = false; //标记移动
var initMove = false; //一次移动的开始
var _x, _y; //鼠标距离左上角的位置
$(document).ready(function () {
$("#spig").mousedown(function (e) {
initMove = true;
_x = e.pageX - parseInt($("#spig").css("left"));
_y = e.pageY - parseInt($("#spig").css("top"));
})
$(document).mousemove(function (e) {
if (initMove) {
var x = e.pageX - _x;
var y = e.pageY - _y;
var wx = $(window).width() - $("#spig").width()
var dy = $(document).height() - $("#spig").height()
if (x > 0 && x <= wx && y > 0 && y <= dy) {
$("#spig").css({
top: y,
left: x
})
}
isMove = true;
}
}).mouseup(function () {
if (initMove && isMove) {
initMove = false;
isMove = false;
}
})
})
var _x, _y; //鼠标离控件左上角的相对位置
_x = e.pageX - parseInt($("#spig").css("left"));
_y = e.pageY - parseInt($("#spig").css("top"));
$(window).width() 是获得整个窗体的宽度 $(document).height() 是获得整个文档的高度 可能会大于$(window).height() //窗体高度
在这个例子中允许拖动的高度应该是$(document).height() - $(‘#spig’).height();
获取DOM中所有图片
获取 DOM 里的图片主要是在这几个地方里面找:
<img>元素- background-image CSS 属性
<iframe>。
如果只想获取 <img> 的图片,有两种方式:
直接获取所有 img 标签:
function getImgs (doc) {
return Array.from(doc.getElementsByTagName('img'))
.map(img => ({
src: img.currentSrc, // 用 img.src 如果要本来的 src
width: img.naturalWidth,
height: img.naturalHeight
}))
}
getImgs(document)
还可以用 document.images:
function getImgs (doc) {
return Array.from(doc.images)
.map(img => ({
src: img.currentSrc, // img.src if you want the origin
width: img.naturalWidth,
height: img.naturalHeight
}))
}
getImgs(document)
background-image
获得背景图片需要查看所有 DOM 节点的 background-image 属性:
function getBgImgs (doc) {
const srcChecker = /url\(\s*?['"]?\s*?(\S+?)\s*?["']?\s*?\)/i
return Array.from(
Array.from(doc.querySelectorAll('*'))
.reduce((collection, node) => {
let prop = window.getComputedStyle(node, null)
.getPropertyValue('background-image')
// match `url(...)`
let match = srcChecker.exec(prop)
if (match) {
collection.add(match[1])
}
return collection
}, new Set())
)
}
getBgImgs(document)
背景图片不能直接得到尺寸信息,如果需要的话要加载一遍。因为搜集的图片很有可能已经在浏览器缓存里,所以加载过程应该很快。
function loadImg (src, timeout = 500) {
var imgPromise = new Promise((resolve, reject) => {
let img = new Image()
img.onload = () => {
resolve({
src: src,
width: img.naturalWidth,
height: img.naturalHeight
})
}
img.onerror = reject
img.src = src
})
var timer = new Promise((resolve, reject) => {
setTimeout(reject, timeout)
})
return Promise.race([imgPromise, timer])
}
function loadImgAll (imgList, timeout = 500) {
return new Promise((resolve, reject) => {
Promise.all(
imgList
.map(src => loadImg(src, timeout))
.map(p => p.catch(e => false))
).then(results => resolve(results.filter(r => r)))
})
}
loadImgAll(getBgImgs(document)).then(imgs => console.log(imgs))
iframe:
只需要递归遍历 iframe 的 document
function searchIframes (doc) {
var imgList = []
doc.querySelectorAll('iframe')
.forEach(iframe => {
try {
iframeDoc = iframe.contentDocument || iframe.contentWindow.document
imgList = imgList.concat(getImgs(iframeDoc) || []) // or getBgImgs(iframeDoc)
imgList = imgList.concat(searchIframes(iframeDoc) || [])
} catch (e) {
// 直接忽略错误的 iframe (e.g. cross-origin)
}
})
return imgList
}
searchIframes(document)
最后整合在一起就可以了
webassembly
http://webassembly.org.cn/getting-started/js-api/
方法的 imports 和 exports
在未来计划中,WebAssembly 模块可以使用 ES6 模块(使用<script type="module">)加载,WebAssembly 目前只能通过 JavaScript 来加载和编译。基础的加载,只需要3步:
- 获取
.wasm二进制文件,将它转换成类型数组或者ArrayBuffer - 将二进制数据编译成一个
WebAssembly.Module - 使用 imports 实例化这个
WebAssembly.Module,获取 exports。
function instantiate(bytes, imports) {
return WebAssembly.compile(bytes).then(m => new WebAssembly.Instance(m, imports));
}
var importObject = { imports: { i: arg => console.log(arg) } };
fetch('simple.wasm').then(response => response.arrayBuffer())
.then(bytes => instantiate(bytes, importObject))
.then(instance => instance.exports.e());
Memory
Linear memory 是 WebAssembly 的另外一种构建块,通常用于表示编译的 C/C++ 应用程序的整个堆。从 JavaScript 的角度,linear memory(后面称作 memory)可以被认为是一个可以调整大小的 ArrayBuffer,它是通过尽心优化的,用于负载和存储的低开销沙箱。
Memories 可以被 JavaScript 创建,需要提供出初始大小和最大的大小这些选项。
var memory = new WebAssembly.Memory({initial:10, maximum:100});
全屏 API
https://developer.mozilla.org/zh-CN/docs/Web/API/Fullscreen_API
全屏 API 为使用用户的整个屏幕展现网络内容提供了一种简单的方式,并且在不需要时退出全屏模式。这种 API 让你可以简单地控制浏览器,使得一个元素与其子元素,如果存在的话,可以占据整个屏幕,并在此期间,从屏幕上隐藏所有的浏览器用户界面以及其他应用。
-
用于请求从全屏模式切换到窗口模式,会返回一个
Promise,会在全屏模式完全关闭的时候被置为 resolved 状态 -
请求浏览器(user agent)将特定元素(甚至延伸到它的后代元素)置为全屏模式,隐去屏幕上的浏览器所有 UI 元素,以及其它应用。返回一个
Promise,并会在全屏模式被激活的时候变成 resolved 状态。
storage事件
💡HTML5 storage事件监听:当同源页面的某个页面修改了localStorage,其余的同源页面只要注册了storage事件,就会触发
Web Storage API内建了一套事件通知机制,当存储区域的内容发生改变(包括增加、修改、删除数据)时,就会自动触发 storage 事件,并把它发送给所有感兴趣的监听者。因此,如果需要跟踪存储区域的改变,就需要在关心存储区域内容的页面监听storage事件。
window.addEventListener("storage", (e)=>{
// 获取 e 后做一系列判断操作
}, false);
实际上,这个事件e上还带有很多信息,可以对事件做精确的控制 👇。
| 字段 | 含义 |
|---|---|
| key | 发生变化的 storageKey |
| newValue | 变换后新值 |
| oldValue | 变换前原值 |
| storageArea | 相关的变化对象 |
| url | 触发变化的 URL,如果是 frameset 内,则是触发帧的 URL |
event中的offsetX触发到子元素
event中的offsetX 会触发到子元素中
应该怎么解决?
- 在事件捕获阶段处理,阻止冒泡。 e.stopPropagation(); e.preventDefault();
- 判断元素 e.target === 父元素 时候获取
- 用 event.pageX - xxx.getBoundingClientRect().left 代替
matchMedia
https://developer.mozilla.org/zh-CN/docs/Web/API/Window/matchMedia
Window 的 matchMedia() 方法返回一个新的 MediaQueryList 对象,表示指定的媒体查询 (en-US)字符串解析后的结果。返回的 MediaQueryList 可被用于判定 Document 是否匹配媒体查询,或者监控一个 document 来判定它匹配了或者停止匹配了此媒体查询。
横竖屏判断)
要判断设备的方向,可以使用orientation属性和媒体查询。orientation属性有两个可能的值:portrait(纵向)和landscape(横向)
window.matchMedia('(orientation: portrait)');
matchMedia(‘(orientation: portrait)’) 的作用是检测当前设备的屏幕方向是否为纵向(竖屏)方向。根据传入的媒体查询条件,它会返回一个 MediaQueryList 对象,可以通过该对象的 matches 属性来判断当前设备的屏幕方向是否匹配查询条件。如果匹配条件,则 matches 属性为 true,否则为 false。
const mql = window.matchMedia('(orientation: portrait)');
// 一开始我们可以从 mql.matches 判断最初状态是 横屏/竖屏
// 定义回调函数
const handleChange = (event) => {
if (event.matches) {
console.log("竖屏")
} else {
console.log("横屏")
}
};
// 添加事件监听
mql.addEventListener('change', handleChange)
dark mode
How do I detect dark mode using JavaScript?
if (window.matchMedia && window.matchMedia('(prefers-color-scheme: dark)').matches) {
// dark mode
}
window.matchMedia('(prefers-color-scheme: dark)').addEventListener('change', event => {
const newColorScheme = event.matches ? "dark" : "light";
});
https://cn.windicss.org/features/dark-mode.html
像 Windi CSS 这种库
默认情况下,启用的是 class 模式。
Mutex 锁
export class Mutex {
private mutex = Promise.resolve();
lock(): PromiseLike<() => void> {
let begin: (unlock: () => void) => void = () => null;
this.mutex = this.mutex.then(() => {
// unlock() 调用之后 触发这里then的回调
return new Promise(begin);
});
return new Promise((res) => {
begin = res;
});
}
async dispatch<T>(fn: (() => T) | (() => PromiseLike<T>)): Promise<T> {
const unlock = await this.lock();
try {
// 如果传入的参数已经是 Promise 对象,Promise.resolve 会直接返回这个 Promise,而不会创建一个新的 Promise。
// 这保证了在链式调用中,Promise 的状态不会被无意中改变。
return await Promise.resolve(fn());
} finally {
unlock();
}
}
}
例子:
const sleep1 = async () => {
await new Promise(resolve => setTimeout(() => {
console.log("sleep1")
resolve(111)
}, 5000))
}
const sleep2 = async () => {
await new Promise(resolve => setTimeout(() => {
console.log("sleep2")
resolve(2222)
}, 10000))
}
const mutex = new Mutex()
mutex.dispatch(sleep1) // 先执行完这个
mutex.dispatch(sleep2) // 才会执行
pagehide 和 visibilitychange 和 beforeunload
https://developer.chrome.com/blog/deprecating-unload/
pagehide和visibilitychange是两个与页面可见性相关的事件,它们在不同的场景下触发。
pagehide事件在页面即将离开用户的视图之前触发。通常在以下情况下会触发pagehide事件:
- 用户关闭当前页面
- 用户点击到一个新的页面链接
- 用户切换到浏览器的其它标签页或应用
- 用户执行了浏览器的前进/后退操作
相比之下,visibilitychange事件在页面的可见性发生变化时触发。页面的可见性可以通过浏览器窗口被最小化、隐藏到后台标签页、操作系统的锁屏等方式发生变化。这个事件适用于以下场景:
- 当用户最小化浏览器窗口或切换到其它应用时
- 当用户恢复浏览器窗口或切换回当前标签页时
- 在移动设备上,当屏幕被锁定或解锁时
综上所述,pagehide事件主要监听页面即将离开用户视图的情况,而visibilitychange事件则监听页面可见性的变化。
beforeunload事件:
-
触发时机:在页面即将卸载之前触发,也就是在用户关闭页面、刷新页面、导航到其他页面等操作之前触发。
-
执行操作:可以在此事件中执行一些清理操作,例如关闭WebSocket、清除定时器、发送最后的请求等。
- beforeunload:在此事件中执行的操作可能会阻塞页面的关闭或离开,因此必须谨慎使用。
- pagehide事件不会阻塞页面的关闭或离开,因此可用于执行一些较轻量级的操作。
protobuf.js
安装依赖:
"protobufjs":"^7.2.5", // dependencies
"protobufjs-cli":"^1.1.2" // devDependencies
利用 pb cli 将proto 文件转为 静态js文件
https://github.com/protobufjs/protobuf.js/blob/HEAD/cli/README.md#pbjs-for-javascript
"build:proto": "pbjs -t static-module --no-verify --no-convert -w es6 -o src/proto/proto.js src/proto/LrcTime.proto"
// tip: no-decode 如果不需要解码的话 => 节省体积
使用例子:
import { LrcTime } from "../proto/proto.js"
const msg = LrcTime.create({
// ....
})
// encode
const encodeData = LrcTime.encode(msg).finish()
// decode
反射 Reflect
在ts 中通过装饰器和注解实现反射机制
反射(reflect)是指在程序运行期间对程序本身进行检查和操作的能力。在编程中,反射可以让程序在运行期间动态地获取和使用类型信息,包括类的成员变量、方法、构造函数等,并对它们进行操作。通过反射,可以在运行时动态创建对象、调用方法、获取和修改字段的值等。
反射机制可以让程序在编译时并不需要知道或依赖具体的类型,而是通过获取对象的类型信息来进行操作,从而增强了程序的灵活性和可扩展性。反射被广泛应用于很多领域,例如框架开发、ORM(对象关系映射)、序列化和反序列化、动态代理等。
需要注意的是,由于反射是在运行期间进行类型检查和操作的,所以使用反射机制会带来一定的性能开销,尤其是在频繁调用的场景中。因此,在性能要求较高的场景中,应尽量避免滥用反射,在合适的地方使用反射来提升程序的灵活性和可扩展性。
crypto.getRandomValues 和 Math.random
crypto.getRandomValues 和 Math.random 都是 JavaScript 中生成随机数的方法,但它们有显著的区别,尤其在随机数的质量和安全性方面。
crypto.getRandomValues
crypto.getRandomValues 是 JavaScript 中的一个安全随机数生成器,它是加密安全的随机数生成器,适用于需要高质量随机数的场景。
使用示例:
const array = new Uint32Array(1);
window.crypto.getRandomValues(array);
console.log(array[0]); // 生成一个随机的32位整数
Math.random
Math.random 是 JavaScript 中的一个基本随机数生成器,生成的随机数在 0 和 1 之间,适用于一般的随机数生成场景。
使用示例:
const randomNum = Math.random();
console.log(randomNum); // 生成一个 0 到 1 之间的随机数
主要区别:
- 安全性:
crypto.getRandomValues是加密安全的,适用于需要高安全性要求的场景。Math.random不是加密安全的,不适用于需要高安全性要求的场景。
- 随机性:
crypto.getRandomValues生成的随机数质量高,随机性强。Math.random生成的随机数质量一般,随机性较低。
- 适用场景:
crypto.getRandomValues适用于加密、身份验证、生成安全令牌等需要高质量随机数的场景。Math.random适用于一般的随机数生成场景,如随机选择、生成随机颜色等。
选择指南:
- 需要高安全性和高质量随机数: 使用
crypto.getRandomValues。 - 一般随机数生成: 使用
Math.random。
例子对比:
生成一个随机的 32 位整数:
- 使用
crypto.getRandomValues:
const array = new Uint32Array(1);
window.crypto.getRandomValues(array);
console.log(array[0]); // 生成一个随机的32位整数
- 使用
Math.random:
const randomNum = Math.floor(Math.random() * Math.pow(2, 32));
console.log(randomNum); // 生成一个随机的32位整数
总结来说,crypto.getRandomValues 是生成高安全性随机数的首选,而 Math.random 适用于一般的随机数生成场景。
V8引擎
https://juejin.cn/post/6844904186165870606